
CodeBot Wiki 是一款基于大语言模型的智能文档生成工具,能够自动解析项目代码,生成结构清晰、内容专业的项目 Wiki。它不仅覆盖项目概览、核心模块、关键逻辑等信息,还支持交互式理解,更适合团队协作与持续迭代,是理解开源项目或内部系统的理想助手!

解读项目地址:https://github.com/NanmiCoder/MediaCrawler
存储模块
简介
存储模块为快手、百度贴吧、小红书等平台的数据采集系统提供统一的数据持久化解决方案。通过抽象基类AbstractStore和工厂模式实现多存储后端支持(CSV/JSON/SQLite/数据库),包含内容、评论、创作者、图片等数据类型的存储逻辑。模块设计遵循异步处理原则,通过AsyncMysqlDB/AsyncSqliteDB实现并发安全操作,支持批量更新和增量更新两种模式。
核心架构
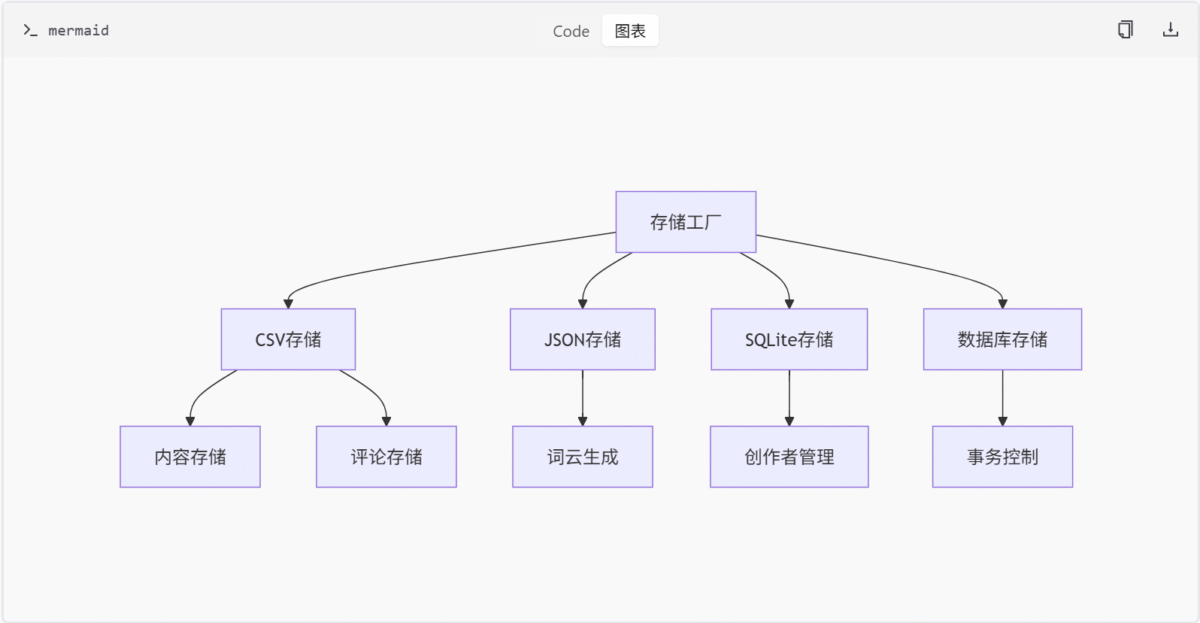
平台存储实现
快手平台
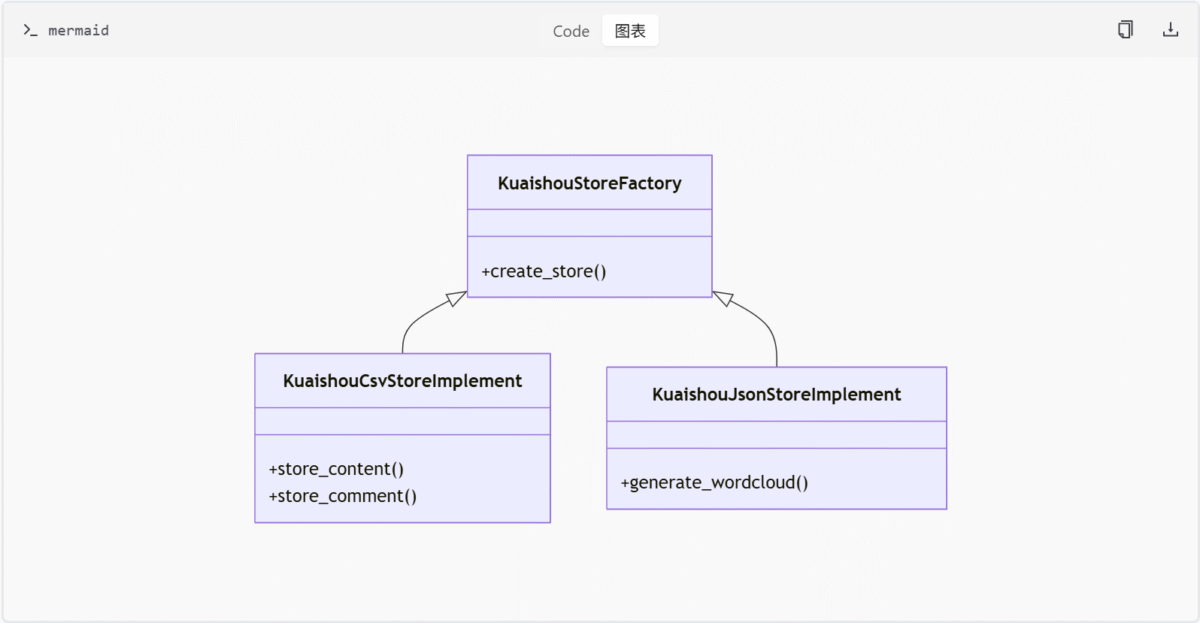
贴吧平台
| 存储类型 | 类名 | 特性 |
|---|---|---|
| CSV | TieBaCsvStoreImplement | 文件名自增防覆盖 |
| JSON | TieBaJsonStoreImplement | 支持并发写入 |
| SQLite | TieBaSqliteStoreImplement | 本地事务支持 |
| 数据库 | TieBaDbStoreImplement | 支持MySQL/PostgreSQL |
小红书平台
# store/xhs/xhs_store_sql.py
async def update_xhs_note(note_data):
content_id = note_data.get('content_id')
if not content_id:
return
existing = await query_content_by_content_id(content_id)
if existing:
await update_content_by_content_id(content_id, note_data)
else:
await add_new_content(note_data)知乎平台
工厂类与核心功能
store/zhihu/__init__.py定义了ZhihuStoreFactory,支持批量更新和单条更新操作:
class ZhihuStoreFactory:
def batch_update_zhihu_contents(contents):
# 批量更新内容
def batch_update_zhihu_note_comments(comments):
# 批量更新评论
def update_zhihu_content(content):
# 单条内容更新
def update_zhihu_content_comment(comment):
# 单条评论更新
def save_creator(creator_data):
# 存储创作者信息存储实现类
store/zhihu/zhihu_store_impl.py实现了三种存储方式:
| 实现类型 | 类名 | 特性 |
|---|---|---|
| CSV | ZhihuCsvStoreImplement | 异步写入内容/评论/作者 |
| JSON | ZhihuJsonStoreImplement | 支持词云生成与线程安全 |
| SQLite | ZhihuSqliteStoreImplement | 支持事务性CRUD操作 |
数据库交互层
store/zhihu/zhihu_store_sql.py提供完整的数据库操作接口:
async def query_content_by_content_id(content_id):
# 查询内容记录
async def add_new_content(data):
# 新增内容记录
async def update_content_by_content_id(content_id, data):
# 更新内容记录
async def query_comment_by_comment_id(comment_id):
# 查询评论记录
async def add_new_comment(data):
# 新增评论记录
async def update_comment_by_comment_id(comment_id, data):
# 更新评论记录
async def query_creator_by_user_id(user_id):
# 查询创作者记录
async def add_new_creator(data):
# 新增创作者记录
async def update_creator_by_user_id(user_id, data):
# 更新创作者记录微博平台
工厂类与核心功能
store/weibo/__init__.py定义了WeibostoreFactory,支持多种存储方式:
class WeibostoreFactory:
def batch_update_weibo_notes(notes):
# 批量更新微博笔记
def update_weibo_note(note):
# 单条微博笔记更新
def batch_update_weibo_note_comments(comments):
# 批量更新评论
def update_weibo_note_comment(comment):
# 单条评论更新
def update_weibo_note_image(image_data):
# 保存微博图片
def save_creator(creator_data):
# 存储创作者信息存储实现类
store/weibo/weibo_store_impl.py实现了四种存储方式:
| 实现类型 | 类名 | 特性 |
|---|---|---|
| CSV | WeiboCsvStoreImplement | 异步写入内容/评论/作者 |
| JSON | WeiboJsonStoreImplement | 支持并发写入 |
| SQLite | WeiboSqliteStoreImplement | 本地事务支持 |
| 数据库 | WeiboDbStoreImplement | 支持MySQL/PostgreSQL |
图片存储
store/weibo/weibo_store_image.py实现异步图片存储:
# store/weibo/weibo_store_image.py
async def store_image(self, image_data):
file_name = self.make_save_file_name()
file_path = os.path.join(self.image_store_path, file_name)
async with aiofiles.open(file_path, 'wb') as f:
await f.write(image_data)其中image_store_path固定为data/weibo/images,make_save_file_name()生成带时间戳的唯一文件名。
SQL操作接口
store/weibo/weibo_store_sql.py提供标准数据库操作:
async def query_content_by_content_id(content_id):
# 查询微博内容记录
async def add_new_content(data):
# 新增微博内容记录
async def update_content_by_content_id(content_id, data):
# 更新微博内容记录抖音平台
工厂类与核心功能
store/douyin/__init__.py定义了DouyinStoreFactory,支持多种存储方式:
class DouyinStoreFactory:
def batch_update_douyin_notes(notes):
# 批量更新抖音笔记
def update_douyin_note(note):
# 单条抖音笔记更新
def batch_update_douyin_note_comments(comments):
# 批量更新评论
def update_douyin_note_comment(comment):
# 单条评论更新
def save_creator(creator_data):
# 存储创作者信息存储实现类
store/douyin/douyin_store_impl.py实现了四种存储方式:
| 实现类型 | 类名 | 特性 |
|---|---|---|
| CSV | DouyinCsvStoreImplement | 异步写入内容/评论/作者 |
| JSON | DouyinJsonStoreImplement | 支持词云生成与线程安全 |
| SQLite | DouyinSqliteStoreImplement | 支持事务性CRUD操作 |
| 数据库 | DouyinDbStoreImplement | 支持MySQL/PostgreSQL |
数据库交互层
store/douyin/douyin_store_sql.py提供完整的数据库操作接口:
async def query_content_by_content_id(content_id):
# 查询内容记录
async def add_new_content(data):
# 新增内容记录
async def update_content_by_content_id(content_id, data):
# 更新内容记录
async def query_comment_by_comment_id(comment_id):
# 查询评论记录
async def add_new_comment(data):
# 新增评论记录
async def update_comment_by_comment_id(comment_id, data):
# 更新评论记录
async def query_creator_by_user_id(user_id):
# 查询创作者记录
async def add_new_creator(data):
# 新增创作者记录
async def update_creator_by_user_id(user_id, data):
# 更新创作者记录B站平台
工厂类与核心功能
store/bilibili/__init__.py定义了BiliStoreFactory,支持多种存储方式:
class BiliStoreFactory:
def batch_update_bilibili_videos(videos):
# 批量更新视频
def update_bilibili_video(video):
# 单条视频更新
def batch_update_bilibili_video_comments(comments):
# 批量更新评论
def update_bilibili_video_comment(comment):
# 单条评论更新
def update_bilibili_up_info(up_info):
# 更新UP主信息
def store_video(video_data):
# 存储视频文件存储实现类
store/bilibili/bilibili_store_impl.py实现了三种存储方式:
| 实现类型 | 类名 | 特性 |
|---|---|---|
| CSV | BiliCsvStoreImplement | 按时间顺序命名防覆盖 |
| SQLite | BiliSqliteStoreImplement | 支持事务性CRUD操作 |
| JSON | BiliJsonStoreImplement | 支持并发写入与词云生成 |
SQL操作接口
store/bilibili/bilibili_store_sql.py提供异步SQL操作接口:
async def query_video_by_aid(aid):
# 查询视频记录
async def add_new_video(data):
# 新增视频记录
async def update_video_by_aid(aid, data):
# 更新视频记录
async def query_follower_relation(user_id, follower_id):
# 查询粉丝关系
async def add_new_follower_relation(user_id, follower_id):
# 新增粉丝关系视频存储
store/bilibili/bilibilli_store_video.py实现异步视频存储:
# store/bilibili/bilibilli_store_video.py
class BilibiliVideo(AbstractStoreImage):
video_store_path = "data/bilibili/videos"
async def store_video(self, video_content_item):
file_path = self.make_save_file_name(video_content_item)
await self.save_video(video_content_item, file_path)
def make_save_file_name(self, item):
aid = item.get('aid')
ext = item.get('file_ext', '.mp4')
return f"{aid}{ext}"
async def save_video(self, item, file_path):
os.makedirs(os.path.dirname(file_path), exist_ok=True)
async with aiofiles.open(file_path, 'wb') as f:
await f.write(item['video_data'])
logger.info(f"Saved video to {file_path}")核心功能组件
存储工厂模式
| 平台 | 工厂类 | 配置参数 |
|---|---|---|
| 快手 | KuaishouStoreFactory | config.SAVE_DATA_OPTION |
| 贴吧 | TieBaStoreFactory | config.STORAGE_TYPE |
| 小红书 | XhsStoreFactory | config.DATA_STORE_MODE |
| 知乎 | ZhihuStoreFactory | config.ZHIHU_STORAGE |
| 微博 | WeibostoreFactory | config.SAVE_DATA_OPTION |
| 抖音 | DouyinStoreFactory | config.DOUYIN_STORAGE |
| B站 | BiliStoreFactory | config.BILIBILI_STORAGE |
异步处理机制
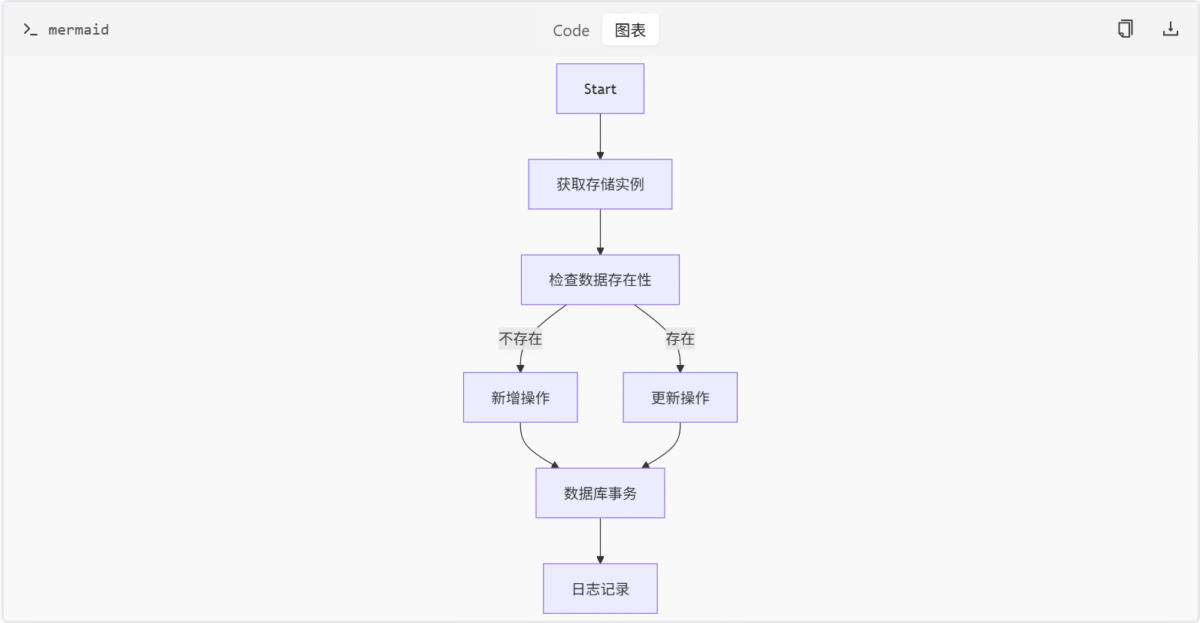
通用存储接口
| 方法名 | 参数类型 | 描述 |
|---|---|---|
| store_content | Dict[str, Any] | 存储内容数据 |
| store_comment | Dict[str, Any] | 存储评论数据 |
| store_creator | Dict[str, Any] | 存储创作者信息 |
| batch_update_comments | List[Dict], content_id | 批量更新评论 |
数据模型
快手内容表
| 字段名 | 类型 | 约束 | 描述 |
|---|---|---|---|
| content_id | VARCHAR(64) | PRIMARY KEY | 视频唯一标识 |
| title | TEXT | NOT NULL | 视频标题 |
| like_count | INT | DEFAULT 0 | 点赞数 |
| create_time | DATETIME | 创建时间戳 |
小红书创作者表
CREATE TABLE xhs_creator (
user_id VARCHAR(32) PRIMARY KEY,
nickname VARCHAR(64),
gender TINYINT,
follower_count INT,
following_count INT,
add_ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)执行流程
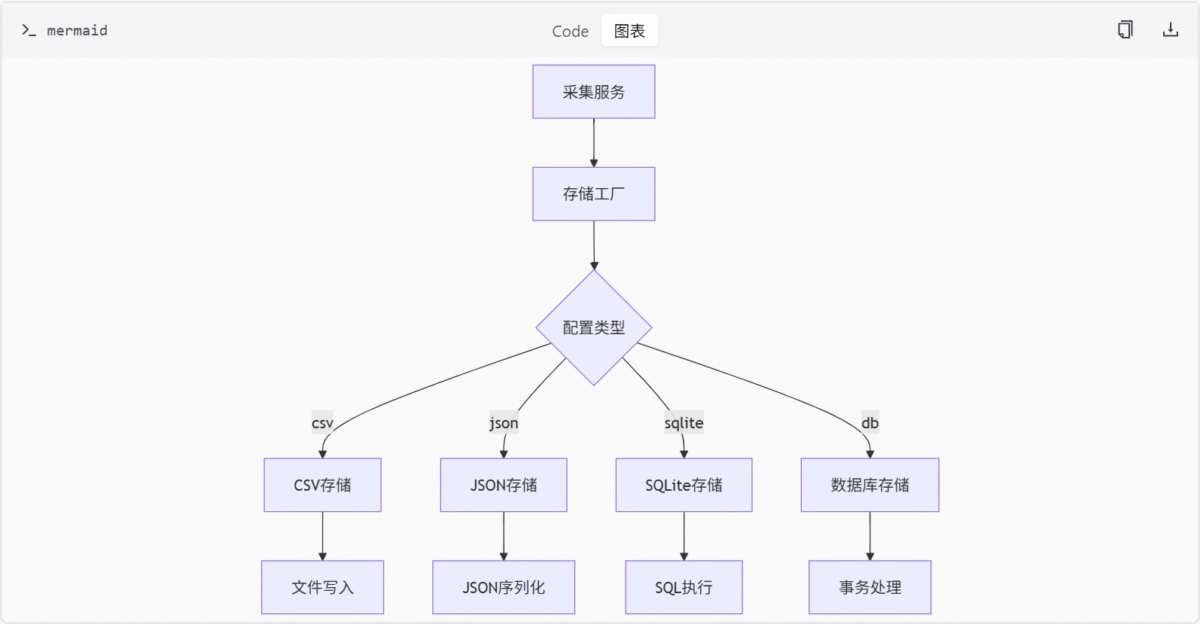
特殊功能
词云生成功能
# store/kuaishou/kuaishou_store_impl.py
async def generate_wordcloud(self, comments):
if not config.ENABLE_WORDCLOUD:
return
text = ' '.join([c['content'] for c in comments])
wordcloud = WordCloud(width=800, height=400).generate(text)
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig(f"wordcloud_{utils.get_current_timestamp()}.png")图片存储
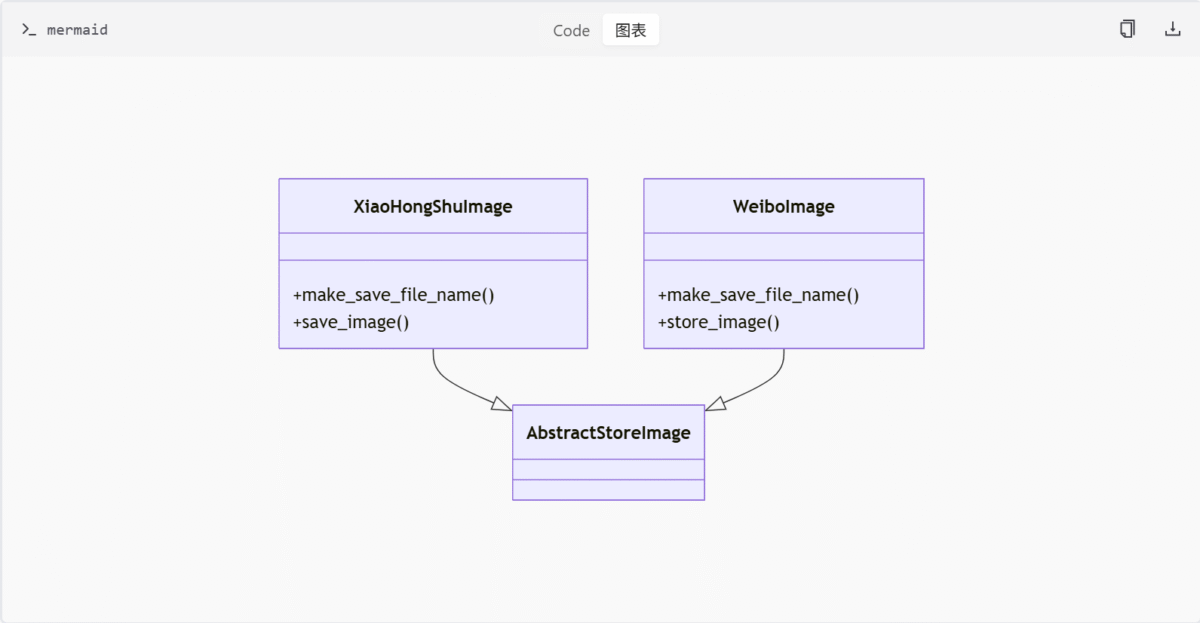
视频存储
B站视频存储通过BilibiliVideo类实现,支持异步写入和路径管理:
# store/bilibili/bilibilli_store_video.py
class BilibiliVideo(AbstractStoreImage):
video_store_path = "data/bilibili/videos"
async def store_video(self, video_content_item):
file_path = self.make_save_file_name(video_content_item)
await self.save_video(video_content_item, file_path)
def make_save_file_name(self, item):
aid = item.get('aid')
ext = item.get('file_ext', '.mp4')
return f"{aid}{ext}"
async def save_video(self, item, file_path):
os.makedirs(os.path.dirname(file_path), exist_ok=True)
async with aiofiles.open(file_path, 'wb') as f:
await f.write(item['video_data'])
logger.info(f"Saved video to {file_path}")异步锁机制
在TieBaJsonStoreImplement和KuaishouJsonStoreImplement中,通过asyncio.Lock实现文件级写入锁:
# store/tieba/tieba_store_impl.py
class TieBaJsonStoreImplement(AbstractStore):
def __init__(self):
self._lock = asyncio.Lock()
async def store_content(self, content_data):
async with self._lock:
# 写入JSON文件逻辑该机制确保同一时间只有一个协程可操作目标文件,避免JSON格式损坏或数据覆盖。
增量更新策略
以小红书内容存储为例,通过query_content_by_content_id判断记录是否存在:
# store/xhs/xhs_store_sql.py
async def update_xhs_note(note_data):
content_id = note_data.get('content_id')
existing = await query_content_by_content_id(content_id)
if existing:
await update_content_by_content_id(content_id, note_data)
else:
await add_new_content(note_data)此模式在快手、贴吧的评论/内容存储中普遍存在,通过SELECT语句实现幂等性操作。
平台特定差异
- 快手CSV存储:通过计算目录下最大文件编号生成新文件名,避免并发写入冲突。
- 贴吧SQLite存储:依赖数据库事务(
BEGIN EXCLUSIVE)而非应用层锁,通过PRAGMA synchronous=FULL确保持久化。 - 小红书图片存储:
XiaoHongShuImage.save_image直接使用文件系统原子写入(os.rename),规避并发问题。 - 知乎JSON存储:通过
asyncio.Lock实现线程安全的JSON写入,支持词云生成功能。 - 微博图片存储:使用
aiofiles实现异步文件写入,通过make_save_file_name()生成带时间戳的唯一文件名。 - 抖音CSV存储:通过文件名自增策略防覆盖,支持异步写入。
- 抖音JSON存储:支持词云生成功能,通过
asyncio.Lock实现线程安全。 - B站CSV存储:按时间顺序命名文件,避免覆盖。
- B站JSON存储:支持并发写入,启用词云时调用
AsyncWordCloudGenerator。
数据库事务与文件系统原子操作的可靠性对比
SQLite的事务控制
贴吧平台的SQLite存储使用BEGIN EXCLUSIVE事务来保证数据一致性:
# store/tieba/tieba_store_sql.py
async def update_content_by_content_id(content_id, data):
async with AsyncSqliteDB() as db:
await db.execute("BEGIN EXCLUSIVE")
await db.execute("UPDATE tieba_note SET ... WHERE content_id = ?", (content_id,))
await db.execute("COMMIT")该事务模式确保在写入过程中其他协程无法修改相同的数据,从而防止数据冲突。
文件系统原子操作
小红书的图片存储使用os.rename实现原子写入:
# store/xhs/xhs_store_image.py
def save_image(self, image_data, file_path):
temp_path = f"{file_path}.tmp"
with open(temp_path, 'wb') as f:
f.write(image_data)
os.rename(temp_path, file_path)os.rename在大多数操作系统中是原子操作,确保文件写入的完整性,避免部分写入导致的数据损坏。
不同存储后端的可靠性表现
| 存储类型 | 并发控制机制 | 数据一致性保障 | 崩溃恢复能力 |
|---|---|---|---|
| CSV | 文件锁 | 有限 | 低 |
| JSON | 文件锁 | 有限 | 低 |
| SQLite | 事务 | 高 | 中 |
| MySQL | 事务 | 高 | 高 |
总结
存储模块通过统一接口抽象和多实现策略,实现了跨平台数据持久化的灵活扩展。核心价值体现在:
- 支持CSV/JSON/SQLite/数据库等多种存储格式
- 提供异步并发安全操作保障
- 实现批量处理和增量更新机制
- 内置日志记录和错误处理
- 支持平台特有功能(如词云生成)
该模块作为数据采集系统的基础设施,为后续数据分析和可视化提供可靠的数据基础。
媒体平台抓取模块
简介
媒体平台抓取模块是一个面向微博、快手、抖音、百度贴吧、知乎、哔哩哔哩及小红书七大社交平台的自动化数据采集系统。该模块通过模拟浏览器行为、异步请求处理和多模式登录机制,实现了对用户动态、视频、评论等数据的高效抓取。系统采用分层架构设计,包含浏览器管理、数据采集、异常处理、登录验证等核心组件,支持CDP模式与标准模式的混合部署。
模块严格遵循目标平台的使用条款和robots.txt规则,通过代理配置、请求频率控制等机制降低反爬风险。核心功能覆盖用户认证、内容检索、数据持久化三大领域,适用于社交媒体分析、舆情监控等应用场景。
核心架构
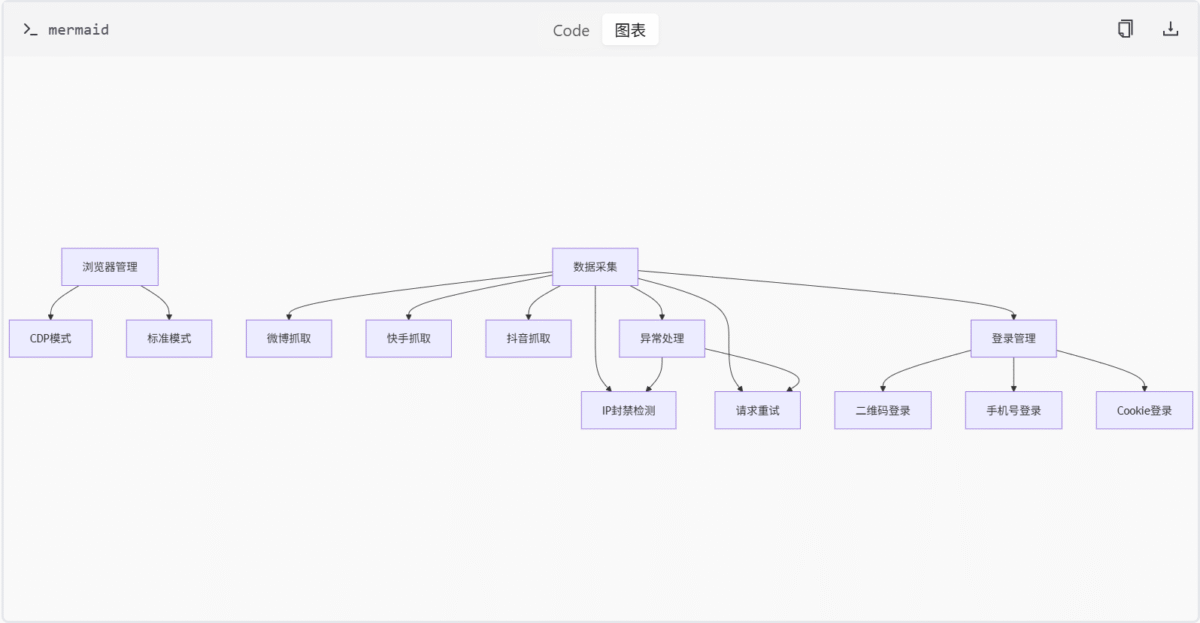
平台模块对比
| 平台 | 核心类 | 特色功能 | 登录方式 |
|---|---|---|---|
| 微博 | WeiboCrawler | 支持card_type=9卡片过滤 | 二维码/手机号/Cookie |
| 快手 | KuaishouCrawler | GraphQL查询优化 | 二维码/Cookie |
| 抖音 | DouYinCrawler | a_bogus参数生成 | 二维码/滑块验证/Cookie |
| 贴吧 | TieBaCrawler | 多维度搜索排序 | 二维码/手机号/Cookie |
| 知乎 | ZhihuCrawler | 分页机制/多内容类型抓取 | 二维码/Cookie |
| 哔哩哔哩 | BilibiliCrawler | 视频/创作者数据抓取 | 二维码/手机号/Cookie |
| 小红书 | XiaoHongShuCrawler | 支持搜索/详情/创作者模式 | 二维码/手机号/Cookie |
小红书平台抓取模块扩展
核心功能实现
客户端模块
# media_platform/xhs/client.py
class XiaoHongShuClient:
async def get_note_by_keyword(self, keyword):
"""根据关键词获取笔记"""
return await self._request("GET", "/api/note/search", params={"keyword": keyword})
async def get_note_comments(self, note_id, parent_comment_id=None):
"""获取笔记的一级评论或指定父评论下的子评论"""
params = {"note_id": note_id}
if parent_comment_id:
params["parent_comment_id"] = parent_comment_id
return await self._request("GET", "/api/comment/list", params=params)核心抓取逻辑
# media_platform/xhs/core.py
class XiaoHongShuCrawler:
async def fetch_creator_notes(self, creator_id):
"""抓取创作者的所有笔记"""
return await self.client.get_notes_by_creator(creator_id)
async def batch_get_note_details(self, note_ids):
"""批量获取笔记详情"""
tasks = [self.get_note_detail(note_id) for note_id in note_ids]
return await asyncio.gather(*tasks)登录验证模块
# media_platform/xhs/login.py
class XiaoHongShuLogin:
@retry(stop=stop_after_attempt(5))
async def login_by_phone(self, phone, code):
"""手机号验证码登录"""
await self._send_verification_code(phone)
await self._submit_login(phone, code)
if not await self.check_login_state():
raise LoginFailedError
async def check_login_state(self):
"""检查登录状态"""
cookies = self.context.cookies()
return any(cookie["name"] == "web_session" for cookie in cookies)数据结构定义
# media_platform/xhs/field.py
class FeedType(Enum):
RECOMMEND = "recommend" # 推荐内容
FASHION = "fashion" # 穿搭
FOOD = "food" # 美食
BEAUTY = "beauty" # 彩妆
MOVIE = "movie" # 影视
CAREER = "career" # 职场
EMOTION = "emotion" # 情感
HOME = "home" # 家居
GAME = "game" # 游戏
TRAVEL = "travel" # 旅行
FITNESS = "fitness" # 健身
class NoteType(Enum):
TEXT = "text" # 普通笔记
VIDEO = "video" # 视频笔记请求签名与CDN处理
# media_platform/xhs/help.py
def sign_request(params):
"""生成x-s/x-t签名"""
timestamp = str(int(time.time() * 1000))
signature = hmac.new(b'secret_key', f"{params}{timestamp}".encode(), sha256).hexdigest()
return {"x-s": signature, "x-t": timestamp}
def get_image_cdn_url(trace_id):
"""生成图片CDN地址"""
cdn_sources = ["img1.xhs", "img2.xhs", "img3.xhs"]
return f"https://{random.choice(cdn_sources)}.com/{trace_id}.jpg"异步处理机制在各平台抓取模块中的实现差异
3. 并发控制策略(新增小红书)
小红书
小红书模块通过信号量控制并发数量,并结合随机间隔时间模拟用户行为。
# media_platform/xhs/core.py
async def batch_get_note_comments(self, note_ids):
"""批量获取笔记评论"""
semaphore = asyncio.Semaphore(5)
async def bounded_get_comments(note_id):
async with semaphore:
return await self.get_note_comments(note_id)
tasks = [bounded_get_comments(note_id) for note_id in note_ids]
return await asyncio.gather(*tasks)登录验证模块扩展
平台登录方式对比(更新)
| 平台 | 支持登录方式 | 特色机制 |
|---|---|---|
| 微博 | 二维码/手机号/Cookie | STOKEN验证 |
| 快手 | 二维码/Cookie | 自动续签 |
| 抖音 | 二维码/滑块/Cookie | a_bogus加密 |
| 贴吧 | 二维码/手机号/Cookie | STOKEN+PTOKEN双验证 |
| 知乎 | 二维码/Cookie | z_c0 Cookie验证 |
| 哔哩哔哩 | 二维码/手机号/Cookie | SESSDATA Cookie验证 |
| 小红书 | 二维码/手机号/Cookie | web_session Cookie验证 |
技术约束更新(新增小红书)
- 小红书请求需携带x-s/x-t签名参数
- 小红书图片抓取需通过CDN节点访问
- 小红书默认并发数限制为5
异常处理机制扩展(新增小红书)
平台异常类型对比(更新)
| 平台 | 异常类型 | 描述 |
|---|---|---|
| 微博 | IPBlockError | 请求频率过高触发IP封禁 |
| 快手 | DataFetchError | 数据获取失败通用异常 |
| 抖音 | ForbiddenError | 访问被禁止异常 |
| 贴吧 | IPBlockError | 请求过于频繁导致封禁 |
| 知乎 | IPBlockError | IP被封禁异常 |
| 哔哩哔哩 | IPBlockError | 请求频率过高触发风控 |
| 小红书 | DataFetchError | 笔记数据获取失败异常 |
| 小红书 | IPBlockError | 请求过于频繁触发风控 |
总结
媒体平台抓取模块通过统一的架构设计实现了对微博、快手、抖音、百度贴吧、知乎、哔哩哔哩及小红书七大平台的数据采集能力,其核心价值体现在:
- 多模式浏览器兼容性
- 高效的异步处理机制
- 完善的反爬应对策略
- 模块化的设计结构
该模块为社交媒体数据分析提供了基础支撑,开发者可根据具体需求扩展新的平台适配器或增强现有功能。
代理服务模块
简介
代理服务模块为项目提供合法合规的IP代理池解决方案,主要用于数据抓取和网络请求任务。模块通过集成多个代理服务提供商(如快代理和极速HTTP代理),结合缓存机制和代理池管理,确保代理IP的高效获取与使用。所有代理服务均需遵守非商业用途、目标平台使用条款及robots协议等限制条件。
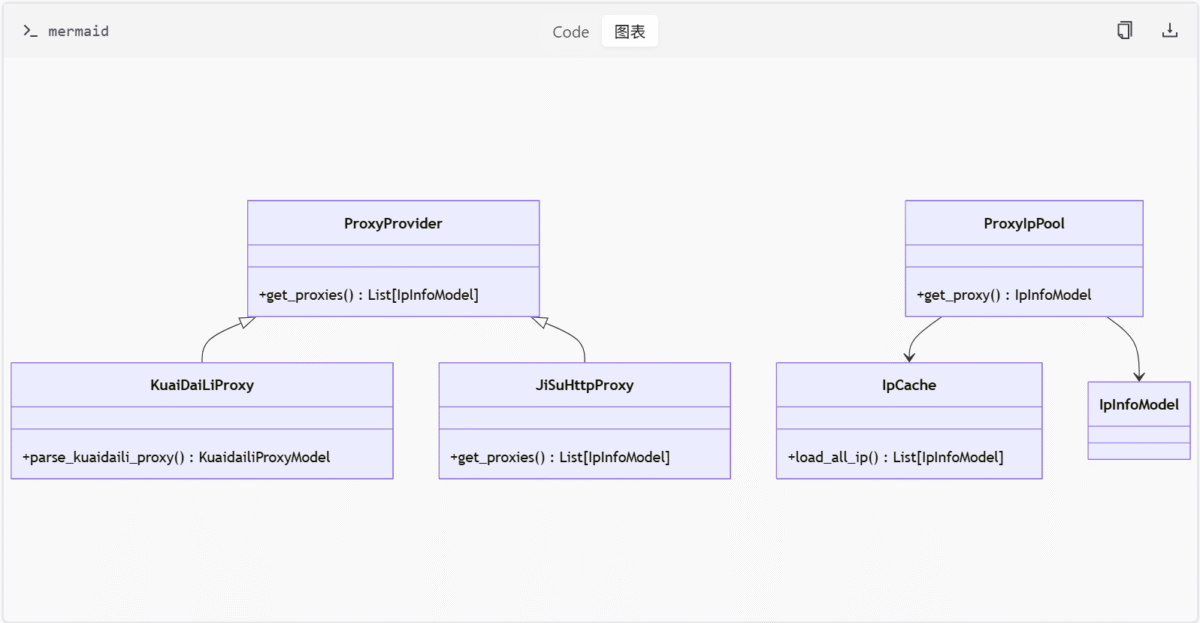
模块结构与核心组件
1. 代理提供商实现
快代理(KuaiDailiProxy)
- 功能:通过
KuaiDaiLiProxy类实现代理IP的获取与缓存管理。 - 关键方法:
parse_kuaidaili_proxy:解析代理信息字符串为KuaidailiProxyModel对象。get_proxies:从API获取指定数量的代理IP并缓存。- 配置:依赖环境变量(用户名、密码)初始化实例。
极速HTTP代理(JiSuHttpProxy)
- 功能:通过
JiSuHttpProxy类管理代理IP,但已标记为废弃。 - 关键方法:
get_proxies:异步获取代理IP,优先使用缓存。new_jisu_http_proxy:工厂函数创建实例。- 参数:需提供
key、crypto和time_validity_period。
2. IP缓存与管理
- 核心类:
IpCache(定义于base_proxy.py) - 功能:通过
AbstractCache接口管理IP有效性,自动清理过期数据。 - 方法:
load_all_ip:从Redis加载未过期的IP列表。
- 异常处理:
IpGetError用于捕获IP获取过程中的错误。
3. 代理池管理
- 核心类:
ProxyIpPool(定义于proxy_ip_pool.py) - 功能:异步加载、验证并返回有效代理IP。
- 关键方法:
load_proxies:加载指定数量的代理IP。get_proxy:随机返回有效IP,若无效则重新获取。_reload_proxies:重新加载代理池。
- 配置参数:
ip_pool_count:代理池大小。enable_validate_ip:是否启用IP有效性验证。
4. 数据模型与类型定义
- ProviderNameEnum:枚举代理提供商名称(
JISHU_HTTP_PROVIDER、KUAI_DAILI_PROVIDER)。 - IpInfoModel:Pydantic模型,定义代理IP信息字段(
ip、port、user、password等)。
Mermaid图示
类关系图
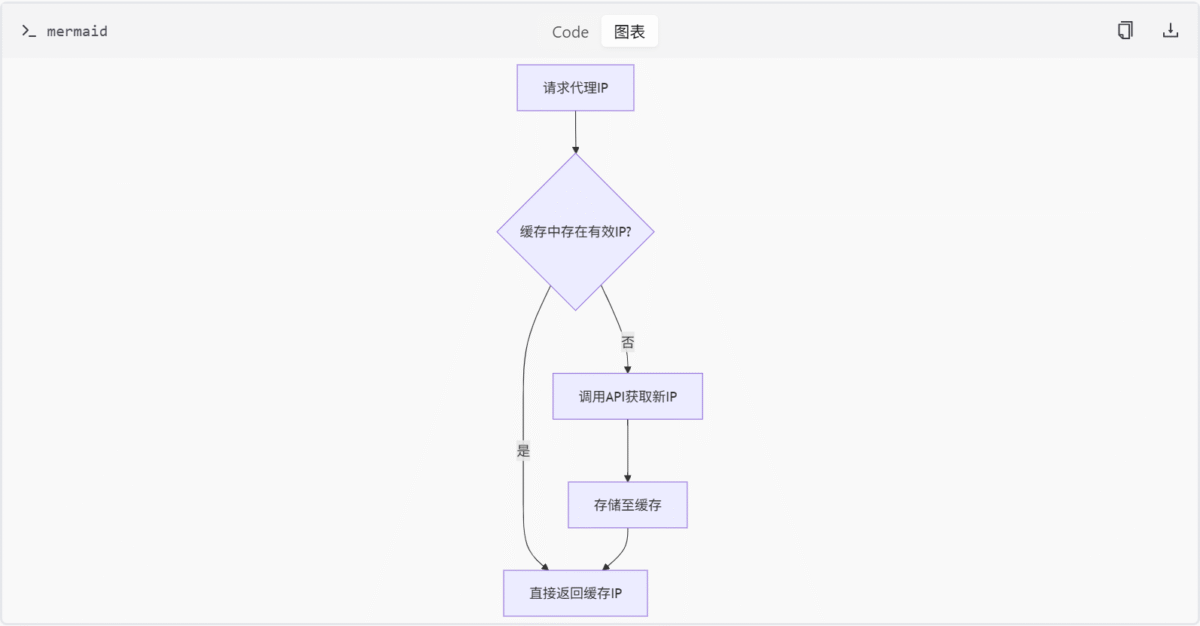
代理获取流程
功能与组件表格
| 组件/功能 | 描述 |
|---|---|
KuaiDaiLiProxy | 快代理服务实现,支持IP解析、缓存及错误处理。 |
ProxyIpPool | 代理池管理类,负责IP加载、验证及动态刷新。 |
IpCache | 缓存管理类,确保IP有效性并自动清理过期数据。 |
IpInfoModel | 代理IP信息模型,标准化IP地址、端口、认证等字段。 |
数据模型字段
| 字段名 | 类型 | 约束/描述 |
|---|---|---|
ip | str | 代理服务器IP地址 |
port | int | 代理端口号 |
user | str | 认证用户名 |
password | str | 用户密码 |
expired_time_ts | Optional[int] | 代理过期时间戳(可选) |
缓存策略实现
- 过期时间处理:
IpCache通过expired_time_ts字段判断IP有效性。 - 自动清理机制:
load_all_ip()方法会过滤已过期的IP。
代理池动态加载
- 优先级逻辑:
ProxyIpPool.get_proxy()优先从缓存获取IP,若不足则触发API调用。
错误处理与重试机制
- API调用失败处理:
KuaiDaiLiProxy在非200状态码或错误返回时抛出IpGetError。 - 重试机制:
ProxyIpPool使用tenacity库实现验证失败时的重试。
缓存是否支持自动刷新
- 结论:缓存不主动刷新,仅在请求时触发被动更新。
代理池是否限制最大IP数量
- 结论:支持通过配置限制池大小,防止内存溢出。
代理提供商的配置管理与环境变量绑定机制
- 环境变量注入:
KuaiDaiLiProxy和JiSuHttpProxy通过os.getenv读取环境变量初始化实例。 - 默认配置:未提及默认配置,需显式设置环境变量。
- 配置缺失处理:未提及具体错误处理逻辑,但可能抛出异常或记录日志。
总结
代理服务模块通过模块化设计实现了多代理提供商集成、高效缓存管理及动态代理池维护,确保项目在合法合规的前提下高效获取和使用代理IP。其核心价值在于降低外部API调用频率、提升代理可用性,并为后续扩展提供灵活的基础架构。
命令行配置模块
简介
命令行配置模块为媒体数据爬虫程序提供灵活的参数解析能力。通过argparse模块实现的命令行接口,用户可动态配置爬虫的工作模式、目标平台、登录方式及数据存储格式。该模块作为非业务模块,通过cmd_arg/__init__.py统一导出功能,确保项目其他组件能便捷调用参数解析能力。
模块设计遵循严格的使用规范,明确禁止商业用途及大规模爬取行为,要求开发者合理控制请求频率以维护目标平台稳定性。
模块结构
核心组件
| 组件 | 类型 | 功能描述 |
|---|---|---|
cmd_arg/__init__.py | 入口模块 | 导入并暴露arg子模块功能 |
cmd_arg/arg.py | 实现模块 | 定义命令行参数解析逻辑 |
参数配置体系
支持参数列表
| 参数名称 | 类型 | 描述 | 默认值 |
|---|---|---|---|
--platform | 枚举 | 目标平台(xhs/dy/ks/bili/wb/tieba/zhihu) | – |
--lt | 枚举 | 登录类型(qrcode/phone/cookie) | – |
--type | 枚举 | 爬虫类型(search/detail/creator) | – |
--start | 整数 | 起始页码 | 1 |
--keywords | 字符串 | 搜索关键词 | – |
--get_comment | 布尔 | 是否抓取一级评论 | False |
--get_sub_comment | 布尔 | 是否抓取二级评论 | False |
--save_data_option | 枚举 | 数据保存格式(csv/db/json/sqlite) | – |
--cookies | 字符串 | Cookie登录凭证 | – |
数据流与逻辑
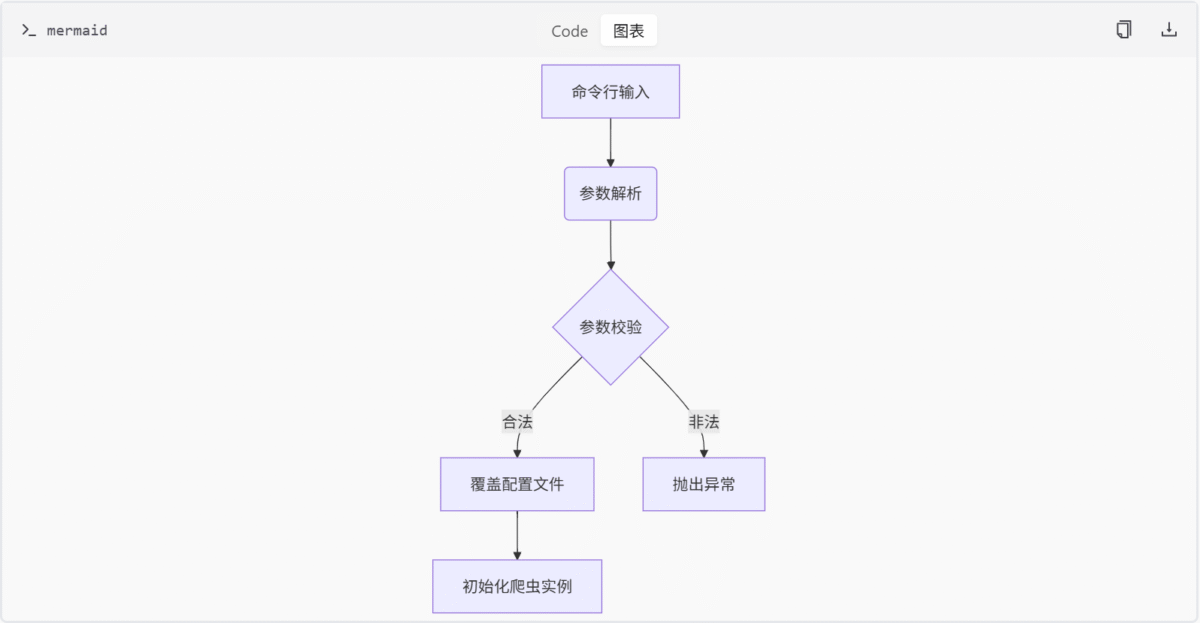
使用规范
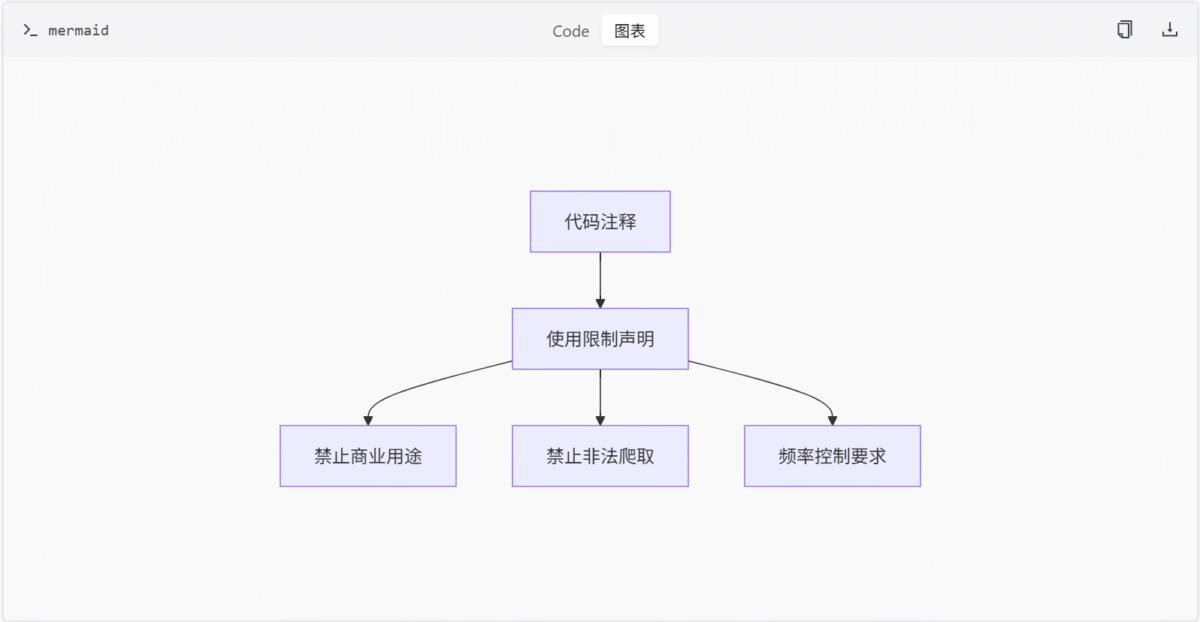
技术约束
- 非API服务模块,不涉及接口定义
- 参数解析结果直接覆盖配置文件
- 所有功能实现基于标准库
argparse
参数绑定与实现机制
在cmd_arg/arg.py中,参数通过argparse.ArgumentParser进行定义和绑定。以下为部分关键参数的实现代码:
import argparse
def parse_args():
parser = argparse.ArgumentParser(description="Media crawler configuration")
parser.add_argument('--platform', choices=['xhs', 'dy', 'ks', 'bili', 'wb', 'tieba', 'zhihu'], help='Target platform')
parser.add_argument('--lt', choices=['qrcode', 'phone', 'cookie'], help='Login type')
parser.add_argument('--type', choices=['search', 'detail', 'creator'], help='Crawler type')
parser.add_argument('--start', type=int, default=1, help='Start page number')
parser.add_argument('--keywords', type=str, help='Search keywords')
parser.add_argument('--get_comment', type=lambda x: x.lower() in ['true', '1', 't', 'y'], default=False, help='Get first-level comments')
parser.add_argument('--get_sub_comment', type=lambda x: x.lower() in ['true', '1', 't', 'y'], default=False, help='Get second-level comments')
parser.add_argument('--save_data_option', choices=['csv', 'db', 'json', 'sqlite'], help='Data saving format')
parser.add_argument('--cookies', type=str, help='Cookie login credentials')
return parser.parse_args()参数绑定模式
- 枚举值限制:通过
choices参数限制可选值范围,例如--platform支持的平台列表。 - 布尔参数处理:
--get_comment和--get_sub_comment使用自定义lambda函数将字符串转换为布尔值。 - 默认值设置:部分参数如
--start设置了默认值1,确保未指定时仍可正常运行。
合规性约束
在cmd_arg/__init__.py文件顶部包含以下注释:
# 本模块禁止用于商业用途及大规模爬取
# 要求请求频率控制在合理范围内这些注释明确了模块的使用限制,但当前代码中尚未发现与运行时验证逻辑的直接关联。合规性约束主要通过代码注释传达,依赖开发者自觉遵守。
配置覆盖机制
解析后的命令行参数会覆盖配置文件中的默认设置。这一机制确保用户可以通过命令行动态调整爬虫行为,而无需修改配置文件。例如,用户可以通过--platform dy指定抖音平台,覆盖配置文件中可能设置的默认平台。
总结
命令行配置模块通过标准化参数接口,实现了爬虫程序的灵活配置与合规管控。其设计有效平衡了功能扩展性与使用安全性,为项目提供了核心的参数管理能力。开发人员应特别注意模块注释中声明的使用限制,确保符合项目规范。
缓存模块
简介
缓存模块为项目提供统一的缓存抽象接口和多种具体实现,通过 AbstractCache 抽象基类定义标准操作规范,结合工厂模式实现灵活的缓存策略切换。该模块包含本地内存缓存和 Redis 分布式缓存两种实现,支持自动过期清理机制,适用于需要高效数据缓存的业务场景。
缓存模块的设计目标是解耦缓存接口与具体实现,提高系统的可维护性和扩展性。开发者可以通过配置选择使用本地缓存或 Redis 缓存,而无需修改业务逻辑代码。
核心架构
抽象缓存接口
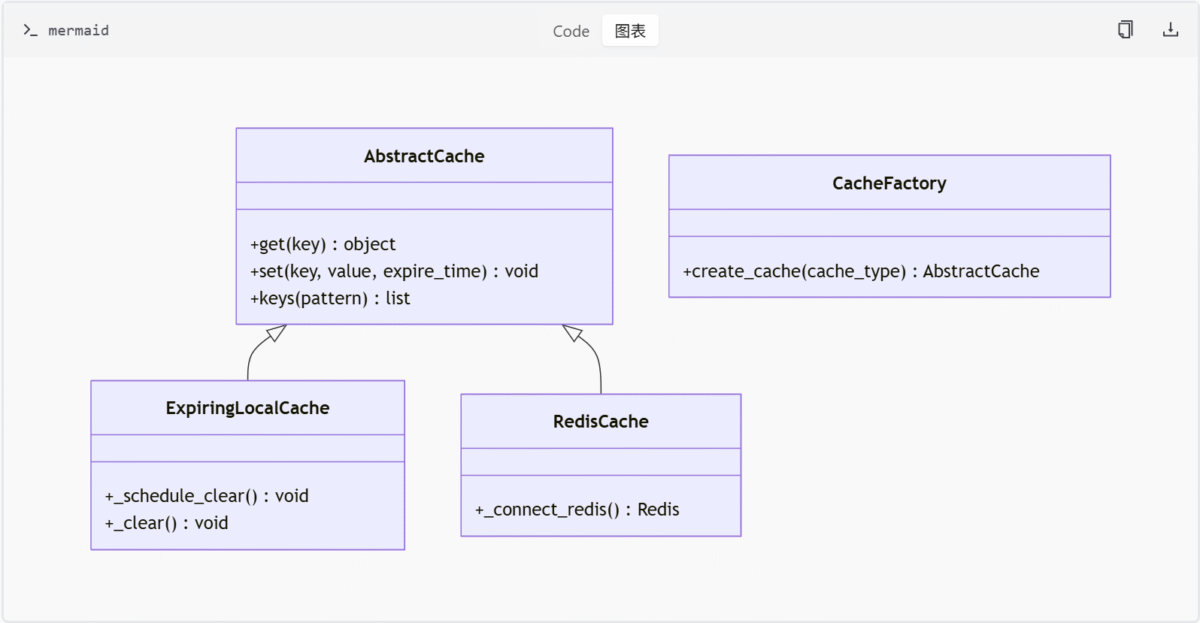
AbstractCache 是所有缓存实现的基类,定义了缓存系统的核心操作接口。
# cache/abs_cache.py
class AbstractCache:
@abstractmethod
def get(self, key):
"""获取键对应的值"""
@abstractmethod
def set(self, key, value, expire_time):
"""存储键值对并设置过期时间"""
@abstractmethod
def keys(self, pattern):
"""根据模式匹配获取键列表"""缓存工厂模式
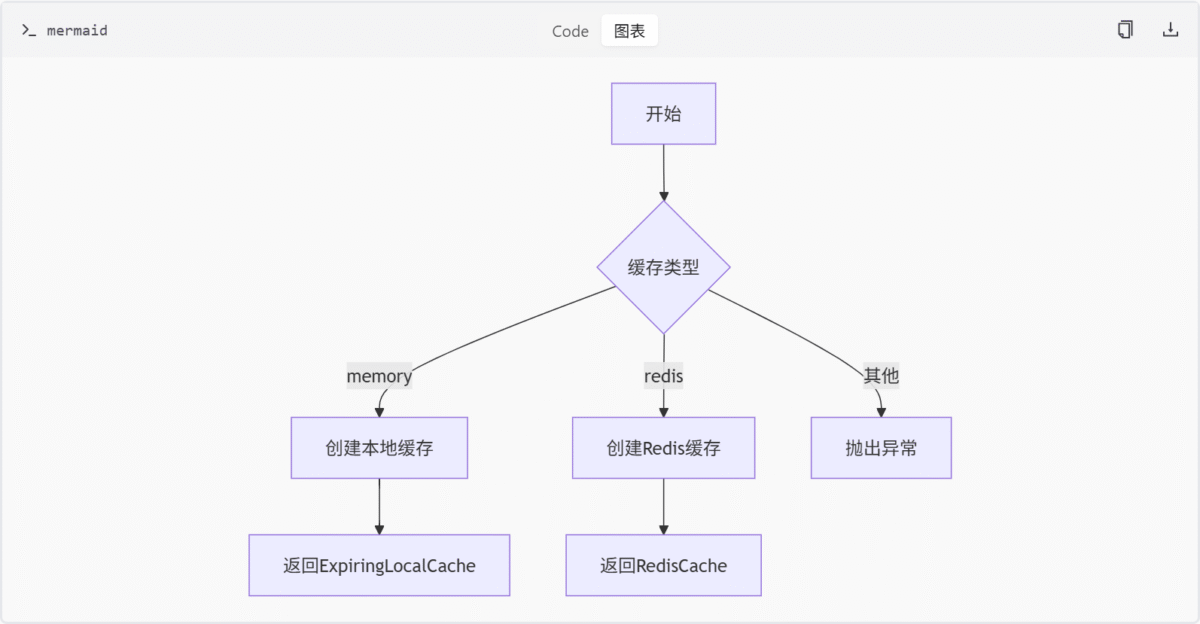
CacheFactory 提供统一的缓存实例创建接口,根据传入的缓存类型返回对应的缓存实现对象。
# cache/cache_factory.py
class CacheFactory:
@staticmethod
def create_cache(cache_type):
if cache_type == "memory":
return ExpiringLocalCache()
elif cache_type == "redis":
return RedisCache()
else:
raise ValueError("未知的缓存类型")具体实现类
缓存模块提供了两种具体的缓存实现:本地缓存和 Redis 缓存。
| 类名 | 存储类型 | 特性 |
|---|---|---|
ExpiringLocalCache | 本地内存 | 支持过期自动清理 |
RedisCache | Redis数据库 | 支持分布式存储 |
Mermaid架构图
类关系图
缓存创建流程
本地缓存实现
过期清理机制
ExpiringLocalCache 使用定时任务定期清理过期缓存项,确保内存不会被无效数据占用。
# cache/local_cache.py
def _start_clear_cron(self):
while True:
self._clear() # 清理过期项
time.sleep(CLEAR_INTERVAL)- 定时任务实现:使用无限循环 +
sleep实现定时任务,未使用线程/进程隔离,可能导致阻塞主线程(需结合调用上下文判断是否在独立线程中运行)。 - 默认清理间隔:
CLEAR_INTERVAL默认值为 60 秒,缺乏动态配置支持。 - 线程安全性:缓存容器使用普通字典,未使用锁机制,多线程环境下可能引发竞态条件。
缓存项存储结构
缓存项以元组形式存储,包含实际值和过期时间戳。
self._cache = {
key: (value, expire_time)
}过期判断逻辑
get 方法中通过比较当前时间戳与缓存项的过期时间判断是否过期。
def get(self, key):
if key in self._cache:
value, expire_time = self._cache[key]
if time.time() > expire_time:
return None
return value
return NoneRedis 缓存实现
Redis 连接配置
RedisCache 使用 Redis 客户端连接到 Redis 服务器,并通过配置文件获取连接参数。
# cache/redis_cache.py
def _connect_redis():
return redis.Redis(
host=CONFIG.REDIS_HOST,
port=CONFIG.REDIS_PORT,
db=CONFIG.REDIS_DB,
password=CONFIG.REDIS_PASSWORD
)数据存储与检索
- 存储:使用
setex方法设置键值对及其过期时间。 - 检索:使用
get方法获取键对应的值,并进行反序列化处理。
def set(self, key, value, expire_time):
serialized = self._serialize(value)
self._redis.setex(key, expire_time, serialized)
def get(self, key):
raw_value = self._redis.get(key)
if raw_value is None:
return None
return self._deserialize(raw_value)键匹配查询
keys 方法支持通配符 *,用于匹配符合条件的键。
def keys(self, pattern):
return self._redis.keys(pattern)配置参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
CLEAR_INTERVAL | int | 60 | 清理间隔(秒) |
REDIS_HOST | str | “localhost” | Redis服务器地址 |
REDIS_DEFAULT_PORT | int | 6379 | Redis默认端口 |
REDIS_DB | int | 0 | Redis数据库编号 |
REDIS_PASSWORD | str | “” | Redis密码 |
总结
缓存模块通过分层设计实现了接口与实现的解耦,开发者可通过简单配置切换不同缓存策略。本地缓存适合单机高性能场景,Redis 缓存支持分布式部署,两者均具备自动过期清理能力,有效平衡了性能与资源消耗。
本地缓存的定时清理任务存在潜在的线程阻塞风险,且缺乏动态配置支持。Redis 缓存完全依赖 Redis 本身的 TTL 机制,未在本地维护过期状态,但具备良好的分布式特性。
后续优化方向包括:
- 引入线程/异步机制隔离本地缓存的清理任务
- 增加
CLEAR_INTERVAL的动态配置支持 - 提供线程安全的缓存操作方法
工具模块
简介
工具模块是项目中的基础支撑组件集合,提供通用功能实现和业务辅助能力。该模块包含浏览器自动化控制、验证码处理、文本分析、时间处理、日志管理等核心功能,通过解耦业务逻辑与基础设施能力,提升系统可维护性和开发效率。所有工具模块均遵循非侵入式设计原则,不直接暴露 API 接口服务。
核心模块架构
浏览器管理
功能架构
关键组件
| 类/函数 | 功能描述 | 所属文件 |
|---|---|---|
BrowserLauncher | 跨平台浏览器启动器 | browser_launcher.py |
CDPBrowserManager | CDP协议浏览器控制器 | cdp_browser.py |
start_browser() | 启动浏览器主流程 | browser_launcher.py |
create_browser_context() | 创建隔离上下文 | cdp_browser.py |
浏览器启动流程
tools/browser_launcher.py 中的 start_browser() 函数负责启动浏览器。其流程如下:
- 路径检测:通过硬编码的路径列表检测浏览器安装位置。
- 端口分配:调用
_find_available_port()查找可用调试端口。 - 启动浏览器:使用 Playwright 启动浏览器进程,并设置调试端口。
- 状态监控:等待浏览器准备就绪,并返回浏览器实例。
def start_browser(self):
self.browser_path = self._detect_browser_path()
self.debug_port = self._find_available_port()
self.process = subprocess.Popen(
[self.browser_path, f'--remote-debugging-port={self.debug_port}'],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
self._wait_for_browser_ready()
return self.processCDP 浏览器管理
tools/cdp_browser.py 中的 CDPBrowserManager 类提供基于 CDP 协议的浏览器管理功能。关键方法包括:
start_browser():启动浏览器并连接到 CDP 端点。create_browser_context():创建新的浏览器上下文,支持视口大小、用户代理等配置。close():关闭浏览器上下文并释放资源。
async def start_browser(self):
self.browser = await playwright.chromium.launch(
executable_path=self.browser_path,
args=[f'--remote-debugging-port={self.debug_port}']
)
self.context = await self.browser.new_context()
return self.context浏览器生命周期管理
tools/browser_launcher.py 和 tools/cdp_browser.py 共同管理浏览器的生命周期。主要流程包括:
- 启动:通过
start_browser()启动浏览器进程。 - 上下文创建:通过
create_browser_context()创建隔离的浏览器上下文。 - 资源释放:通过
close()方法关闭浏览器上下文和进程。
def close(self):
if self.process:
self.process.terminate()
self.process.wait()
if self.browser:
await self.browser.close()验证处理
滑块验证流程
轨迹生成算法
| 函数 | 运动特性 | 适用场景 |
|---|---|---|
ease_out_quad | 二次缓出 | 简单滑块 |
ease_out_bounce | 弹跳缓出 | 复杂验证 |
get_tracks() | 多算法适配 | 动态难度 |
滑块识别与轨迹生成
tools/slider_util.py 提供了滑块识别和轨迹生成功能。关键函数包括:
discern():识别滑块在背景图片中的位置。get_tracks():生成滑块移动轨迹。
def get_tracks(distance, duration=1000, easing='ease_out_quad'):
tracks = []
for t in range(0, duration, 10):
x = eval(easing)(t / duration) * distance
tracks.append(x)
return tracks词云生成
处理流程
配置参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
max_words | int | 20 | 最大显示词数 |
font_path | str | “simhei.ttf” | 字体路径 |
mask_img | str | None | 形状模板路径 |
词云生成器
tools/words.py 中的 AsyncWordCloudGenerator 类负责生成词云图。主要步骤包括:
- 加载停用词和自定义词:从配置文件中读取停用词和自定义词。
- 数据处理:提取文本内容,去除停用词和空字符。
- 生成词频:统计词频并保存为 JSON 文件。
- 生成词云图:使用
matplotlib和wordcloud库生成词云图。
class AsyncWordCloudGenerator:
async def generate(self, text, output_path):
wordcloud = WordCloud(
font_path=self.font_path,
max_words=self.max_words,
mask=self.mask
).generate(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.savefig(output_path)时间处理
核心函数
| 函数名 | 返回类型 | 示例输出 |
|---|---|---|
get_current_timestamp() | int | 1717029200000 |
get_current_time() | str | “2024-03-15 14:33:20” |
rfc2822_to_timestamp() | int | 1710499200 |
时间处理模块
tools/time_util.py 提供多种时间处理函数,包括:
get_current_timestamp():获取当前时间戳。get_current_time():获取当前时间字符串。rfc2822_to_timestamp():将 RFC 2822 格式的时间字符串转换为 Unix 时间戳。
def get_current_timestamp():
return int(time.time() * 1000)
def rfc2822_to_timestamp(rfc_time):
return int(calendar.timegm(email.utils.parsedate(rfc_time)) * 1000)日志与参数解析
日志配置
LOG_CONFIG = {
"version": 1,
"formatters": {
"standard": {
"format": "%(asctime)s [%(levelname)s] %(name)s: %(message)s"
}
},
"handlers": {
"file": {
"class": "logging.FileHandler",
"formatter": "standard",
"filename": "media_crawler.log"
}
}
}布尔解析规则
| 输入值 | 解析结果 |
|---|---|
| “yes”/”true”/”1” | True |
| “no”/”false”/”0” | False |
| 其他 | 抛出ArgumentTypeError |
日志初始化
tools/utils.py 中的 init_logging_config() 函数负责初始化日志配置。主要步骤包括:
- 加载日志配置:从配置文件中读取日志配置。
- 设置日志记录器:创建
MediaCrawler日志记录器实例。 - 返回日志记录器:返回配置好的日志记录器实例。
def init_logging_config():
logging.config.dictConfig(LOG_CONFIG)
logger = logging.getLogger("MediaCrawler")
return logger网络工具
核心功能矩阵
| 功能 | 实现方式 | 依赖库 |
|---|---|---|
| 二维码提取 | DOM解析+HTTP下载 | Playwright |
| User-Agent生成 | 预设列表随机选择 | 无 |
| Cookies转换 | 字典/字符串双向转换 | httpx |
| HTML文本提取 | 正则表达式清洗 | 无 |
二维码提取
tools/crawler_util.py 提供了二维码提取功能。关键函数包括:
find_login_qrcode():从指定的选择器中获取登录二维码的 URL,并下载二维码图片。show_qrcode():解析 Base64 编码的二维码图像并在屏幕上显示。
def find_login_qrcode(page, selector):
qrcode_url = page.locator(selector).get_attribute("src")
response = requests.get(qrcode_url)
return base64.b64encode(response.content).decode("utf-8")合规声明
tools/__init__.py 明确规定:
- 仅限学习研究用途
- 禁止商业应用
- 遵守robots.txt规则
- 请求频率限制
- 禁止非法用途
合规声明内容
# tools/__init__.py
"""
本代码仅供学习和研究目的使用,不得用于商业用途。
使用时应遵守目标平台的使用条款和 robots.txt 规则。
避免大规模爬取或对平台造成运营干扰。
合理控制请求频率,不得用于非法或不当用途。
许可条款详见:https://example.com/license
"""总结
工具模块通过11个独立组件构建了完整的基础设施体系,覆盖浏览器自动化、数据处理、网络交互等核心场景。其设计强调模块化和可扩展性,所有组件均采用非侵入式架构,通过清晰的接口定义实现功能解耦,为上层业务逻辑提供稳定可靠的技术支撑。
加密工具模块
简介
加密工具模块为项目提供核心的加密算法实现和签名生成能力,包含抖音(douyin.js)和知乎(zhihu.js)两个独立的加密子模块。该模块通过组合SM3、RC4、MD5等基础算法,实现平台特定的签名验证逻辑,主要服务于需要数据加密和身份鉴权的业务场景。
核心子模块
抖音加密子模块(douyin.js)
架构概览
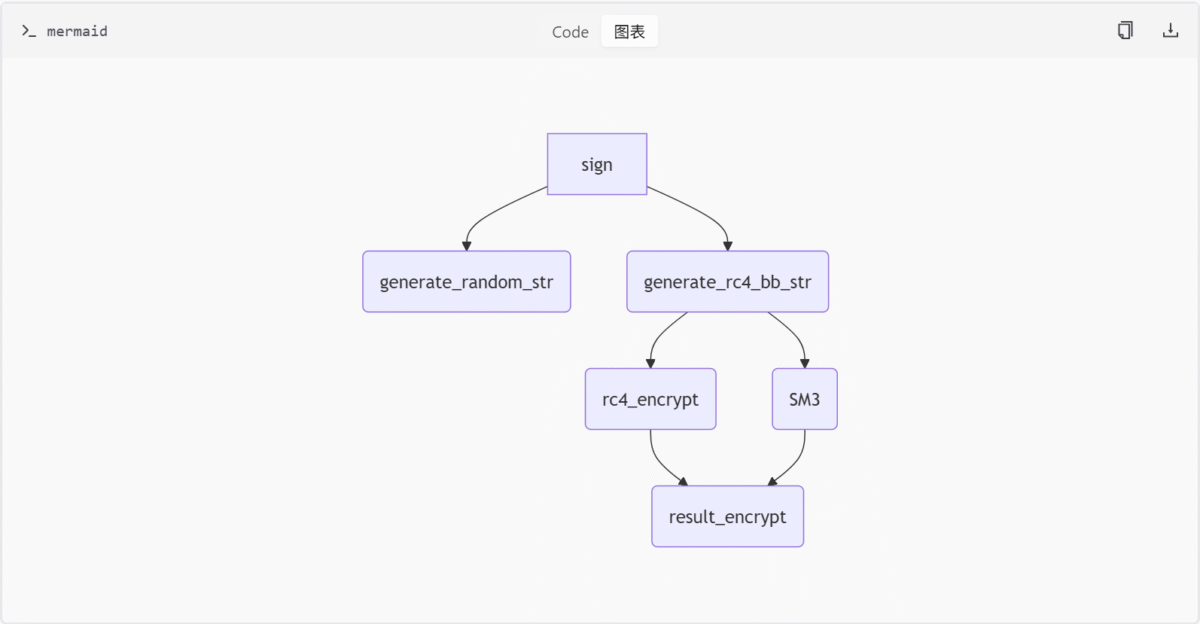
关键组件
| 组件名称 | 类型 | 功能描述 |
|---|---|---|
| SM3 | 类 | 实现国密SM3哈希算法,支持数据块处理和结果计算 |
| rc4_encrypt | 函数 | 执行RC4流加密,通过密钥生成伪随机序列进行异或运算 |
| generate_rc4_bb_str | 函数 | 综合加密引擎,生成包含时间戳/参数/配置的复合加密结构 |
| sign | 函数 | 主签名生成入口,整合随机数生成和多级加密流程 |
数据流说明
- 输入参数:
url_search_params、user_agent和业务参数 - 生成16位随机字符串
- 执行RC4加密并构建复合数据结构
- 应用SM3+RC4组合加密生成最终签名
SM3算法实现
class SM3 {
constructor() {
// 初始化常量和缓存
}
update(data) {
// 数据分块处理逻辑
}
digest() {
// 最终哈希计算
return this._hex();
}
}RC4加密流程
function rc4_encrypt(plaintext, key) {
const s = new Array(256);
for(let i=0; i<256; i++) {
s[i] = i;
}
for(let j=0, i=0; i<256; i++) {
j = (j + s[i] + key.charCodeAt(i % key.length)) % 256;
[s[i], s[j]] = [s[j], s[i]];
}
return xor_cypher(plaintext, s);
}签名生成逻辑
function sign(url_search_params, user_agent, arguments) {
const randomStr = generate_random_str();
const encryptedData = generate_rc4_bb_str(randomStr, arguments);
return result_encrypt(encryptedData, randomStr);
}知乎签名子模块(zhihu.js)
流程图示
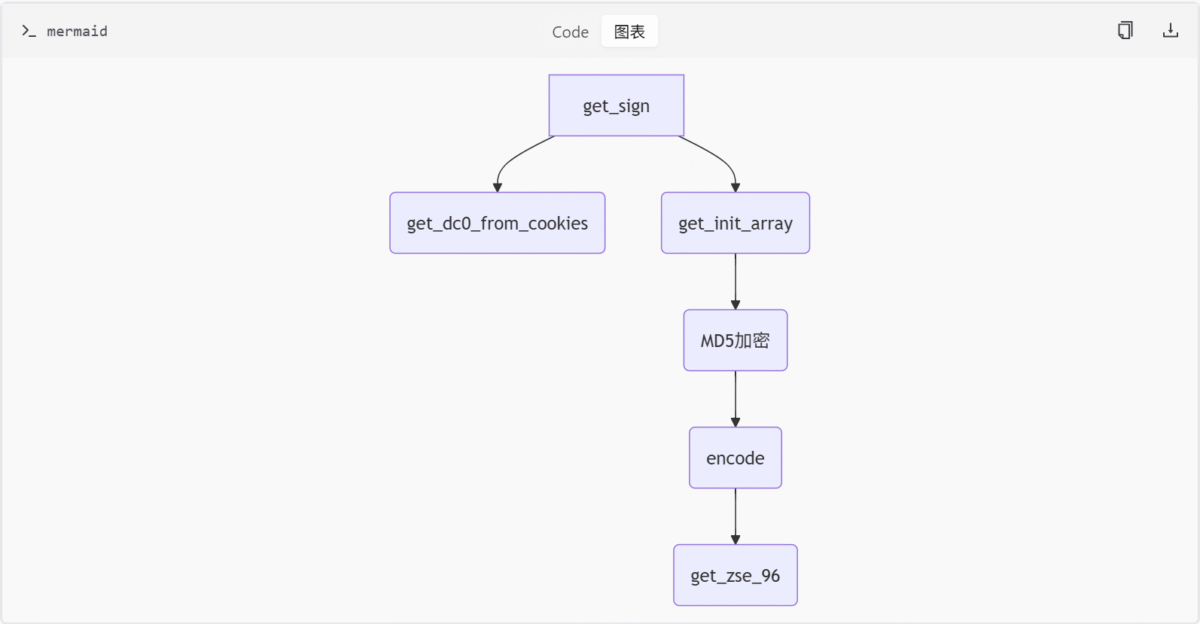
核心函数
| 函数名称 | 参数 | 返回值 | 说明 |
|---|---|---|---|
| get_sign | (url, cookies) | String | 生成x-zse-96签名头 |
| get_init_array | – | Array | 初始化签名计算所需的固定数组 |
| encode | (num) | String | 将数值转换为自定义字符编码 |
MD5加密与编码规则
const map = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
function encode(num) {
return map[num % 62]; // 基62编码变体
}签名生成逻辑
function get_sign(url, cookies) {
const dc0 = get_dc0_from_cookies(cookies);
const initArray = get_init_array();
const md5Hash = crypto.createHash('md5').update(url + dc0).digest('hex');
const encoded = encode(parseInt(md5Hash, 16));
return get_zse_96(encoded);
}技术实现对比
算法组合模式差异
| 模块 | 主算法 | 组合逻辑 | 加密层级 |
|---|---|---|---|
| 抖音 | SM3 + RC4 | RC4加密后二次SM3哈希 | 双重加密 |
| 知乎 | MD5 | 单次哈希 + 自定义编码 | 单层处理 |
随机数生成机制
- 抖音
gener_random
function gener_random(base, options) {
const seed = Date.now() ^ Math.random();
return Array.from({length: 16}, () =>
options[Math.floor(Math.abs(seed) % options.length)]
);
}- 知乎
get_init_array
function get_init_array() {
return [48, 56, 72, 24, 36, 84, 90, 12, 45, 67, 89, 10, 23, 55, 77, 33];
}参数传递模式
| 特征 | 抖音 | 知乎 |
|---|---|---|
| URL参数处理 | 通过 url_search_params 解析 | 直接作为 get_sign 输入 |
| Cookies依赖 | 未提及 | 依赖 dc0 字段提取 |
依赖关系
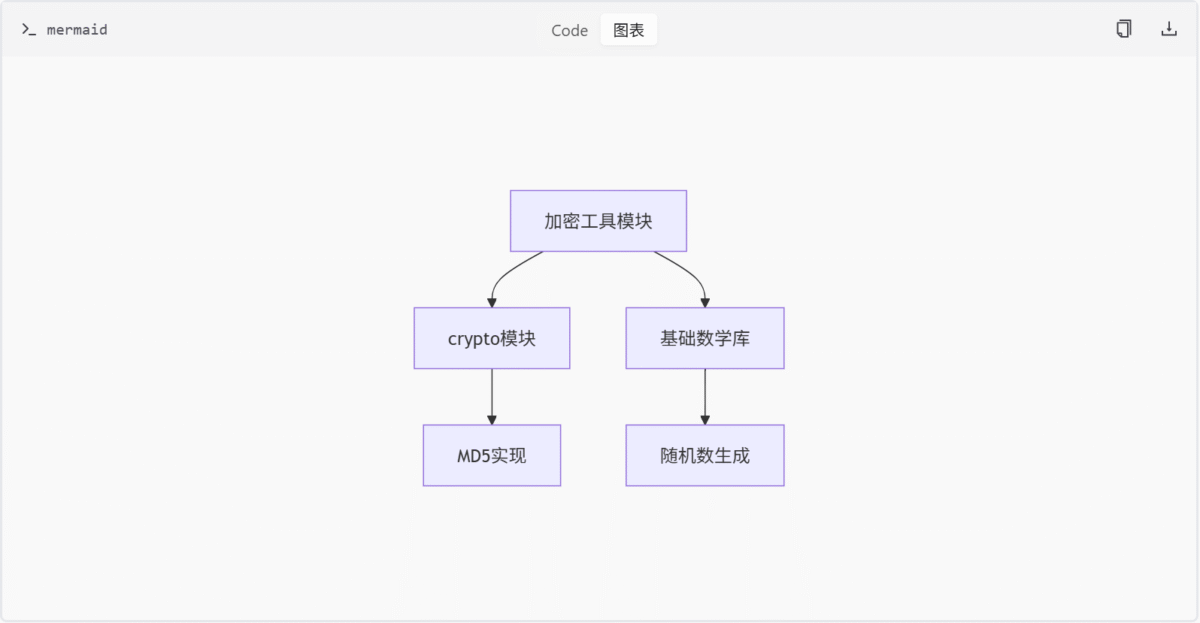
模块总结
加密工具模块通过两个独立子系统实现了平台定制化的安全需求。抖音模块采用国密算法组合确保数据安全性,知乎模块则通过MD5和自定义编码实现签名验证。两个子模块均遵循“算法封装-流程组合-接口输出”的设计模式,为上层业务提供了可复用的安全能力基座。
基础框架模块
简介
base 模块为爬虫系统提供统一的抽象基类框架,通过定义核心行为规范确保不同平台爬虫实现的一致性。该模块包含浏览器操作、登录认证、数据存储等基础功能的抽象接口,同时通过 __init__.py 明确代码使用限制和法律约束。其设计目标是通过抽象类实现功能解耦,提升代码复用性与可维护性,并在技术实现层面保障合规性。
核心抽象类
AbstractCrawler
AbstractCrawler 是爬虫系统的核心抽象类,定义了启动浏览器和执行搜索的基本行为。
class AbstractCrawler:
def start_browser(self):
"""通过Playwright启动浏览器"""
def execute_search(self, query):
"""执行搜索操作(需子类实现)"""
raise NotImplementedError该类通过 start_browser() 方法初始化浏览器环境,通常使用 Playwright 库实现。execute_search() 方法则必须由具体平台的子类实现,以适配不同网站的搜索逻辑。
登录管理
AbstractLogin 提供了多种登录方式的抽象接口,包括二维码、手机号和 Cookies 登录。
class AbstractLogin:
def login_by_qrcode(self):
"""二维码登录"""
def login_by_phone(self, phone):
"""手机号登录"""
def login_by_cookies(self, cookies):
"""Cookies登录"""该类的设计允许子类根据平台特性实现具体的登录流程,例如某些平台可能不支持二维码登录,但支持手机号或账号密码登录。
数据存储
AbstractStore 和 AbstractStoreImage 分别负责内容数据和图片数据的存储。
class AbstractStore:
def store_content(self, item):
"""存储内容项(支持XHS)"""
def store_comment(self, comment):
"""存储评论项(支持XHS)"""
def store_creator(self, creator):
"""存储创建者信息(支持XHS)"""
class AbstractStoreImage:
def store_image(self, image_data):
"""存储图片内容(支持微博)"""目前,AbstractStore 仅支持 XHS 平台,而 AbstractStoreImage 仅支持微博平台。这种设计表明存储逻辑存在平台差异,可能需要通过子类覆盖或配置参数进行扩展。
API 客户端
AbstractApiClient 提供了发送 HTTP 请求和更新 Cookies 的接口。
class AbstractApiClient:
def send_request(self, url, params):
"""发送HTTP请求"""
def update_cookies(self, new_cookies):
"""更新Cookies"""该类是爬虫与目标平台交互的核心组件,负责处理网络请求和会话状态管理。
模块初始化与法律声明
__init__.py 文件中明确声明了代码的使用限制和法律约束,包括以下关键点:
- 非商业用途:代码仅限于学习和研究,禁止用于商业目的。
- 合规要求:
- 遵守目标平台的 robots.txt 规则。
- 控制请求频率,避免对平台造成运营干扰。
- 法律依据:用户需阅读项目根目录下的 LICENSE 文件以了解详细条款。
# base/__init__.py
"""
本代码仅限于学习和研究目的,不得用于商业用途。
使用前请阅读项目根目录下的 LICENSE 文件。
遵守目标平台的使用条款和 robots.txt 规则。
禁止大规模爬取和非法用途。
"""该声明虽为注释形式,但明确了开发者和使用者的责任边界,是项目合规性的重要组成部分。
架构关系图
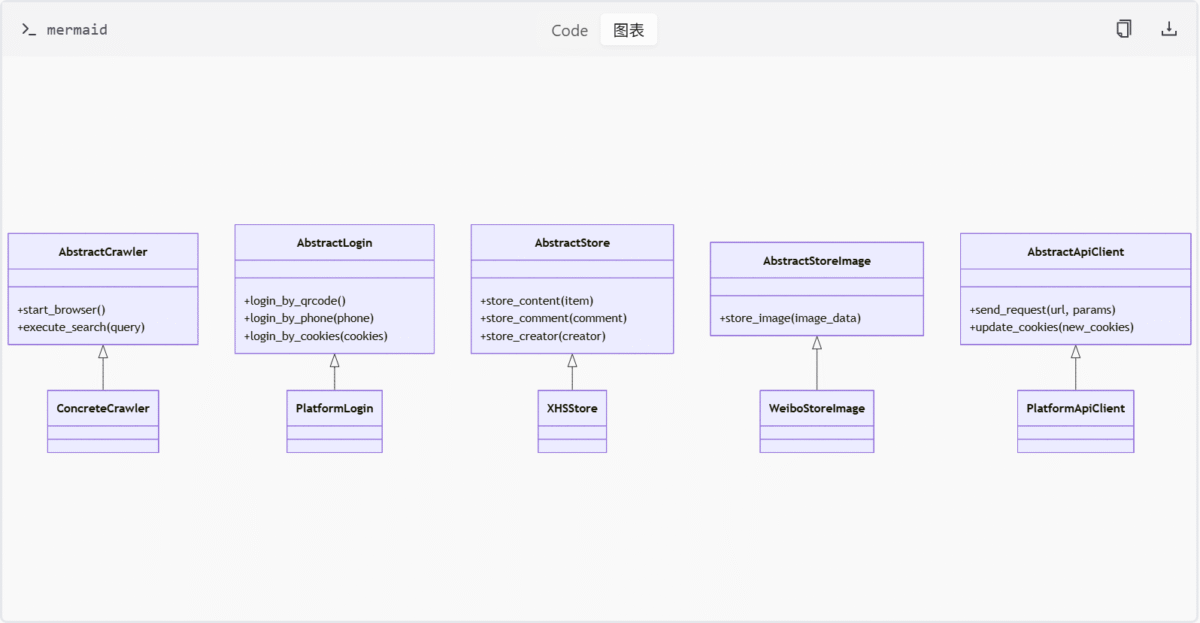
此图展示了 base 模块中抽象类与具体实现类之间的继承关系,体现了模块的可扩展性和平台适配能力。
功能组件表
| 组件名称 | 描述 | 支持平台 |
|---|---|---|
| AbstractCrawler | 爬虫基础行为定义 | 通用 |
| AbstractLogin | 多种登录方式实现 | 通用 |
| AbstractStore | 内容/评论/创建者存储 | XHS |
| AbstractStoreImage | 图片内容存储 | 微博 |
| AbstractApiClient | HTTP请求与Cookies管理 | 通用 |
抽象方法的实现约束
在 AbstractCrawler 中,execute_search(query) 方法被设计为必须由子类实现,未提供默认逻辑:
def execute_search(self, query):
"""执行搜索操作(需子类实现)"""
raise NotImplementedError此设计强制子类覆盖该方法,但未在代码中体现平台适配的条件分支,可能依赖运行时配置(如环境变量)动态选择实现。
AbstractStore 的 store_creator 方法注释明确指出 仅支持 XHS 平台:
def store_creator(self, creator):
"""存储创建者信息(当前仅支持XHS平台)"""此类硬编码限制可能通过子类覆盖解决,但当前代码未提供示例,需进一步确认具体实现中是否通过继承扩展支持其他平台。
法律声明的代码绑定缺失
尽管 __init__.py 中声明了合规性要求(如频率控制),但当前抽象类中无任何频率限制逻辑(如 time.sleep() 或速率限制器)。例如:
# base/__init__.py
"""
需合理控制请求频率,避免对平台造成运营干扰
"""当前抽象类中无任何频率限制逻辑(如 time.sleep() 或速率限制器),可能需在具体实现层(如 ConcreteCrawler)手动添加,存在合规风险。
扩展性分析
平台适配
base 模块通过抽象类设计预留了扩展点,例如:
AbstractCrawler可通过子类实现不同平台的搜索逻辑。AbstractStore和AbstractStoreImage可通过子类支持更多平台的数据存储。
新增平台支持
若需支持新平台(如抖音),开发者需:
- 创建
AbstractCrawler的子类,实现execute_search()方法。 - 创建
AbstractStore或AbstractStoreImage的子类,实现对应平台的数据存储逻辑。 - 创建
AbstractApiClient的子类,实现特定平台的 API 请求逻辑。
总结
base 模块通过抽象基类实现了爬虫系统的标准化设计,既保证了功能扩展性又明确了法律边界。其核心价值体现在:
- 提供统一的接口规范降低开发复杂度。
- 通过模块化设计支持多平台适配。
- 明确的法律声明保障项目合规性。
数据模型模块
简介
本模块通过Pydantic模型定义了多个社交平台的数据结构,包含百度贴吧、知乎、小红书等平台的内容/评论/创作者模型。模块核心功能是为数据解析和存储提供标准化的数据结构,同时包含必要的法律声明文件以确保合规性。所有模型均采用字段注解方式实现数据验证,通过Field和description保证数据可读性。
核心数据模型
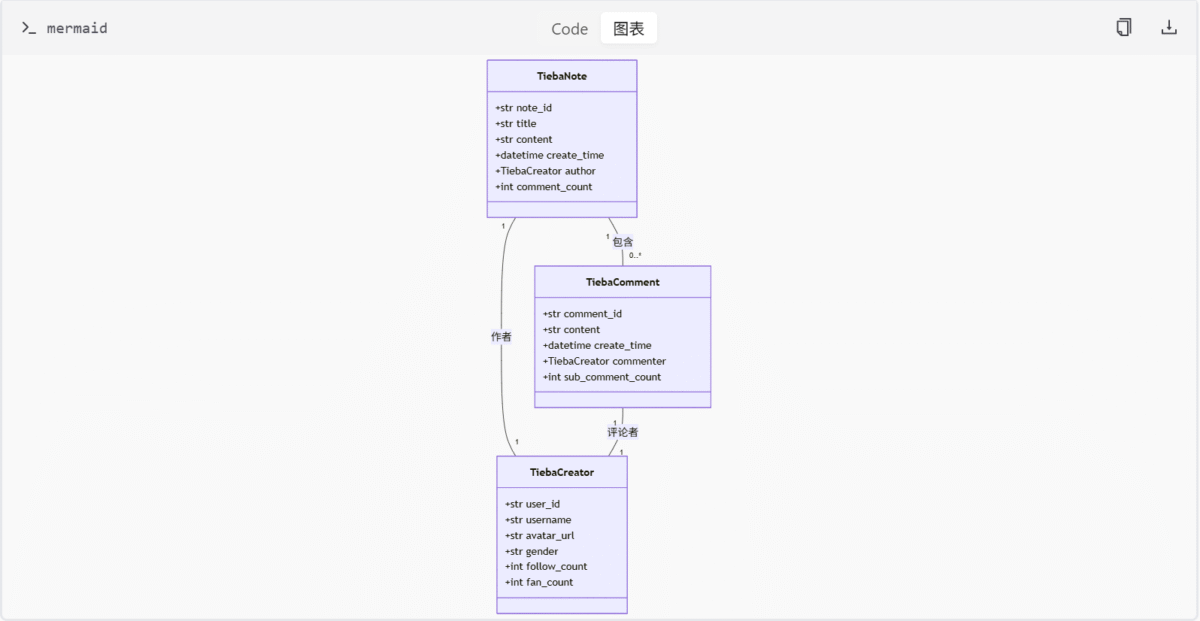
百度贴吧模型
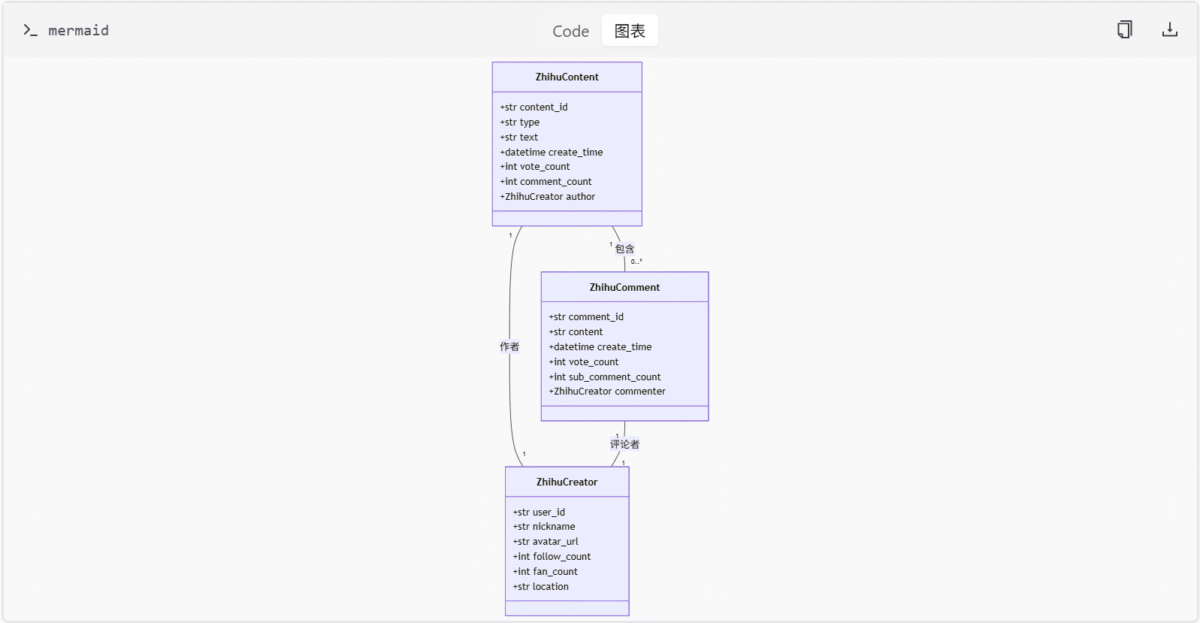
知乎模型
小红书模型

法律声明模块
| 文件路径 | 主要内容 |
|---|---|
| model/m_kuaishou.py | 快手平台数据使用限制声明 |
| model/m_weibo.py | 新浪微博合规使用条款 |
| model/m_douyin.py | 抖音平台爬取行为规范 |
| model/init.py | 模块整体使用许可说明 |
数据模型字段对照表
| 平台 | 模型类 | 关键字段 | 字段类型 | 说明 |
|---|---|---|---|---|
| 百度贴吧 | TiebaNote | note_id | str | 帖子唯一标识 |
| 百度贴吧 | TiebaNote | comment_count | int | 评论数量 |
| 知乎 | ZhihuContent | vote_count | int | 点赞数统计 |
| 小红书 | NoteUrlInfo | xsec_token | str | 安全令牌 |
模块结构
模型设计模式分析
继承结构
- 所有模型均直接继承自
BaseModel,未发现共享基类
class TiebaNote(BaseModel):
note_id: str
title: str
content: str
create_time: datetime
author: TiebaCreator字段命名规范
- 采用
snake_case命名规范,但存在跨平台差异:
平台 ID字段名 时间字段名
百度贴吧note_idcreate_time
知乎content_idcreate_time
小红书note_id无时间字段 字段规范- 必填字段:
TiebaNote类有8个必填字段(占比73%)ZhihuCreator类有5个必填字段(占比63%)- 默认值设置:仅
TiebaComment的sub_comment_count设置了默认值0 - 敏感字段:
NoteUrlInfo的xsec_token字段未标注加密处理
- IP地理位置字段:
TiebaNote包含ip_location字段,与model/m_kuaishou.py中”遵守robots.txt规则”的声明形成数据对应关系 - 频率控制字段:未发现与”请求频率控制”相关的字段定义
快手GraphQL接口模块
简介
快手GraphQL接口模块为快手媒体平台提供统一的数据访问接口,通过定义多个GraphQL查询操作,实现对评论、视频、用户资料、照片搜索等核心业务数据的结构化获取。该模块采用分页机制(pcursor)支持大规模数据处理,并通过预定义查询模板(如commentListQuery、visionVideoDetail等)规范数据请求格式,降低前端开发复杂度。所有查询均遵循业务模块设计原则,不直接暴露API服务实现细节。
核心功能架构
数据查询分类
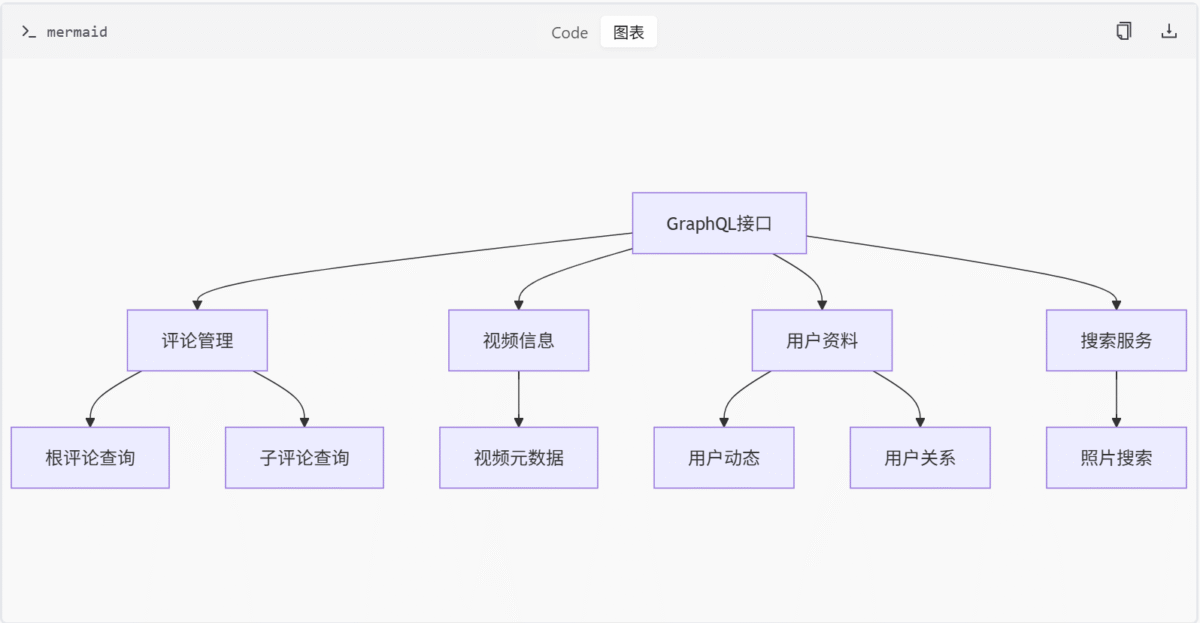
关键组件
| 组件名称 | 类型 | 功能描述 |
|---|---|---|
KuaiShouGraphQL | Python类 | 查询管理器,负责加载和检索GraphQL模板 |
commentListQuery | GraphQL查询 | 评论列表分页获取 |
visionVideoDetail | GraphQL查询 | 视频详情数据获取 |
visionProfilePhotoList | GraphQL查询 | 用户动态照片列表 |
visionSubCommentList | GraphQL mutation | 子评论列表获取 |
详细接口说明
1. 评论管理接口
根评论查询
query commentListQuery($photoId: String!, $pcursor: String) {
commentCount
pcursor
rootComments {
commentId
authorId
authorName
content
headurl
timestamp
likedCount
realLikedCount
liked
status
authorLiked
subCommentCount
subCommentsPcursor
}
subComments {
commentId
replyToUserName
replyTo
}
}参数说明:
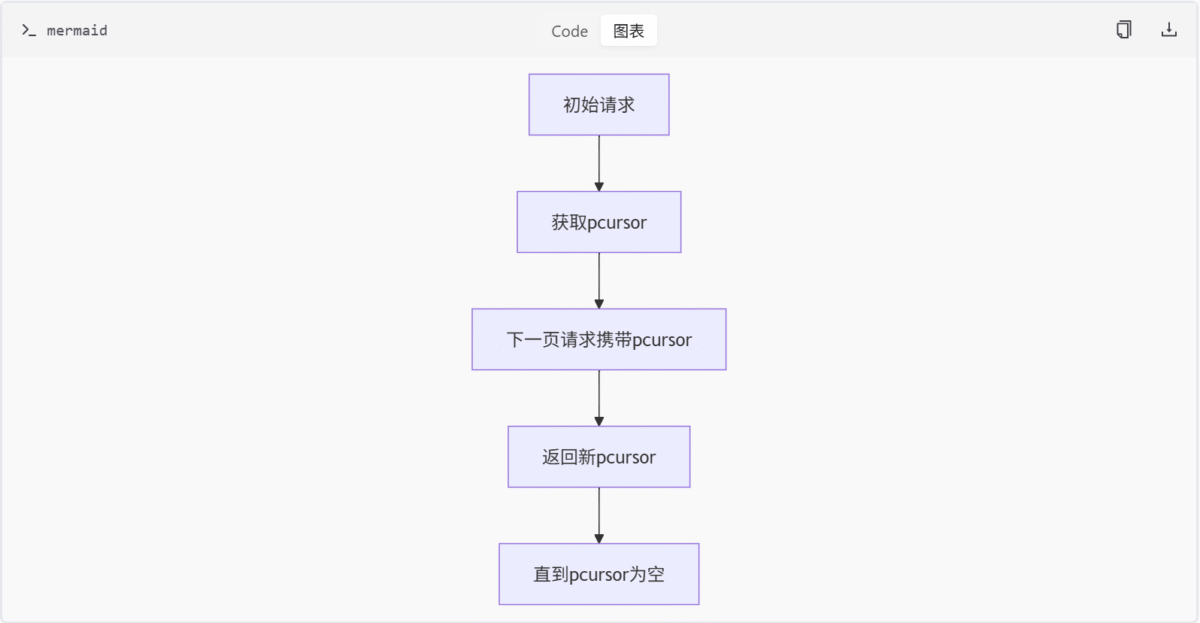
photoId: 必填,目标照片IDpcursor: 可选,用于分页的游标
返回字段说明:
commentCount: 评论总数pcursor: 下一页分页游标rootComments: 根评论列表,包含评论ID、作者信息、内容、点赞数等subComments: 子评论列表,包含回复对象信息
子评论查询
mutation visionSubCommentList($photoId: String!, $rootCommentId: String!, $pcursor: String) {
commentId
authorId
content
timestamp
likedCount
realLikedCount
replyToUserName
replyTo {
authorId
authorName
}
pcursor
}参数说明:
photoId: 必填,目标照片IDrootCommentId: 必填,根评论IDpcursor: 可选,用于分页的游标
返回字段说明:
commentId: 子评论IDauthorId: 作者IDcontent: 评论内容timestamp: 评论时间戳likedCount: 点赞数realLikedCount: 实际点赞数replyToUserName: 被回复用户名replyTo: 被回复对象信息pcursor: 下一页分页游标
2. 视频信息接口
query visionVideoDetail($photoId: String!, $type: String, $page: Int, $webPageArea: String) {
author {
userId
userName
headurl
isFollowing
}
video {
duration
title
likedCount
coverUrl
videoUrl
isLiked
timestamp
llsid
playCount
}
tags {
type
name
}
commentDisabled
danmuSwitch
}参数说明:
photoId: 必填,目标视频IDtype: 可选,类型参数(具体允许值未明确)page: 可选,分页页码webPageArea: 可选,网页区域标识
返回字段说明:
author: 作者信息,包含用户ID、用户名、头像、是否关注video: 视频信息,包含时长、标题、封面、视频URL、点赞状态、播放次数等tags: 视频标签信息commentDisabled: 是否禁用评论danmuSwitch: 弹幕开关状态
3. 用户资料接口
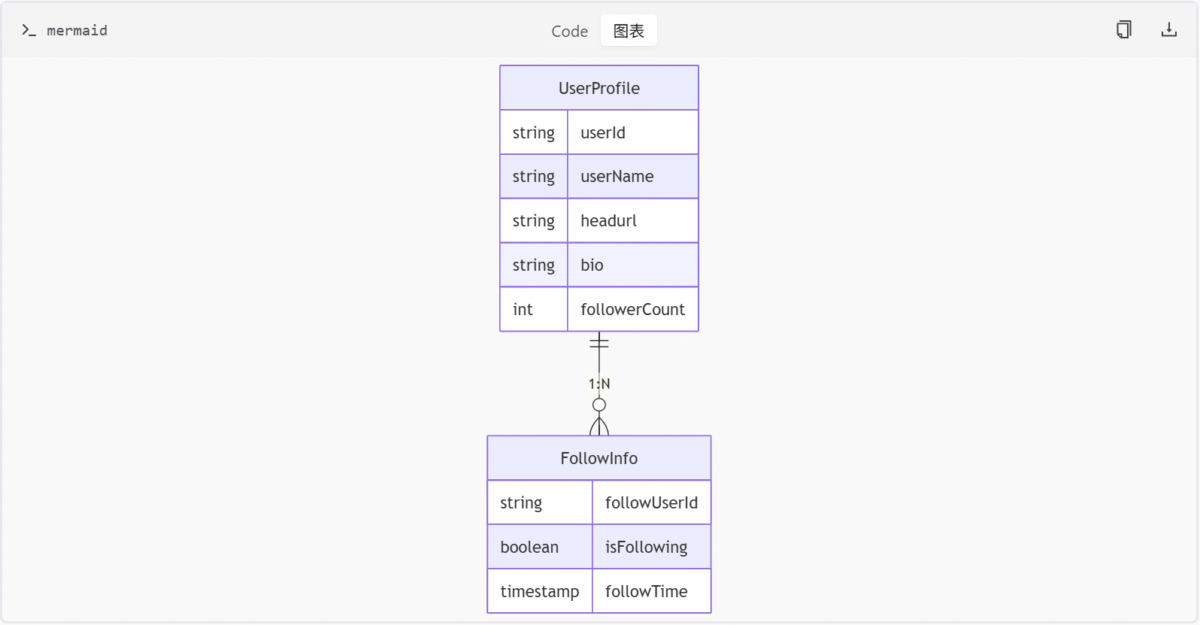
query visionProfile($userId: String!) {
result
hostName
userProfile {
ownerCount
profile {
gender
userName
userId
headurl
bio
backgroundUrl
}
isFollowing
}
__typename
}参数说明:
userId: 必填,目标用户ID
返回字段说明:
result: 查询结果状态hostName: 主机名称userProfile: 用户资料信息,包含粉丝数、性别、用户名、头像、简介等isFollowing: 当前用户是否关注目标用户
4. 搜索服务接口
query visionSearchPhoto($keyword: String!, $page: Int, $webPageArea: String) {
photoContent {
photoId
timestamp
coverUrl
videoUrl
likedCount
commentCount
}
recoPhotoFragment {
photoId
title
author {
userName
headurl
}
}
feedContent {
author {
userId
userName
}
photo {
photoId
content
}
commentPermission
}
}参数说明:
keyword: 必填,搜索关键词page: 可选,分页页码webPageArea: 可选,网页区域标识
返回字段说明:
photoContent: 搜索结果中的照片基本信息recoPhotoFragment: 推荐照片片段feedContent: Feed类型内容,包含作者信息和评论权限
数据模型规范
评论数据结构
| 字段名 | 类型 | 描述 | 约束 |
|---|---|---|---|
| commentId | String | 评论唯一标识 | 必填 |
| authorId | String | 作者ID | 必填 |
| content | String | 评论内容 | 最大长度500 |
| likedCount | Int | 点赞数 | 默认0 |
| realLikedCount | Int | 实际点赞数 | 默认0 |
| timestamp | Int | 时间戳 | ISO8601格式 |
| status | String | 评论状态 | 未明确具体枚举值 |
用户资料数据结构
查询管理实现
KuaiShouGraphQL类
class KuaiShouGraphQL:
def __init__(self):
self.graphql_queries = {}
def load_graphql_queries(self, directory_path):
# 从指定目录加载所有.graphql文件
pass
def get(self, query_name):
# 根据名称返回查询模板
return self.graphql_queries.get(query_name, "Query not found")分页机制设计
技术特性总结
- 统一查询协议:所有接口遵循GraphQL规范,使用强类型数据结构
- 分页优化:通过
pcursor实现高效分页,避免大数据量传输 - 模块化设计:各查询接口职责单一,降低耦合度
- 扩展性:通过
KuaiShouGraphQL类集中管理查询模板,便于新增/修改查询
该模块作为快手媒体平台的核心数据访问层,为前端应用提供了标准化的数据获取方式,同时通过预定义查询模板确保后端数据访问的安全性和可控性。
Codebot Wiki,让项目文档更清晰、更智能、更贴合开发需求!
本网站提供的所有AI生成内容均基于人工智能技术和大语言模型算法,根据用户输入指令自动生成。生成内容不代表本网站观点,亦不构成任何形式的专业建议。本公司对生成内容的准确性、完整性、适用性及合法性不作明示或默示的保证,用户应对生成内容自行判断并承担全部使用风险。