
CodeBot Wiki 是一款基于大语言模型的智能文档生成工具,能够自动解析项目代码,生成结构清晰、内容专业的项目 Wiki。它不仅覆盖项目概览、核心模块、关键逻辑等信息,还支持交互式理解,更适合团队协作与持续迭代,是理解开源项目或内部系统的理想助手!
本期解读项目地址:https://github.com/comfyanonymous/ComfyUI
开始使用
概览
ComfyUI 是一个模块化、图形化的 AI 引擎和应用,主要用于设计和执行高级的 Stable Diffusion 管道。其核心功能是通过节点/流程图界面来构建复杂的生成式 AI 工作流,支持多种图像、视频、音频和 3D 模型的生成与编辑任务。用户无需编写代码即可进行实验性操作,包括图像生成(如 SD1.x、SDXL、Stable Cascade)、图像编辑(如 Inpainting、ControlNet)、视频生成(如 Mochi、Hunyuan Video)、音频处理(如 Stable Audio)等。ComfyUI 支持多平台部署(Windows、Linux、macOS),并提供智能内存管理、异步队列系统、模型加载优化等功能。此外,它还支持从 PNG/WebP 文件中加载完整工作流,并可通过配置文件(extra_model_paths.yaml)自定义模型路径。安装方式包括桌面应用、便携包、CLI 安装及手动安装,适用于不同 GPU 类型(NVIDIA、AMD、Intel、Apple Silicon、Ascend)。
项目结构与模块化设计
ComfyUI 采用模块化设计,将不同功能划分为独立的模块,便于维护和扩展。主要模块包括:
- API 与节点集成模块:提供与 ComfyUI 集成的多个 API 节点,支持图像、视频、3D 模型等 AI 内容生成功能。
- 执行管理模块:提供节点执行过程中的缓存管理、图结构构建与执行逻辑、进度跟踪、上下文管理和输入验证等功能。
- 模型管理模块:负责模型的加载、配置管理和训练过程,支持多种深度学习模型结构。
- 配置模块:提供 ComfyUI 自定义节点和项目配置的解析与数据验证功能。
- 工具模块:封装通用工具函数和配置信息,包括路径配置加载、依赖缺失提示生成以及 JSON 数据的递归合并等。
- 中间件与缓存控制模块:用于初始化和注册 FastAPI 中间件,包括 CORS 配置和自定义中间件逻辑,统一管理请求处理流程。
- 内部路由管理模块:提供 ComfyUI 内部使用的异步 Web 路由接口,包含日志管理、文件路径获取和文件列表查询等功能。
- 自定义节点模块:包含用于图像处理工作流的自定义节点实现,支持图像反色操作、WebSocket 图像保存及 Web API 接口功能。
- 脚本示例模块:提供与 ComfyUI API 交互的脚本示例,包含基本 API 调用和 WebSocket 连接方式。
- 测试模块:用于验证命令行工具(CLI)在不同场景下的行为是否符合预期,包含金标准文件测试、集成测试及测试脚本说明。
- 数据库迁移管理模块:用于管理数据库结构的版本控制和迁移操作。
- 应用设置管理模块:用于管理用户设置的读取和保存,支持从 JSON 文件加载设置,并通过 HTTP 接口提供增删改查操作。
- Comfy 类型定义与节点抽象模块:定义 ComfyUI 节点系统的类型提示和结构,支持自定义节点开发。
- 扩散模型采样与工具模块:提供扩散模型的采样方法、噪声调节策略及辅助工具函数。
核心执行引擎与节点调度机制
ComfyUI 的核心执行引擎负责管理节点执行流程、缓存机制、进度追踪和上下文状态。该模块通过多个子模块协同工作,确保图形化流程中的节点能够高效、有序地执行,并提供必要的性能优化和状态监控能力。
执行引擎架构
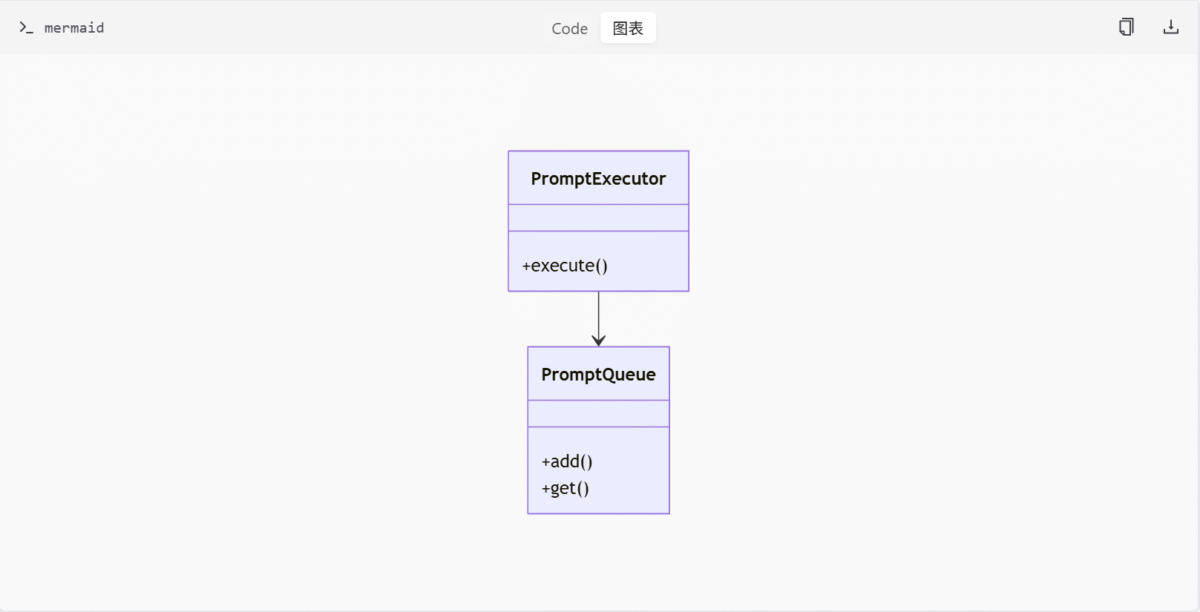
执行引擎的核心组件包括 PromptExecutor 和 PromptQueue,它们共同构成了 ComfyUI 的执行核心。
- PromptExecutor:负责节点的输入验证、缓存管理、异步执行流程控制及错误处理。它驱动整个 Prompt 的执行流程,包含异步执行、进度报告和异常处理。
- PromptQueue:维护待执行 Prompt 的优先级队列,并记录执行历史。它支持中断、清空、删除等操作,确保任务能够按顺序执行并提供历史记录查询功能。
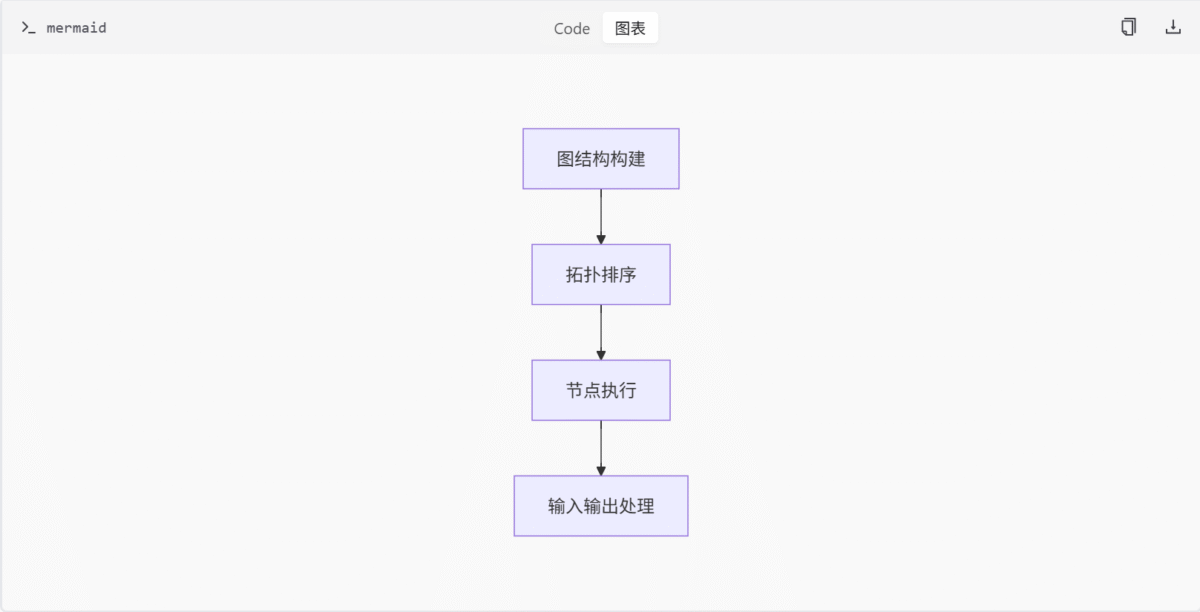
节点调度流程
节点调度流程是 ComfyUI 执行引擎的核心部分,负责将节点图转换为可执行的任务序列。
- 图结构构建:根据用户定义的节点图,构建执行图结构,确定节点间的依赖关系。
- 拓扑排序:对节点进行拓扑排序,确保节点按照依赖关系正确执行。
- 节点执行:按照排序结果,依次执行节点,并处理节点间的输入输出关系。
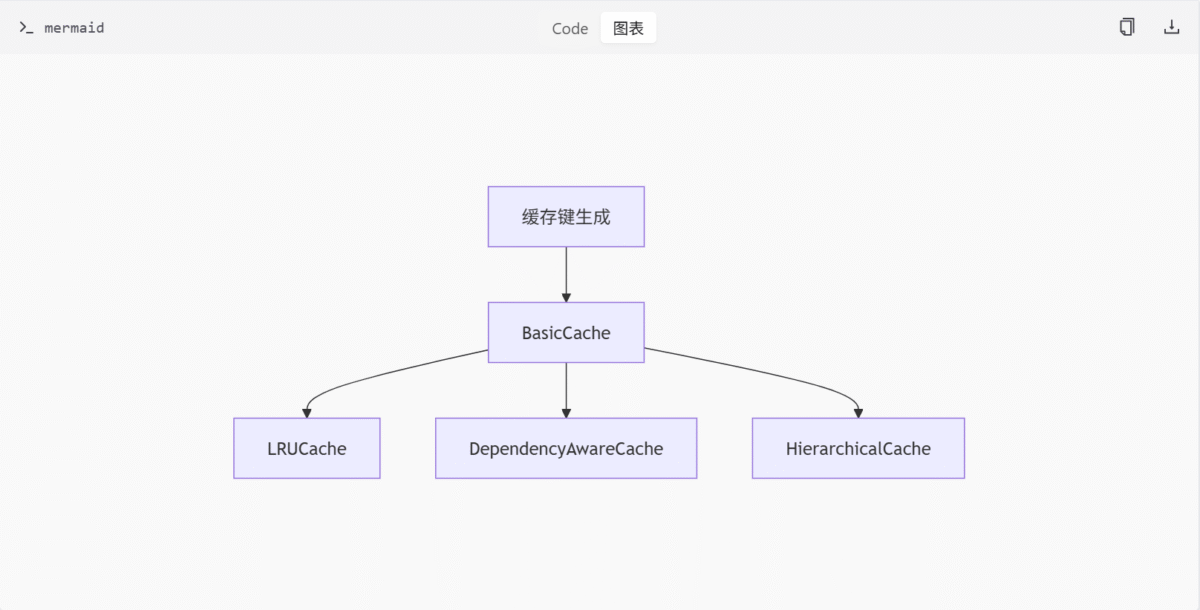
缓存机制
缓存机制是 ComfyUI 提升执行效率的重要手段,通过缓存已执行节点的结果,避免重复计算。
- BasicCache:提供通用缓存接口。
- LRUCache:实现 LRU(Least Recently Used)淘汰策略。
- DependencyAwareCache:维护节点间的依赖关系图,确保缓存项的依赖关系正确。
- HierarchicalCache:按层级组织缓存,支持更复杂的缓存结构。
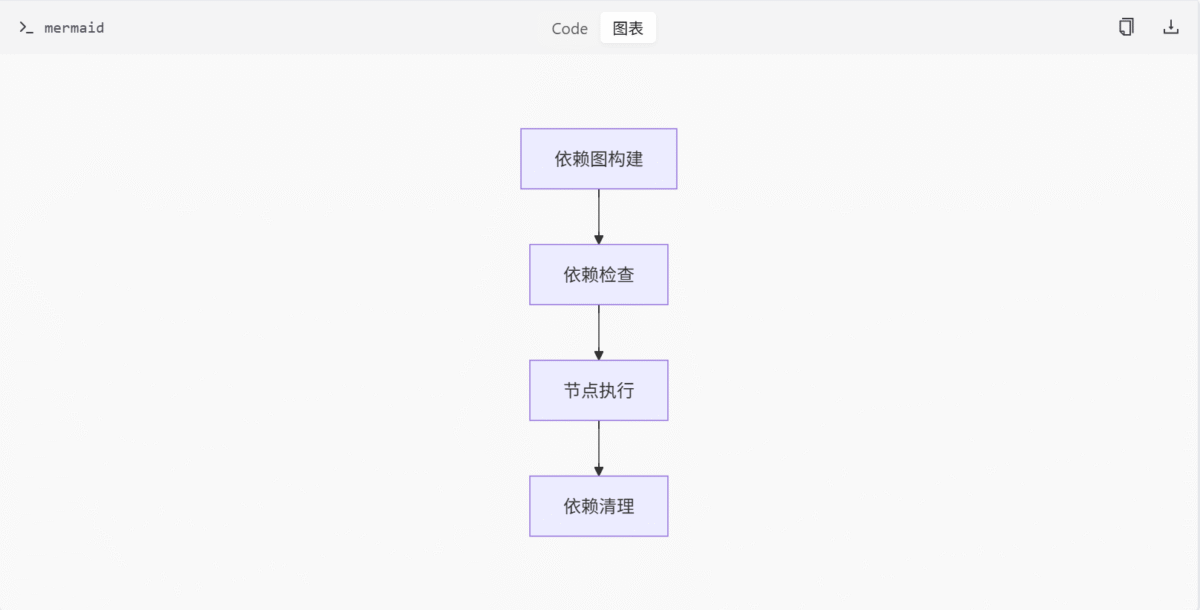
依赖管理
节点间依赖关系的处理是确保执行正确性的关键。ComfyUI 通过构建依赖图来管理节点间的依赖关系,并在执行过程中确保依赖节点已执行完毕。
核心功能与组件
| 功能/组件 | 描述 |
|---|---|
| API 与节点集成模块 | 提供与 ComfyUI 集成的多个 API 节点,支持图像、视频、3D 模型等 AI 内容生成功能 |
| 执行管理模块 | 提供节点执行过程中的缓存管理、图结构构建与执行逻辑、进度跟踪、上下文管理和输入验证等功能 |
| 模型管理模块 | 负责模型的加载、配置管理和训练过程,支持多种深度学习模型结构 |
| 配置模块 | 提供 ComfyUI 自定义节点和项目配置的解析与数据验证功能 |
| 工具模块 | 封装通用工具函数和配置信息,包括路径配置加载、依赖缺失提示生成以及 JSON 数据的递归合并等 |
| 中间件与缓存控制模块 | 用于初始化和注册 FastAPI 中间件,包括 CORS 配置和自定义中间件逻辑,统一管理请求处理流程 |
| 内部路由管理模块 | 提供 ComfyUI 内部使用的异步 Web 路由接口,包含日志管理、文件路径获取和文件列表查询等功能 |
| 自定义节点模块 | 包含用于图像处理工作流的自定义节点实现,支持图像反色操作、WebSocket 图像保存及 Web API 接口功能 |
| 脚本示例模块 | 提供与 ComfyUI API 交互的脚本示例,包含基本 API 调用和 WebSocket 连接方式 |
| 测试模块 | 用于验证命令行工具(CLI)在不同场景下的行为是否符合预期,包含金标准文件测试、集成测试及测试脚本说明 |
| 数据库迁移管理模块 | 用于管理数据库结构的版本控制和迁移操作 |
| 应用设置管理模块 | 用于管理用户设置的读取和保存,支持从 JSON 文件加载设置,并通过 HTTP 接口提供增删改查操作 |
| Comfy 类型定义与节点抽象模块 | 定义 ComfyUI 节点系统的类型提示和结构,支持自定义节点开发 |
| 扩散模型采样与工具模块 | 提供扩散模型的采样方法、噪声调节策略及辅助工具函数 |
技术栈
ComfyUI 的技术栈围绕 Python 生态构建,旨在支持深度学习、媒体处理和异步 API 集成。核心依赖包括 torch 及其生态系统,用于模型训练与推理;transformers 和 tokenizers 用于自然语言处理;aiohttp 和 yarl 用于异步网络请求;以及 SQLAlchemy 和 alembic 用于数据库管理。此外,项目通过 comfyui-frontend-package 集成 ComfyUI 前端界面,支持工作流模板的构建与执行。
总结
ComfyUI 通过模块化设计和丰富的功能,为用户提供了一个强大的图形化 AI 工作流平台。其支持多种生成式 AI 任务,并通过灵活的配置和扩展机制,满足不同用户的需求。项目的技术栈成熟稳定,确保了系统的高性能和可维护性。核心执行引擎与节点调度机制的设计,使得 ComfyUI 能够高效地处理复杂的节点图,提供流畅的用户体验。
快速开始
ComfyUI 是一个基于节点图的图像生成工具,其核心功能通过多个模块协同实现。main.py 作为启动入口,负责初始化环境、加载配置、设置路径并启动服务端。server.py 提供 Web 服务和 API 接口,execution.py 负责执行节点图逻辑,requirements.txt 列出了项目依赖。本页面将引导您快速了解 ComfyUI 的启动流程、核心组件和依赖管理。
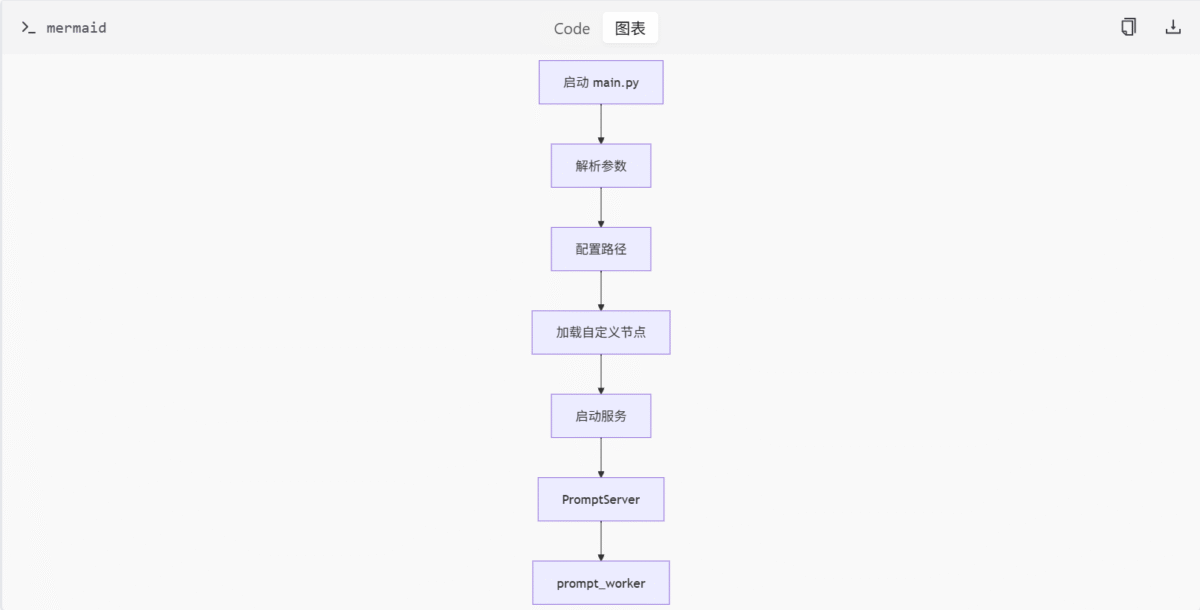
启动流程
ComfyUI 的启动流程由 main.py 驱动,主要包括环境初始化、路径配置、自定义节点加载和服务启动。
环境与参数解析
启动时首先调用 comfy.options.enable_args_parsing() 解析命令行参数并设置日志系统。此函数会处理用户通过命令行传入的各种参数,如模型路径、端口配置等,并根据这些参数初始化日志系统,确保运行时信息能够正确输出。
路径配置
根据用户指定或默认路径设置模型输入、输出、用户目录等,支持通过 YAML 配置文件扩展模型路径。路径配置是 ComfyUI 能够正确加载模型和保存输出的基础,确保系统能够找到所需的资源文件。
自定义节点管理
通过 execute_prestartup_script() 加载并执行自定义节点的 prestartup_script.py,用于初始化节点依赖或资源。这一机制允许用户扩展 ComfyUI 的功能,添加自定义节点以满足特定需求。
服务启动逻辑
使用 asyncio 启动异步服务器 PromptServer,监听请求并分发任务给 prompt_worker 线程进行执行。PromptServer 是 ComfyUI 的核心服务端逻辑实现,基于 aiohttp 提供 Web 服务和 API 接口。
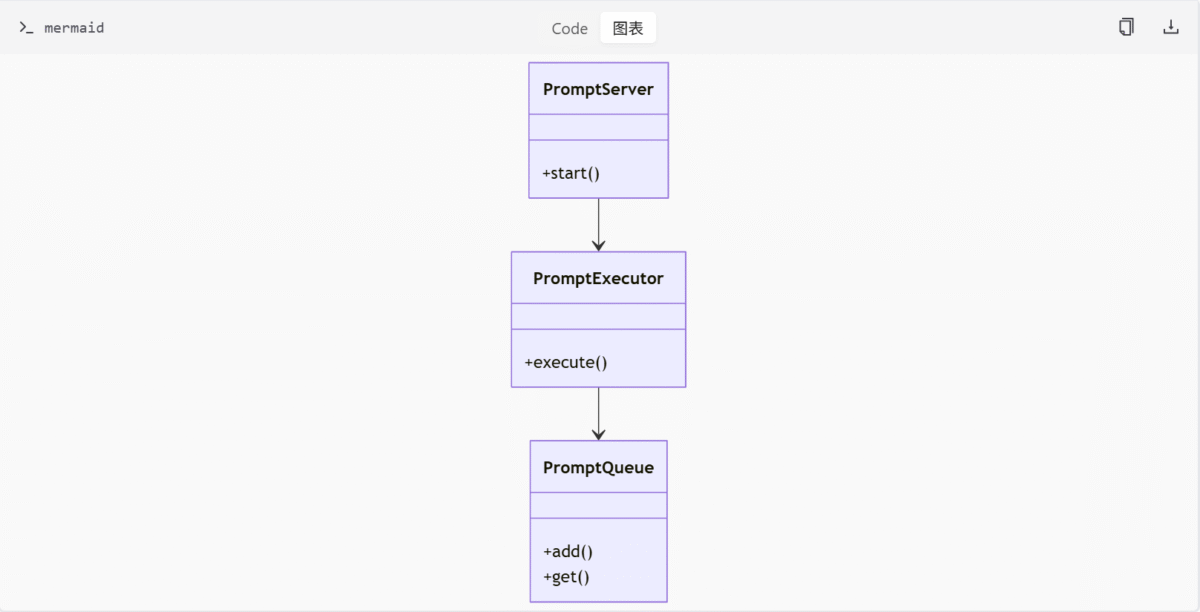
核心组件
PromptServer
PromptServer 是 ComfyUI 的核心服务端逻辑实现,基于 aiohttp 提供 Web 服务和 API 接口。它负责处理客户端请求,管理 WebSocket 连接,提供图像上传、模型列表获取、系统统计等 API 接口。
PromptExecutor
PromptExecutor 是执行节点图的核心逻辑模块,负责节点的输入验证、缓存管理、异步执行流程控制及错误处理。它驱动整个 Prompt 的执行流程,包含异步执行、进度报告和异常处理。
PromptQueue
PromptQueue 是任务队列管理器,维护待执行 Prompt 的优先级队列,并记录执行历史。它支持中断、清空、删除等操作,确保任务能够按顺序执行并提供历史记录查询功能。
依赖管理
requirements.txt 列出了项目运行所需的主要和非必需的第三方库及其版本要求。
| 依赖项 | 类型 | 描述 |
|---|---|---|
| torch | 必需 | 深度学习框架 |
| torchvision | 必需 | 图像处理工具 |
| numpy | 必需 | 科学计算库 |
| aiohttp | 必需 | 异步网络请求支持 |
| transformers | 非必需 | 自然语言处理库 |
总结
ComfyUI 的启动流程清晰,职责分明。main.py 作为启动入口,协调各模块初始化和服务启动。server.py 提供 Web 服务和 API 接口,execution.py 负责执行节点图逻辑。requirements.txt 管理项目依赖,确保环境一致性。通过以上组件的协同工作,ComfyUI 提供了灵活可扩展的图像生成服务。
技术栈
本项目的技术栈围绕 Python 生态构建,旨在支持深度学习、媒体处理和异步 API 集成。核心依赖包括 torch 及其生态系统,用于模型训练与推理;transformers 和 tokenizers 用于自然语言处理;aiohttp 和 yarl 用于异步网络请求;以及 SQLAlchemy 和 alembic 用于数据库管理。此外,项目通过 comfyui-frontend-package 集成 ComfyUI 前端界面,支持工作流模板的构建与执行。
依赖管理
项目依赖通过 requirements.txt 文件进行管理,明确区分核心依赖和非必需依赖。核心依赖确保项目基本功能的运行,而非必需依赖则扩展了项目在图像处理、音频处理等方面的能力。
核心依赖
- 深度学习框架:
torch,torchsde,torchvision,torchaudio - 科学计算与数据处理:
numpy,scipy,Pillow - 自然语言处理:
transformers,tokenizers,sentencepiece - 异步网络请求:
aiohttp,yarl - 数据库管理:
SQLAlchemy,alembic
非必需依赖
- 图像处理:
kornia,spandrel - 音频处理:
soundfile
API 客户端
comfy_api_nodes/apis/client.py 文件实现了用于 ComfyUI 节点调用 API 的客户端框架,支持同步和异步操作,并通过 Pydantic 模型进行请求与响应的类型验证。
核心组件
ApiClient 类
负责 HTTP 请求的发送、重试逻辑、身份验证及错误处理。支持连接性检测(本地网络 vs API 服务问题),并提供上传文件的功能。
ApiEndpoint 类
定义单个 API 端点的路径、HTTP 方法、请求/响应模型及查询参数。
SynchronousOperation 类
封装同步 API 调用逻辑,使用 ApiClient 发送请求并返回结果。
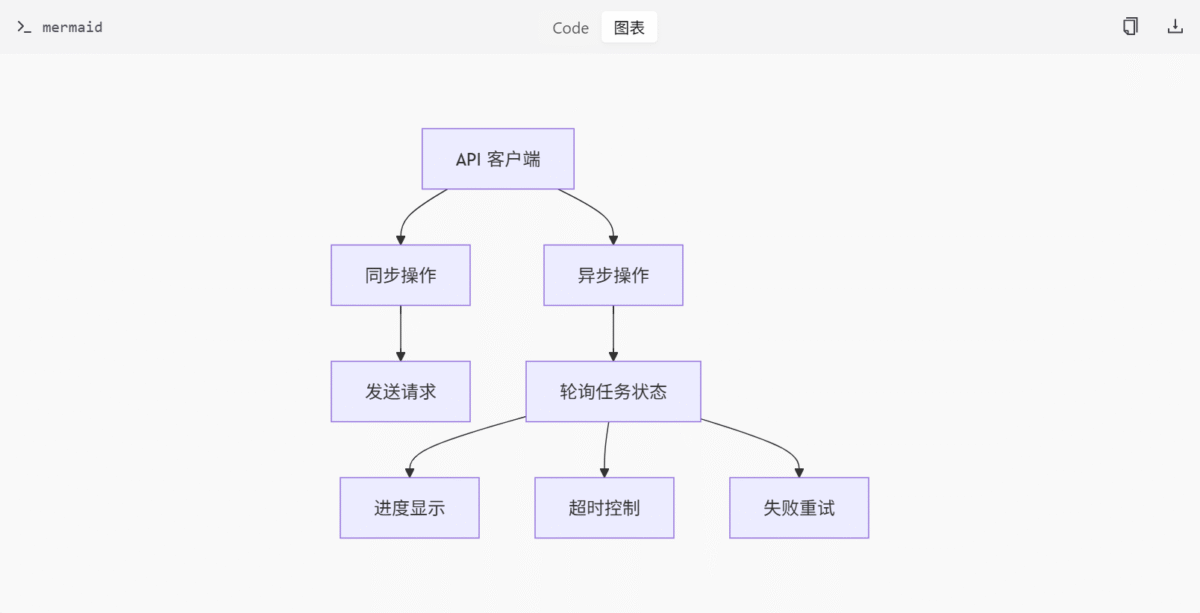
PollingOperation 类
实现异步 API 操作,适用于需要轮询任务状态的场景(如图像生成)。支持进度显示、超时控制、失败重试等。
异常处理
定义了异常类(如 NetworkError, LocalNetworkError, ApiServerError)以区分不同类型的错误,并提供清晰的用户提示信息。
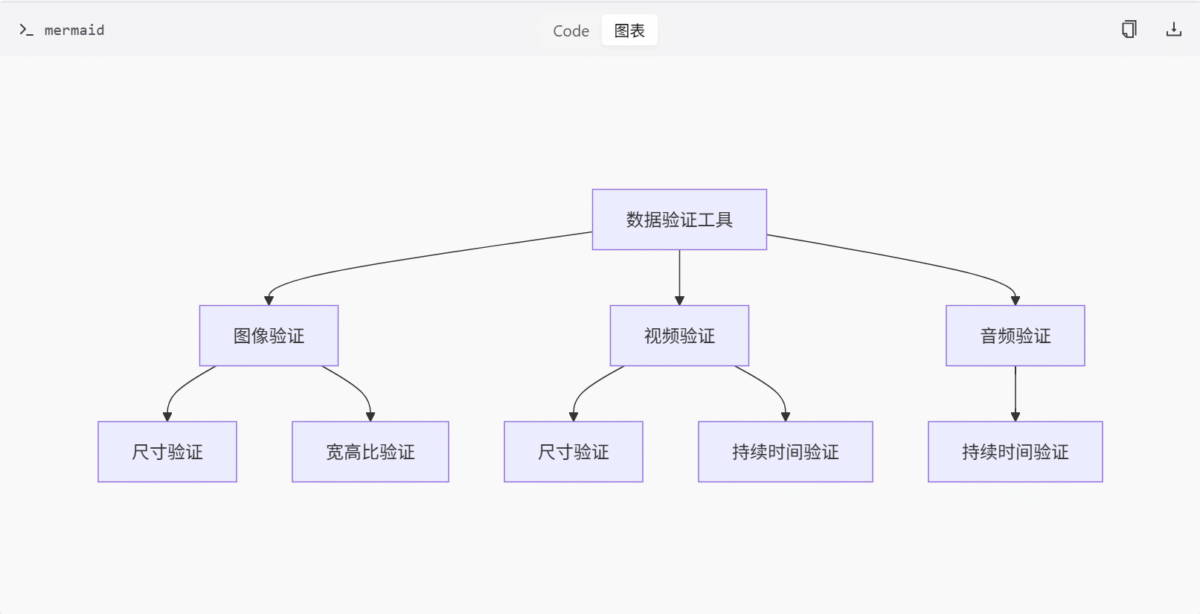
数据验证工具
comfy_api_nodes/util/validation_utils.py 文件提供了一系列用于验证图像、视频和音频输入数据的工具函数,主要用于检查尺寸、宽高比及持续时间是否符合指定的限制条件。
核心函数
get_image_dimensions: 从图像张量中提取宽度和高度。validate_image_dimensions: 检查图像的宽度和高度是否在给定范围内。validate_image_aspect_ratio: 验证图像的宽高比是否在指定范围内。validate_image_aspect_ratio_range: 更精细地控制宽高比范围,并支持闭区间/开区间的判断。validate_aspect_ratio_closeness: 比较两个图像的宽高比是否接近,用于一致性校验。validate_video_dimensions: 类似于图像,但针对视频的宽高进行验证。validate_video_duration: 验证视频的持续时间是否在允许范围内。get_number_of_images: 计算图像数量。validate_audio_duration: 验证音频的持续时间。
主要功能与组件
| 功能/组件 | 描述 |
|---|---|
torch 生态系统 | 用于模型训练与推理的核心深度学习框架 |
transformers 和 tokenizers | 用于自然语言处理的库 |
aiohttp 和 yarl | 用于异步网络请求的库 |
SQLAlchemy 和 alembic | 用于数据库管理的库 |
ApiClient 类 | 负责 HTTP 请求的发送、重试逻辑、身份验证及错误处理 |
ApiEndpoint 类 | 定义单个 API 端点的路径、HTTP 方法、请求/响应模型及查询参数 |
SynchronousOperation 类 | 封装同步 API 调用逻辑 |
PollingOperation 类 | 实现异步 API 操作,适用于需要轮询任务状态的场景 |
get_image_dimensions 函数 | 从图像张量中提取宽度和高度 |
validate_image_dimensions 函数 | 检查图像的宽度和高度是否在给定范围内 |
validate_image_aspect_ratio 函数 | 验证图像的宽高比是否在指定范围内 |
validate_video_dimensions 函数 | 类似于图像,但针对视频的宽高进行验证 |
validate_video_duration 函数 | 验证视频的持续时间是否在允许范围内 |
validate_audio_duration 函数 | 验证音频的持续时间 |
总结
本项目的技术栈涵盖了深度学习、媒体处理和异步 API 集成等多个方面,通过明确的依赖管理和模块化设计,确保了项目的灵活性和可扩展性。API 客户端和数据验证工具的实现,进一步增强了项目在处理复杂任务时的稳定性和可靠性。
API 与节点集成模块
API 与节点集成模块是 ComfyUI 的一个核心扩展系统,旨在通过封装外部 AI 服务的 API 接口,为用户提供图形化、可拖拽的节点操作界面。该模块涵盖了图像生成、视频生成、3D 模型处理、多模态交互等多种功能,支持与 BFL、Google Gemini、Ideogram、Kling、Luma、MiniMax、OpenAI、Pika、PixVerse、Recraft、Rodin、Runway、Stability AI、Tripo、Veo、Vidu 等多个 AI 服务提供商的 API 集成。
通过该模块,开发者和用户可以轻松地将外部 AI 能力集成到 ComfyUI 的工作流中,实现从文本到图像、从图像到视频、3D 模型生成等复杂任务的自动化处理。
模块架构与核心组件
模块结构
API 与节点集成模块由多个子模块组成,每个子模块负责与特定的 AI 服务进行交互。模块的核心组件包括:
- API 客户端框架:位于
apis/client.py,提供统一的 API 请求发送、重试、身份验证和错误处理机制。 - 数据模型定义:位于
apis/目录下,使用 Pydantic 定义与各 AI 服务交互所需的数据结构。 - 节点实现:位于
nodes_*.py文件中,每个文件对应一个 AI 服务,定义了与该服务相关的 ComfyUI 节点。 - 工具函数:位于
apinode_utils.py和mapper_utils.py,提供图像、视频、音频处理和模型字段映射等辅助功能。 - 验证工具:位于
util/validation_utils.py,提供输入验证功能,确保媒体文件符合处理要求。
核心类与接口
API 客户端框架
API 客户端框架定义了与外部 API 交互的基本结构,包括同步与异步操作类及异常类型。核心类包括:
SynchronousOperation:用于同步 API 调用。PollingOperation:用于异步 API 调用,支持任务状态轮询。
数据模型
数据模型使用 Pydantic 定义,确保与 AI 服务交互的数据结构符合规范。核心模型包括:
BFLFluxProGenerateRequest:BFL 图像生成请求模型。GeminiGenerateContentRequest:Google Gemini 内容生成请求模型。KlingImage2VideoRequest:Kling 图像到视频生成请求模型。LumaImageGenerationNode:Luma 图像生成节点模型。StabilityStable3_5Request:Stability AI 图像生成请求模型。TripoTextToModelNode:Tripo 文本到模型生成请求模型。
节点实现
每个 nodes_*.py 文件定义了与特定 AI 服务相关的 ComfyUI 节点。核心节点包括:
BFLFluxProGenerateNode:BFL 图像生成节点。GeminiNode:Google Gemini 节点。KlingTextToVideoNode:Kling 文本到视频生成节点。LumaImageGenerationNode:Luma 图像生成节点。StabilityStableImageUltraNode:Stability AI 图像生成节点。TripoTextToModelNode:Tripo 文本到模型生成节点。
数据流与处理逻辑
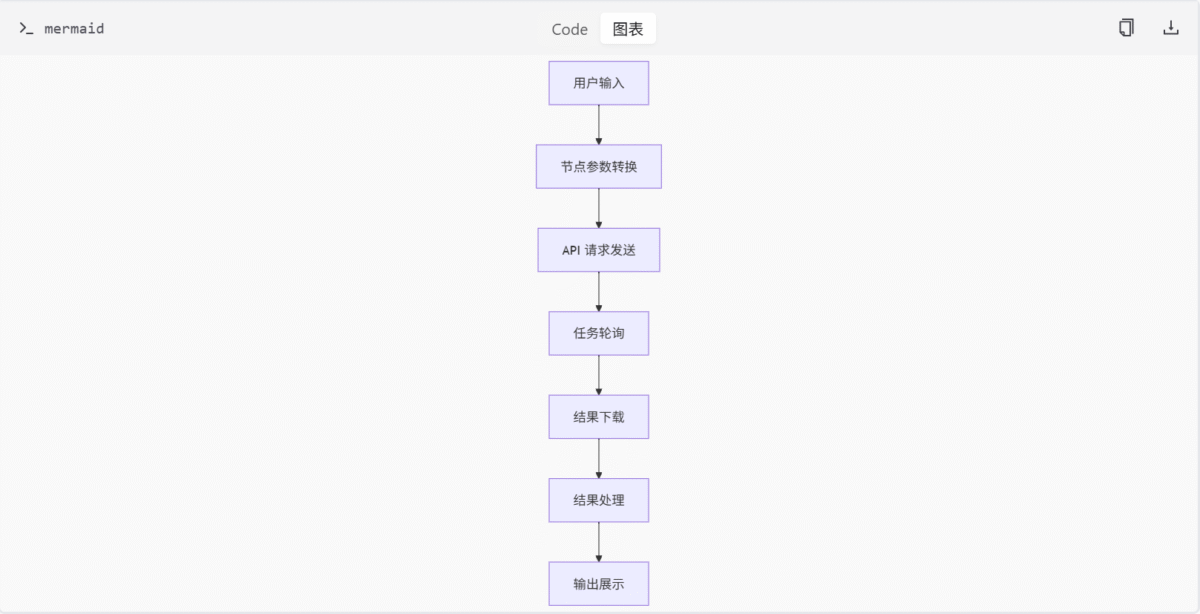
API 与节点集成模块的数据流遵循以下逻辑:
- 输入处理:用户通过 ComfyUI 界面输入参数,节点将参数转换为 API 请求所需的数据结构。
- API 调用:节点通过 API 客户端框架发送请求到外部 AI 服务。
- 任务轮询:对于异步任务,节点使用
PollingOperation轮询任务状态,直到任务完成。 - 结果处理:任务完成后,节点下载并处理结果,将其转换为 ComfyUI 兼容的格式。
- 输出展示:处理后的结果在 ComfyUI 界面中展示给用户。
主要功能与组件
| 功能/组件 | 描述 |
|---|---|
| API 客户端框架 | 提供统一的 API 请求发送、重试、身份验证和错误处理机制 |
| 数据模型定义 | 使用 Pydantic 定义与各 AI 服务交互所需的数据结构 |
| 节点实现 | 定义与特定 AI 服务相关的 ComfyUI 节点 |
| 工具函数 | 提供图像、视频、音频处理和模型字段映射等辅助功能 |
| 验证工具 | 提供输入验证功能,确保媒体文件符合处理要求 |
API 接口参数与类型
| 接口名称 | 参数 | 类型 | 描述 |
|---|---|---|---|
| BFLFluxProGenerateRequest | prompt | str | 图像生成提示 |
| model | str | 使用的模型 | |
| width | int | 图像宽度 | |
| height | int | 图像高度 | |
| GeminiGenerateContentRequest | contents | list | 多模态输入内容 |
| generation_config | dict | 生成配置 | |
| KlingImage2VideoRequest | prompt | str | 视频生成提示 |
| image | str | 输入图像 | |
| LumaImageGenerationNode | prompt | str | 图像生成提示 |
| model | str | 使用的模型 | |
| aspect_ratio | str | 图像宽高比 | |
| StabilityStable3_5Request | prompt | str | 图像生成提示 |
| model | str | 使用的模型 | |
| width | int | 图像宽度 | |
| height | int | 图像高度 | |
| TripoTextToModelNode | prompt | str | 3D 模型生成提示 |
| model | str | 使用的模型 |
配置选项与默认值
| 配置项 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| API_KEY | str | None | API 访问密钥 |
| BASE_URL | str | None | API 基础 URL |
| TIMEOUT | int | 30 | 请求超时时间(秒) |
| RETRIES | int | 3 | 请求重试次数 |
数据模型字段与约束
| 模型 | 字段 | 类型 | 约束 | 描述 |
|---|---|---|---|---|
| BFLFluxProGenerateRequest | prompt | str | 必填 | 图像生成提示 |
| model | str | 必填 | 使用的模型 | |
| width | int | >= 256 | 图像宽度 | |
| height | int | >= 256 | 图像高度 | |
| GeminiGenerateContentRequest | contents | list | 必填 | 多模态输入内容 |
| generation_config | dict | 可选 | 生成配置 | |
| KlingImage2VideoRequest | prompt | str | 必填 | 视频生成提示 |
| image | str | 必填 | 输入图像 | |
| LumaImageGenerationNode | prompt | str | 必填 | 图像生成提示 |
| model | str | 必填 | 使用的模型 | |
| aspect_ratio | str | 必填 | 图像宽高比 | |
| StabilityStable3_5Request | prompt | str | 必填 | 图像生成提示 |
| model | str | 必填 | 使用的模型 | |
| width | int | >= 256 | 图像宽度 | |
| height | int | >= 256 | 图像高度 | |
| TripoTextToModelNode | prompt | str | 必填 | 3D 模型生成提示 |
| model | str | 必填 | 使用的模型 |
API 客户端框架详解
API 客户端框架是整个模块的核心,负责与外部 AI 服务进行通信。它提供了统一的接口,简化了 API 调用的复杂性,并确保了请求的可靠性和安全性。
核心类定义
API 客户端框架的核心类包括 ApiClient、ApiEndpoint、SynchronousOperation 和 PollingOperation。这些类共同构成了一个完整的 API 调用体系。
ApiClient 类
ApiClient 类是 API 客户端框架的核心,负责管理 API 请求的发送、身份验证和错误处理。它提供了以下主要功能:
- 请求发送:通过
send_request方法发送 HTTP 请求。 - 身份验证:通过
authenticate方法处理 API 密钥的添加。 - 错误处理:通过
handle_error方法处理 API 返回的错误信息。
class ApiClient:
def __init__(self, base_url: str, api_key: str = None, timeout: int = 30):
self.base_url = base_url
self.api_key = api_key
self.timeout = timeout
self.session = requests.Session()
def authenticate(self, headers: dict) -> dict:
if self.api_key:
headers['Authorization'] = f'Bearer {self.api_key}'
return headers
def send_request(self, method: str, url: str, **kwargs) -> requests.Response:
headers = kwargs.get('headers', {})
headers = self.authenticate(headers)
kwargs['headers'] = headers
kwargs['timeout'] = self.timeout
response = self.session.request(method, url, **kwargs)
return response
def handle_error(self, response: requests.Response):
if response.status_code >= 400:
raise ApiError(f"API request failed with status {response.status_code}: {response.text}")ApiEndpoint 类
ApiEndpoint 类用于定义 API 端点的路径、方法和参数。它提供了以下主要功能:
- 端点定义:通过
path和method属性定义 API 端点。 - 参数处理:通过
build_url方法构建完整的 API URL。
class ApiEndpoint:
def __init__(self, path: str, method: str = 'GET'):
self.path = path
self.method = method
def build_url(self, base_url: str, **kwargs) -> str:
url = f"{base_url.rstrip('/')}/{self.path.lstrip('/')}"
if kwargs:
url += '?' + '&'.join([f"{k}={v}" for k, v in kwargs.items()])
return urlSynchronousOperation 类
SynchronousOperation 类用于执行同步 API 调用。它继承自 ApiClient,并提供了以下主要功能:
- 同步请求:通过
execute方法执行同步 API 请求。
class SynchronousOperation(ApiClient):
def execute(self, endpoint: ApiEndpoint, **kwargs) -> dict:
url = endpoint.build_url(self.base_url, **kwargs)
response = self.send_request(endpoint.method, url, **kwargs)
self.handle_error(response)
return response.json()PollingOperation 类
PollingOperation 类用于执行异步 API 调用,并支持任务状态轮询。它继承自 ApiClient,并提供了以下主要功能:
- 异步请求:通过
execute方法发起异步 API 请求。 - 任务轮询:通过
poll方法轮询任务状态,直到任务完成。
class PollingOperation(ApiClient):
def __init__(self, base_url: str, api_key: str = None, timeout: int = 30, poll_interval: int = 5):
super().__init__(base_url, api_key, timeout)
self.poll_interval = poll_interval
def execute(self, endpoint: ApiEndpoint, **kwargs) -> dict:
url = endpoint.build_url(self.base_url, **kwargs)
response = self.send_request(endpoint.method, url, **kwargs)
self.handle_error(response)
return response.json()
def poll(self, task_id: str, status_endpoint: ApiEndpoint) -> dict:
while True:
response = self.execute(status_endpoint, task_id=task_id)
status = response.get('status')
if status == 'completed':
return response
elif status == 'failed':
raise ApiError(f"Task failed: {response.get('error')}")
time.sleep(self.poll_interval)身份验证机制
API 客户端框架通过 authenticate 方法处理身份验证。它支持 Bearer Token 认证方式,将 API 密钥添加到请求头中。
def authenticate(self, headers: dict) -> dict:
if self.api_key:
headers['Authorization'] = f'Bearer {self.api_key}'
return headers错误处理机制
API 客户端框架通过 handle_error 方法处理 API 返回的错误信息。当 API 请求返回 4xx 或 5xx 状态码时,框架会抛出 ApiError 异常。
def handle_error(self, response: requests.Response):
if response.status_code >= 400:
raise ApiError(f"API request failed with status {response.status_code}: {response.text}")请求重试逻辑
API 客户端框架支持请求重试机制,当 API 请求失败时,框架会自动重试指定次数。重试逻辑通过 retry 装饰器实现。
from functools import wraps
import time
def retry(max_retries: int = 3, delay: int = 1):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except Exception as e:
if attempt == max_retries - 1:
raise e
time.sleep(delay)
return None
return wrapper
return decorator与其他模块的交互
API 客户端框架与其他模块通过以下方式交互:
- 数据模型:API 客户端框架使用 Pydantic 定义的数据模型来构建 API 请求和解析 API 响应。
- 节点实现:节点通过 API 客户端框架发送 API 请求,并处理返回的结果。
- 工具函数:工具函数为 API 客户端框架提供辅助功能,如日志记录、数据转换等。
总结
API 与节点集成模块通过封装外部 AI 服务的 API 接口,为 ComfyUI 提供了丰富的节点功能,支持图像生成、视频生成、3D 模型处理等多种任务。模块的核心组件包括 API 客户端框架、数据模型定义、节点实现、工具函数和验证工具。通过这些组件的协同工作,用户可以轻松地将外部 AI 能力集成到 ComfyUI 的工作流中,实现复杂任务的自动化处理。
API 客户端框架作为整个模块的核心,提供了统一的 API 请求发送、重试、身份验证和错误处理机制。它通过 ApiClient、ApiEndpoint、SynchronousOperation 和 PollingOperation 等核心类,构建了一个完整的 API 调用体系。框架支持 Bearer Token 认证方式,并通过 handle_error 方法处理 API 返回的错误信息。此外,框架还支持请求重试机制,确保 API 请求的可靠性。通过与其他模块的紧密交互,API 客户端框架为整个模块提供了稳定、高效的 API 调用支持。
扩散模型采样与工具模块
简介
扩散模型采样与工具模块是 ComfyUI 项目中用于实现高效、灵活扩散模型采样及相关辅助功能的核心组件。该模块通过多个子模块分别处理采样算法、噪声调度、求解器实现以及通用工具函数,为扩散模型的训练和推理提供支持。
该模块主要包括以下功能:
- DEIS 采样器辅助函数:提供高效的 DEIS 采样策略;
- 多种采样算法与噪声调度:包括 Euler、Heun、DPM-Solver 等;
- SA-Solver 实现:用于高精度逆向过程的随机微分方程求解;
- 训练与数据处理工具:如模型模式管理、EMA 更新、日志记录等。
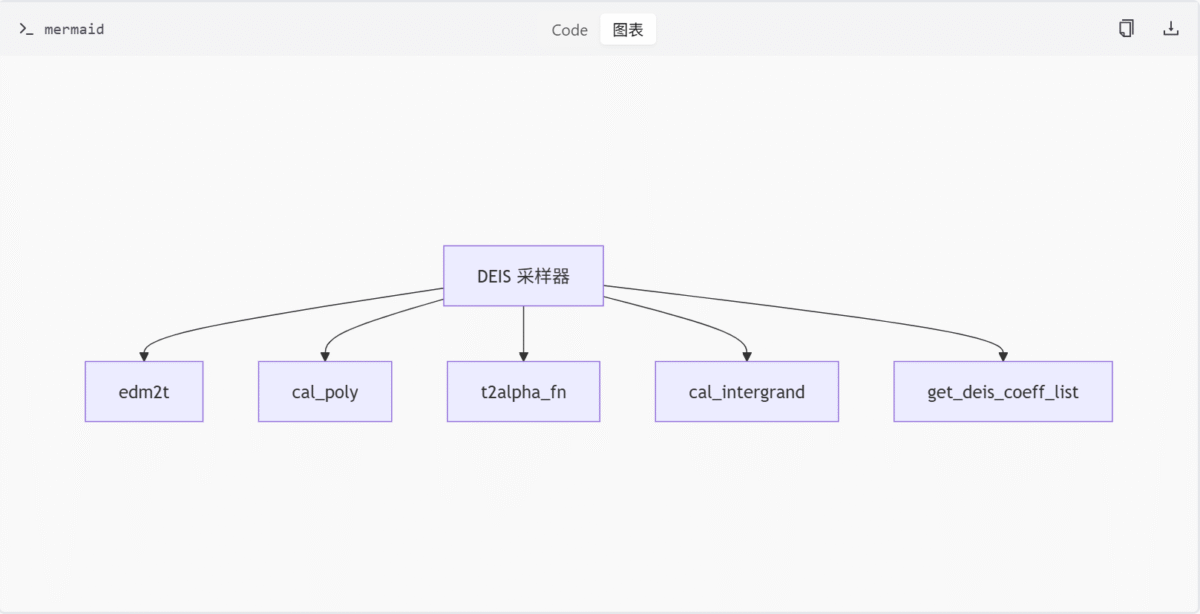
DEIS 采样器辅助函数 (deis.py)
功能概述
deis.py 文件实现了 DEIS 采样器所需的辅助函数,主要用于扩散模型中的高效采样。核心功能包括时间步转换、拉格朗日插值多项式计算、alpha 值计算以及积分项生成等。
关键函数
| 函数名 | 描述 |
|---|---|
edm2t | 将 EDM 的 sigma 转换为时间步 t |
cal_poly | 计算拉格朗日插值多项式 |
t2alpha_fn | 根据 t 和 beta 计算 alpha_t |
cal_intergrand | 计算对数 alpha 导数并返回积分项 |
get_deis_coeff_list | 生成 DEIS 系数列表,支持 'tab' 数值积分和 'rhoab' 解析解模式 |
Mermaid 图
采样算法与噪声调度 (sampling.py)
功能概述
sampling.py 文件实现了多种扩散模型采样方法与噪声调度策略。包括噪声调度函数、采样算法、工具类以及特殊逻辑支持。
关键函数与类
| 名称 | 类型 | 描述 |
|---|---|---|
get_sigmas_karras | 函数 | Karras 噪声调度 |
get_sigmas_exponential | 函数 | 指数噪声调度 |
BrownianTreeNoiseSampler | 类 | 布朗树噪声采样器 |
PIDStepSizeController | 类 | PID 步长控制器 |
| Euler, Heun, DPM-Solver 等 | 算法 | 多种采样算法 |
Mermaid 图
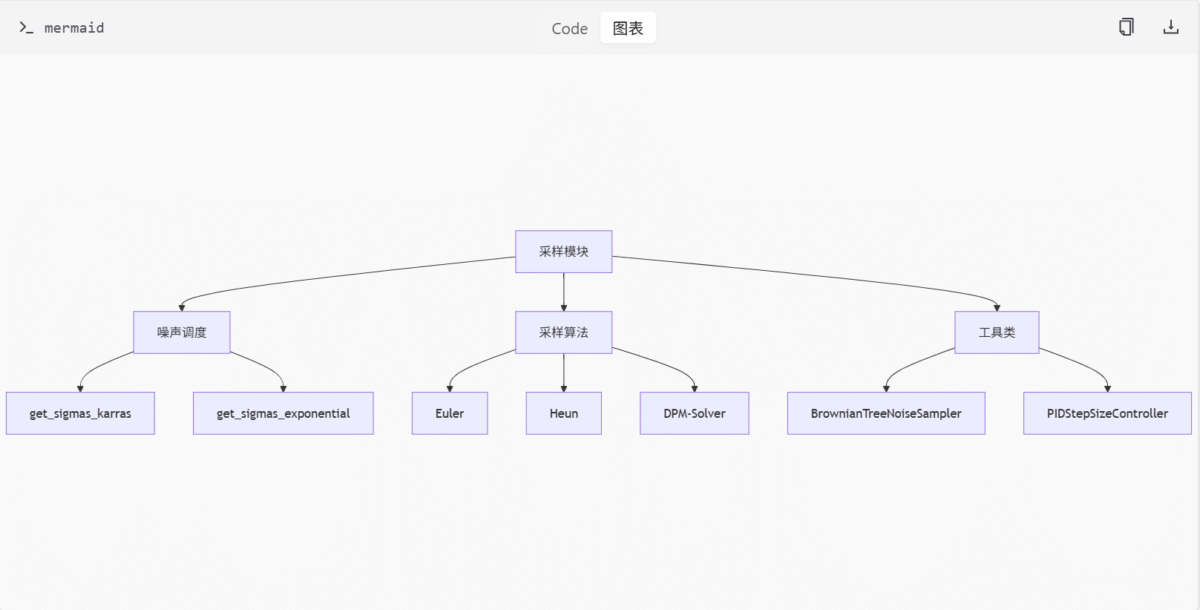
噪声调度函数
噪声调度是扩散模型采样的关键步骤,它决定了在每个时间步添加的噪声量。sampling.py 文件中实现了多种噪声调度策略:
- Karras 调度 (
get_sigmas_karras):- 该函数根据 Karras 等人 (2022) 的论文构造噪声序列。
- 它使用一个
ramp变量在 0 到 1 之间线性插值,然后通过幂律变换映射到 sigma 值。 - 最后通过
append_zero函数在序列末尾添加一个 0,表示最终的无噪声状态。
def get_sigmas_karras(n, sigma_min, sigma_max, rho=7., device='cpu'): """Constructs the noise schedule of Karras et al. (2022).""" ramp = torch.linspace(0, 1, n, device=device) min_inv_rho = sigma_min ** (1 / rho) max_inv_rho = sigma_max ** (1 / rho) sigmas = (max_inv_rho + ramp * (min_inv_rho - max_inv_rho)) ** rho return append_zero(sigmas).to(device) - 指数调度 (
get_sigmas_exponential):- 该函数构造一个指数衰减的噪声序列。
- 它首先在
log(sigma_max)和log(sigma_min)之间进行线性插值,然后对结果取指数。
def get_sigmas_exponential(n, sigma_min, sigma_max, device='cpu'): """Constructs an exponential noise schedule.""" sigmas = torch.linspace(math.log(sigma_max), math.log(sigma_min), n, device=device).exp() return append_zero(sigmas) - VP 调度 (
get_sigmas_vp):- 该函数构造一个连续的 VP (Variance Preserving) 噪声序列。
- 它使用 VP SDE 的解析解来计算 sigma 值。
def get_sigmas_vp(n, beta_d=19.9, beta_min=0.1, eps_s=1e-3, device='cpu'): """Constructs a continuous VP noise schedule.""" t = torch.linspace(1, eps_s, n, device=device) sigmas = torch.sqrt(torch.special.expm1(beta_d * t ** 2 / 2 + beta_min * t)) return append_zero(sigmas)
核心采样算法
采样算法是扩散模型从噪声中生成图像的核心。sampling.py 文件实现了多种经典和先进的采样算法:
- Euler 方法 (
sample_euler):- 这是最基础的数值积分方法,直接使用导数信息进行一步更新。
- 它实现了 Karras 论文中的 Algorithm 2,并支持随机噪声的引入(
s_churn参数)。
```python
@torch.no_grad()
def sample_euler(model, x, sigmas, extra_args=None, callback=None, disable=None, s_churn=0., s_tmin=0., s_tmax=float('inf'), s_noise=1.):
"""Implements Algorithm 2 (Euler steps) from Karras et al. (2022)."""
extra_args = {} if extra_args is None else extra_args
s_in = x.new_ones([x.shape[0]])
for i in trange(len(sigmas) - 1, disable=disable):
if s_churn > 0:
gamma = min(s_churn / (len(sigmas) - 1), 2 ** 0.5 - 1) if s_tmin <= sigmas[i] <= s_tmax else 0.
sigma_hat = sigmas[i] * (gamma + 1)
else:
gamma = 0
sigma_hat = sigmas[i]
if gamma > 0:
eps = torch.randn_like(x) * s_noise
x = x + eps * (sigma_hat ** 2 - sigmas[i] ** 2) ** 0.5
denoised = model(x, sigma_hat * s_in, **extra_args)
d = to_d(x, sigma_hat, denoised)
if callback is not None:
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigma_hat, 'denoised': denoised})
dt = sigmas[i + 1] - sigma_hat
# Euler method
x = x + d * dt
return x
```- Heun 方法 (
sample_heun):- 这是一种二阶 Runge-Kutta 方法,比 Euler 方法更精确。
- 它通过计算两个导数(当前点和预测点)的平均值来更新状态。
```python
@torch.no_grad()
def sample_heun(model, x, sigmas, extra_args=None, callback=None, disable=None, s_churn=0., s_tmin=0., s_tmax=float('inf'), s_noise=1.):
"""Implements Algorithm 2 (Heun steps) from Karras et al. (2022)."""
extra_args = {} if extra_args is None else extra_args
s_in = x.new_ones([x.shape[0]])
for i in trange(len(sigmas) - 1, disable=disable):
if s_churn > 0:
gamma = min(s_churn / (len(sigmas) - 1), 2 ** 0.5 - 1) if s_tmin <= sigmas[i] <= s_tmax else 0.
sigma_hat = sigmas[i] * (gamma + 1)
else:
gamma = 0
sigma_hat = sigmas[i]
sigma_hat = sigmas[i] * (gamma + 1)
if gamma > 0:
eps = torch.randn_like(x) * s_noise
x = x + eps * (sigma_hat ** 2 - sigmas[i] ** 2) ** 0.5
denoised = model(x, sigma_hat * s_in, **extra_args)
d = to_d(x, sigma_hat, denoised)
if callback is not None:
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigma_hat, 'denoised': denoised})
dt = sigmas[i + 1] - sigma_hat
if sigmas[i + 1] == 0:
# Euler method
x = x + d * dt
else:
# Heun's method
x_2 = x + d * dt
denoised_2 = model(x_2, sigmas[i + 1] * s_in, **extra_args)
d_2 = to_d(x_2, sigmas[i + 1], denoised_2)
d_prime = (d + d_2) / 2
x = x + d_prime * dt
return x
```- DPM-Solver (
sample_dpm_2,sample_dpm_2_ancestral):- 这是一类基于扩散概率模型的高效求解器。
sample_dpm_2实现了二阶 DPM-Solver,通过中点法提高精度。sample_dpm_2_ancestral在此基础上引入了祖先采样(添加噪声)。
```python
@torch.no_grad()
def sample_dpm_2(model, x, sigmas, extra_args=None, callback=None, disable=None, s_churn=0., s_tmin=0., s_tmax=float('inf'), s_noise=1.):
"""A sampler inspired by DPM-Solver-2 and Algorithm 2 from Karras et al. (2022)."""
extra_args = {} if extra_args is None else extra_args
s_in = x.new_ones([x.shape[0]])
for i in trange(len(sigmas) - 1, disable=disable):
if s_churn > 0:
gamma = min(s_churn / (len(sigmas) - 1), 2 ** 0.5 - 1) if s_tmin <= sigmas[i] <= s_tmax else 0.
sigma_hat = sigmas[i] * (gamma + 1)
else:
gamma = 0
sigma_hat = sigmas[i]
if gamma > 0:
eps = torch.randn_like(x) * s_noise
x = x + eps * (sigma_hat ** 2 - sigmas[i] ** 2) ** 0.5
denoised = model(x, sigma_hat * s_in, **extra_args)
d = to_d(x, sigma_hat, denoised)
if callback is not None:
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigma_hat, 'denoised': denoised})
if sigmas[i + 1] == 0:
# Euler method
dt = sigmas[i + 1] - sigma_hat
x = x + d * dt
else:
# DPM-Solver-2
sigma_mid = sigma_hat.log().lerp(sigmas[i + 1].log(), 0.5).exp()
dt_1 = sigma_mid - sigma_hat
dt_2 = sigmas[i + 1] - sigma_hat
x_2 = x + d * dt_1
denoised_2 = model(x_2, sigma_mid * s_in, **extra_args)
d_2 = to_d(x_2, sigma_mid, denoised_2)
x = x + d_2 * dt_2
return x
```工具类
- 布朗树噪声采样器 (
BrownianTreeNoiseSampler):- 该类使用
torchsde.BrownianTree来生成噪声,可以提供更好的随机性。 - 它通过
BatchedBrownianTree支持批量处理。
- 该类使用
```python
class BrownianTreeNoiseSampler:
"""A noise sampler backed by a torchsde.BrownianTree.
Args:
x (Tensor): The tensor whose shape, device and dtype to use to generate
random samples.
sigma_min (float): The low end of the valid interval.
sigma_max (float): The high end of the valid interval.
seed (int or List[int]): The random seed. If a list of seeds is
supplied instead of a single integer, then the noise sampler will
use one BrownianTree per batch item, each with its own seed.
transform (callable): A function that maps sigma to the sampler's
internal timestep.
"""
def __init__(self, x, sigma_min, sigma_max, seed=None, transform=lambda x: x, cpu=False):
self.transform = transform
t0, t1 = self.transform(torch.as_tensor(sigma_min)), self.transform(torch.as_tensor(sigma_max))
self.tree = BatchedBrownianTree(x, t0, t1, seed, cpu=cpu)
def __call__(self, sigma, sigma_next):
t0, t1 = self.transform(torch.as_tensor(sigma)), self.transform(torch.as_tensor(sigma_next))
return self.tree(t0, t1) / (t1 - t0).abs().sqrt()
```- PID 步长控制器 (
PIDStepSizeController):- 该类实现了一个 PID 控制器,用于自适应地调整 ODE 求解器的步长。
- 它根据误差历史动态调整步长,以平衡精度和效率。
```python
class PIDStepSizeController:
"""A PID controller for ODE adaptive step size control."""
def __init__(self, h, pcoeff, icoeff, dcoeff, order=1, accept_safety=0.81, eps=1e-8):
self.h = h
self.b1 = (pcoeff + icoeff + dcoeff) / order
self.b2 = -(pcoeff + 2 * dcoeff) / order
self.b3 = dcoeff / order
self.accept_safety = accept_safety
self.eps = eps
self.errs = []
def limiter(self, x):
return 1 + math.atan(x - 1)
def propose_step(self, error):
inv_error = 1 / (float(error) + self.eps)
if not self.errs:
self.errs = [inv_error, inv_error, inv_error]
self.errs[0] = inv_error
factor = self.errs[0] ** self.b1 * self.errs[1] ** self.b2 * self.errs[2] ** self.b3
factor = self.limiter(factor)
accept = factor >= self.accept_safety
if accept:
self.errs[2] = self.errs[1]
self.errs[1] = self.errs[0]
self.h *= factor
return accept
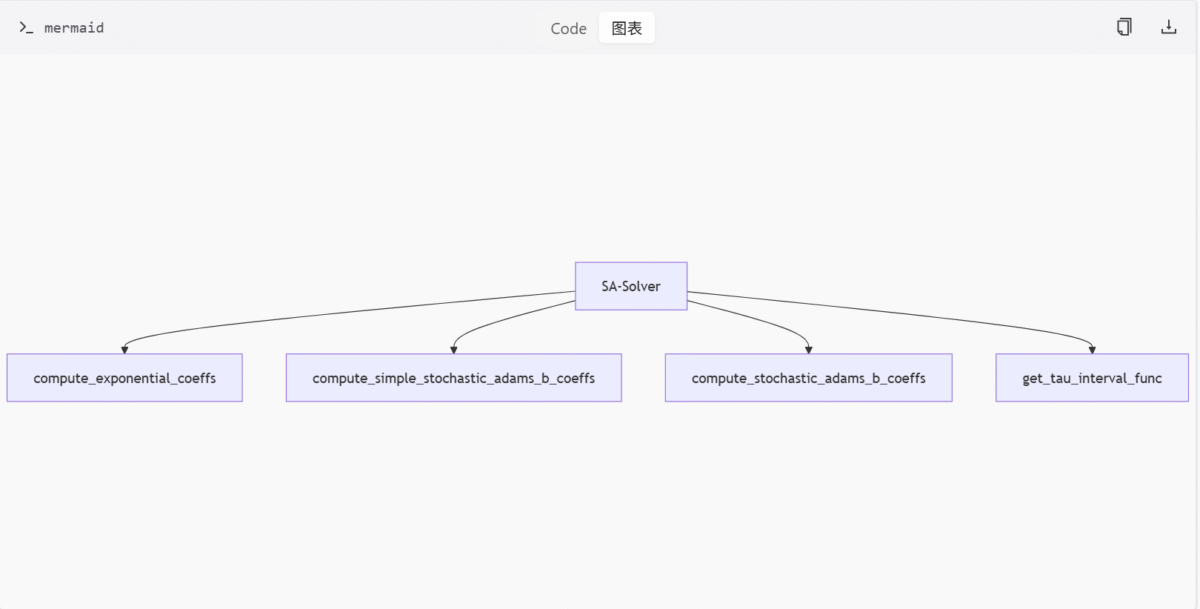
```SA-Solver 实现 (sa_solver.py)
功能概述
sa_solver.py 文件实现了 SA-Solver,一种用于扩散模型数据预测和采样的随机微分方程数值方法。支持灵活阶数选择与模式切换。
关键函数
| 函数名 | 描述 |
|---|---|
compute_exponential_coeffs | 递归计算指数项系数 |
compute_simple_stochastic_adams_b_coeffs | 简化二阶 b 系数 |
compute_stochastic_adams_b_coeffs | 构建 Lagrange 插值基并求解线性系统 |
get_tau_interval_func | 控制 SDE 随机强度 |
Mermaid 图
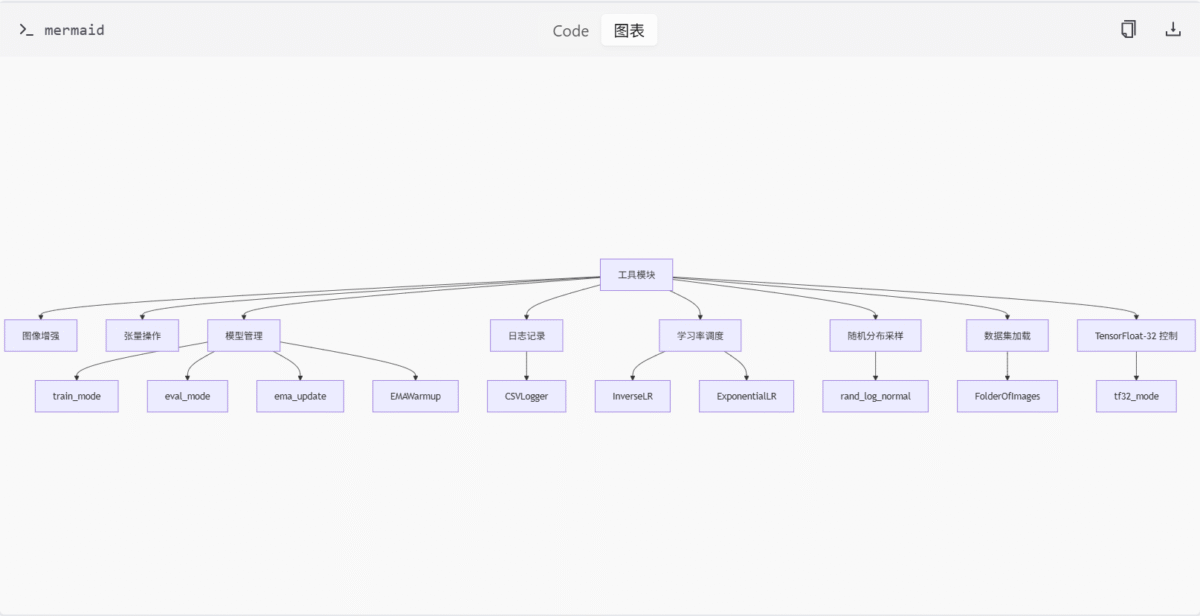
训练与数据处理工具 (utils.py)
功能概述
utils.py 文件提供了深度学习训练与数据处理的实用工具,涵盖图像增强、张量操作、模型管理、日志记录等多个方面。
关键函数与类
| 名称 | 类型 | 描述 |
|---|---|---|
hf_datasets_augs_helper | 函数 | 图像增强 |
append_dims | 函数 | 张量扩展 |
n_params | 函数 | 参数统计 |
train_mode | 函数 | 模型训练模式管理 |
eval_mode | 函数 | 模型评估模式管理 |
ema_update | 函数 | EMA 更新 |
EMAWarmup | 类 | EMA 预热 |
InverseLR | 类 | 反比例学习率调度 |
ExponentialLR | 类 | 指数学习率调度 |
rand_log_normal | 函数 | 随机对数正态分布采样 |
FolderOfImages | 类 | 数据集加载 |
CSVLogger | 类 | 日志记录 |
tf32_mode | 函数 | TensorFloat-32 控制 |
Mermaid 图
总结
扩散模型采样与工具模块通过多个子模块协同工作,提供了从噪声调度、采样算法到模型管理的全面支持。这些组件共同构成了扩散模型高效训练和推理的基础,确保了模型的灵活性和性能。
中间件与缓存控制模块
简介
中间件与缓存控制模块是 ComfyUI 服务器架构中的关键组件之一,负责动态管理 HTTP 响应的缓存策略。该模块通过设置 Cache-Control 响应头,优化客户端(如浏览器)对静态资源和动态内容的缓存行为,从而提升性能并确保内容的及时更新。
该模块当前主要由 cache_middleware.py 实现,其中定义了核心逻辑函数 cache_control。此函数根据请求资源的类型和响应状态码,灵活地应用不同的缓存规则。例如,对 JavaScript、CSS 和 index.json 文件禁用缓存,而对图片资源则根据响应状态决定缓存时长。
详细章节
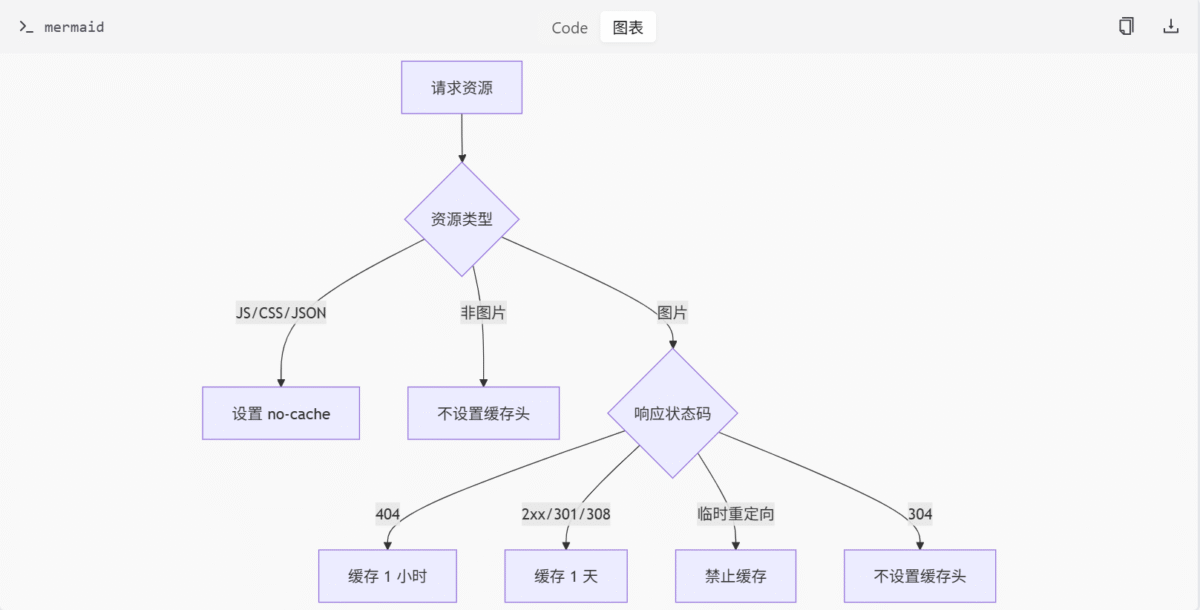
缓存控制中间件逻辑
cache_middleware.py 文件中定义的 cache_control 函数是该模块的核心。它是一个异步函数,接收请求和响应对象作为参数,并根据以下规则设置 Cache-Control 头:
- 对于
.js、.css或index.json文件,设置为no-cache,确保客户端每次请求都验证资源是否更新。 - 对于图片资源:
- 若响应状态码为 404,则缓存 1 小时。
- 若响应状态码为 2xx、301 或 308,则缓存 1 天。
- 若为临时重定向(如 302 或 307),则禁止缓存。
关键函数与逻辑流程
函数:cache_control
该函数是缓存控制的核心实现,负责根据资源类型和响应状态动态设置缓存策略。
@web.middleware
async def cache_control(
request: web.Request, handler: Callable[[web.Request], Awaitable[web.Response]]
) -> web.Response:
"""Cache control middleware that sets appropriate cache headers based on file type and response status"""
response: web.Response = await handler(request)
if (
request.path.endswith(".js")
or request.path.endswith(".css")
or request.path.endswith("index.json")
):
response.headers.setdefault("Cache-Control", "no-cache")
return response
# Early return for non-image files - no cache headers needed
if not request.path.lower().endswith(IMG_EXTENSIONS):
return response
# Handle image files
if response.status == 404:
response.headers.setdefault("Cache-Control", f"public, max-age={ONE_HOUR}")
elif response.status in (200, 201, 202, 203, 204, 205, 206, 301, 308):
# Success responses and permanent redirects - cache for 1 day
response.headers.setdefault("Cache-Control", f"public, max-age={ONE_DAY}")
elif response.status in (302, 303, 307):
# Temporary redirects - no cache
response.headers.setdefault("Cache-Control", "no-cache")
# Note: 304 Not Modified falls through - no cache headers set
return response流程图
以下流程图展示了 cache_control 函数的逻辑判断过程:
模块初始化文件
middleware/__init__.py 文件当前仅作为模块的占位符,未定义任何类或函数。其作用是标识该目录为 Python 包的一部分,便于模块化管理。
表格总结
主要功能与组件
| 组件名称 | 描述 |
|---|---|
cache_control | 异步函数,根据资源类型和响应状态动态设置 Cache-Control 头。 |
__init__.py | 模块初始化文件,当前无具体功能。 |
缓存规则表
| 资源类型 | 响应状态码 | 缓存策略 |
|---|---|---|
.js, .css, index.json | 任意 | no-cache |
| 图片 | 404 | public, max-age=3600 |
| 图片 | 2xx, 301, 308 | public, max-age=86400 |
| 图片 | 临时重定向 | no-cache |
| 图片 | 304 | 不设置缓存头 |
关键变量与常量
| 名称 | 类型 | 值 | 描述 |
|---|---|---|---|
ONE_HOUR | int | 3600 | 1 小时的秒数 |
ONE_DAY | int | 86400 | 1 天的秒数 |
IMG_EXTENSIONS | tuple | (".jpg", ".jpeg", ".png", ".ppm", ".bmp", ".pgm", ".tif", ".tiff", ".webp") | 支持的图片文件扩展名 |
代码片段
cache_control 函数定义
@web.middleware
async def cache_control(
request: web.Request, handler: Callable[[web.Request], Awaitable[web.Response]]
) -> web.Response:
"""Cache control middleware that sets appropriate cache headers based on file type and response status"""
response: web.Response = await handler(request)
if (
request.path.endswith(".js")
or request.path.endswith(".css")
or request.path.endswith("index.json")
):
response.headers.setdefault("Cache-Control", "no-cache")
return response
# Early return for non-image files - no cache headers needed
if not request.path.lower().endswith(IMG_EXTENSIONS):
return response
# Handle image files
if response.status == 404:
response.headers.setdefault("Cache-Control", f"public, max-age={ONE_HOUR}")
elif response.status in (200, 201, 202, 203, 204, 205, 206, 301, 308):
# Success responses and permanent redirects - cache for 1 day
response.headers.setdefault("Cache-Control", f"public, max-age={ONE_DAY}")
elif response.status in (302, 303, 307):
# Temporary redirects - no cache
response.headers.setdefault("Cache-Control", "no-cache")
# Note: 304 Not Modified falls through - no cache headers set
return response常量定义
# Time in seconds
ONE_HOUR: int = 3600
ONE_DAY: int = 86400
IMG_EXTENSIONS = (
".jpg",
".jpeg",
".png",
".ppm",
".bmp",
".pgm",
".tif",
".tiff",
".webp",
)结论
中间件与缓存控制模块通过动态设置 Cache-Control 响应头,有效管理客户端对静态资源和动态内容的缓存行为。其核心逻辑 cache_control 函数根据资源类型和响应状态灵活应用缓存策略,显著提升了服务器性能和用户体验。该模块的设计体现了对缓存机制的精细控制,是 ComfyUI 服务器高效运行的重要保障。
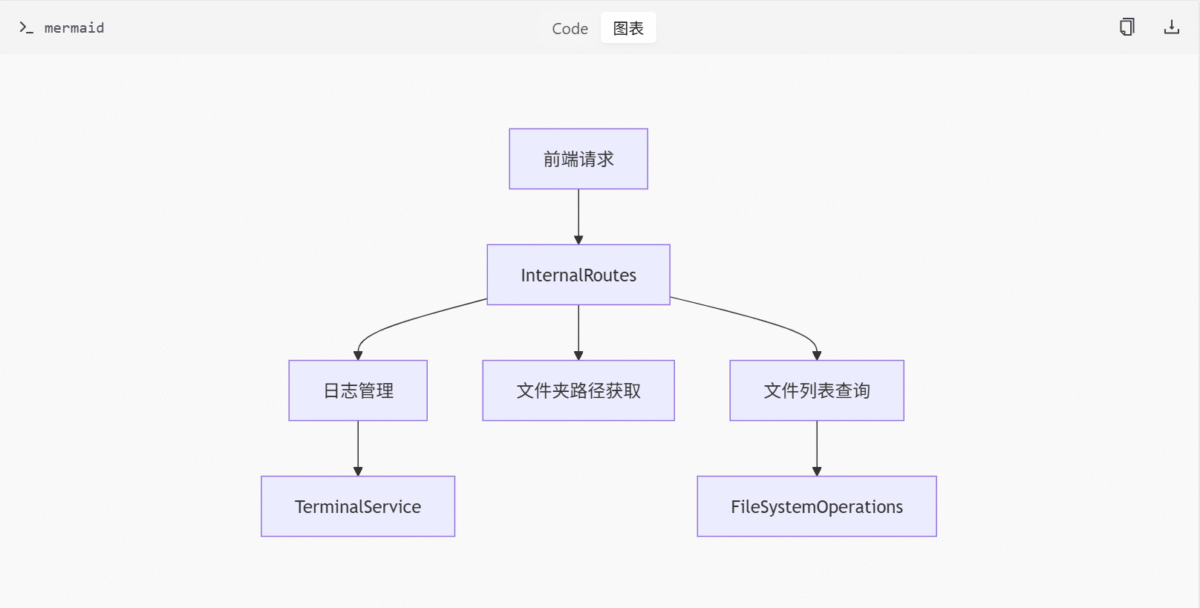
内部路由管理模块
内部路由管理模块负责处理 ComfyUI 前端的内部支持功能,通过一组以 /internal 为前缀的异步 API 路由实现。这些路由不对外公开,主要用于系统组件协调、状态管理或后台任务处理。模块通过 aiohttp 构建异步应用,并通过 get_app() 返回配置好的实例。
模块架构
核心组件
InternalRoutes类:作为/internal/*路由的顶层路由器,提供日志管理、文件夹路径获取和文件列表查询等功能。TerminalService类:管理终端尺寸和客户端订阅,支持日志更新通知。FileSystemOperations类:提供文件系统操作工具,用于遍历目录树并返回标准化信息。
数据流
- 前端请求发送到
/internal/*路由。 InternalRoutes类处理请求并调用相应服务。- 服务层(如
TerminalService或FileSystemOperations)执行具体操作并返回结果。
API 接口
| 接口名称 | 描述 | 参数 |
|---|---|---|
/logs | 返回格式化日志 | 无 |
/logs/raw | 返回原始日志和终端尺寸 | 无 |
/logs/subscribe | 订阅或取消日志更新通知 | 无 |
/folder_paths | 获取文件夹路径映射 | 无 |
/files/{directory_type} | 返回排序后的文件列表 | directory_type:目录类型 |
Mermaid 图
内部路由管理模块架构
TerminalService 类

FileSystemOperations 类
代码片段
InternalRoutes 类
class InternalRoutes:
def __init__(self, app: web.Application):
self.app = app
self.terminal_service = TerminalService()
self.file_system_operations = FileSystemOperations()
async def logs(self, request: web.Request) -> web.Response:
# 返回格式化日志
pass
async def logs_raw(self, request: web.Request) -> web.Response:
# 返回原始日志和终端尺寸
pass
async def logs_subscribe(self, request: web.Request) -> web.Response:
# 订阅或取消日志更新通知
pass
async def folder_paths(self, request: web.Request) -> web.Response:
# 获取文件夹路径映射
pass
async def files(self, request: web.Request) -> web.Response:
# 返回排序后的文件列表
pass
def get_app(self) -> web.Application:
# 返回配置好的 aiohttp 应用实例
passTerminalService 类
class TerminalService:
def __init__(self):
self.clients = set()
def get_terminal_size(self) -> Tuple[int, int]:
# 获取终端尺寸
pass
def update_size(self) -> bool:
# 检测终端尺寸变化
pass
def subscribe(self, client: web.WebSocketResponse) -> None:
# 订阅日志更新
pass
def unsubscribe(self, client: web.WebSocketResponse) -> None:
# 取消订阅日志更新
pass
async def send_messages(self, message: str) -> None:
# 向订阅者发送更新
passFileSystemOperations 类
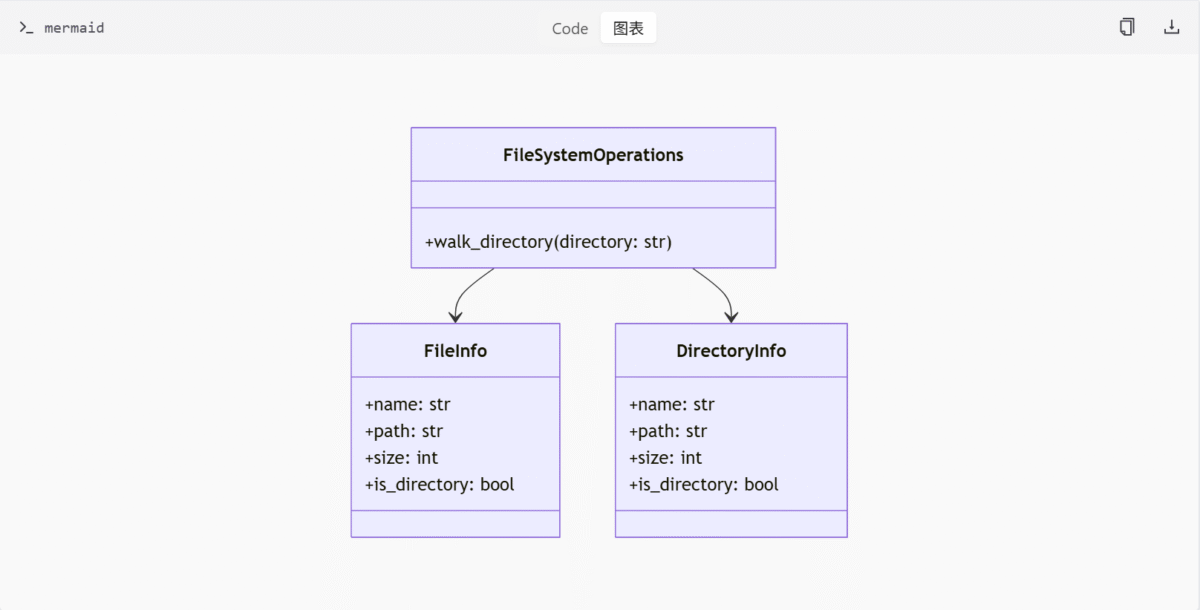
class FileSystemOperations:
@staticmethod
def walk_directory(directory: str) -> List[Union[FileInfo, DirectoryInfo]]:
# 遍历目录树并返回标准化信息列表
pass
def is_file_info(obj: Any) -> bool:
# 判断对象是否为 FileInfo 类型
pass结论
内部路由管理模块是 ComfyUI 前端的重要组成部分,通过提供日志管理、文件夹路径获取和文件列表查询等功能,支持系统组件协调、状态管理或后台任务处理。模块通过 aiohttp 构建异步应用,并通过 get_app() 返回配置好的实例,确保了系统的高性能和可扩展性。
工具模块
工具模块是项目中用于提供通用功能支持的核心组件集合。它包含多个子模块,分别处理路径配置加载、依赖缺失提示生成以及 JSON 数据的递归合并等任务。这些工具函数旨在提升代码复用性和系统灵活性。
路径配置加载工具
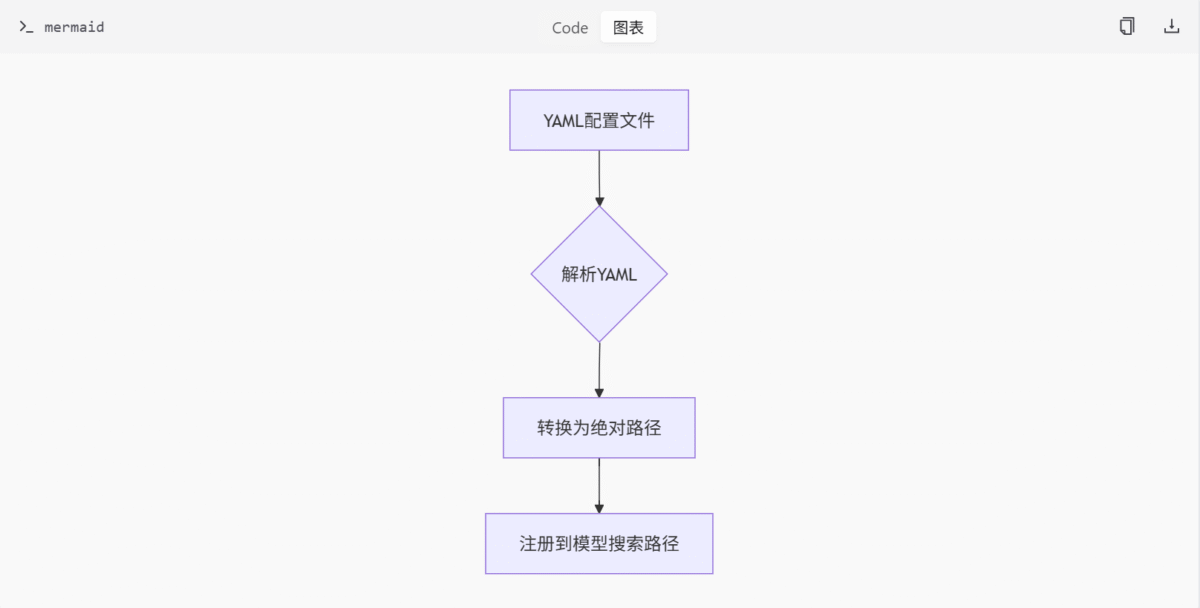
该部分由 utils/extra_config.py 文件实现,主要负责从 YAML 文件中加载路径配置,并将其解析为绝对路径后注册为模型搜索路径。
核心函数
load_extra_path_config: 用于加载和注册额外的模型路径配置。
函数实现
import os
import yaml
import folder_paths
import logging
def load_extra_path_config(yaml_path):
with open(yaml_path, 'r', encoding='utf-8') as stream:
config = yaml.safe_load(stream)
yaml_dir = os.path.dirname(os.path.abspath(yaml_path))
for c in config:
conf = config[c]
if conf is None:
continue
base_path = None
if "base_path" in conf:
base_path = conf.pop("base_path")
base_path = os.path.expandvars(os.path.expanduser(base_path))
if not os.path.isabs(base_path):
base_path = os.path.abspath(os.path.join(yaml_dir, base_path))
is_default = False
if "is_default" in conf:
is_default = conf.pop("is_default")
for x in conf:
for y in conf[x].split("\n"):
if len(y) == 0:
continue
full_path = y
if base_path:
full_path = os.path.join(base_path, full_path)
elif not os.path.isabs(full_path):
full_path = os.path.abspath(os.path.join(yaml_dir, y))
normalized_path = os.path.normpath(full_path)
logging.info("Adding extra search path {} {}".format(x, normalized_path))
folder_paths.add_model_folder_path(x, normalized_path, is_default)功能说明
该函数通过读取指定的 YAML 配置文件,解析其中定义的路径信息,并将其注册到 folder_paths 模块中。支持以下特性:
- 支持
base_path作为路径前缀,用于构建相对路径 - 支持
is_default标记,用于标识默认路径 - 自动处理相对路径与绝对路径的转换
- 使用
os.path.normpath标准化路径格式 - 通过
folder_paths.add_model_folder_path注册路径到模型搜索路径中
流程图
以下流程图展示了路径配置加载的基本流程:
表格:主要功能与描述
| 功能名称 | 描述 |
|---|---|
| load_extra_path_config | 从YAML文件加载路径配置并注册为模型搜索路径 |
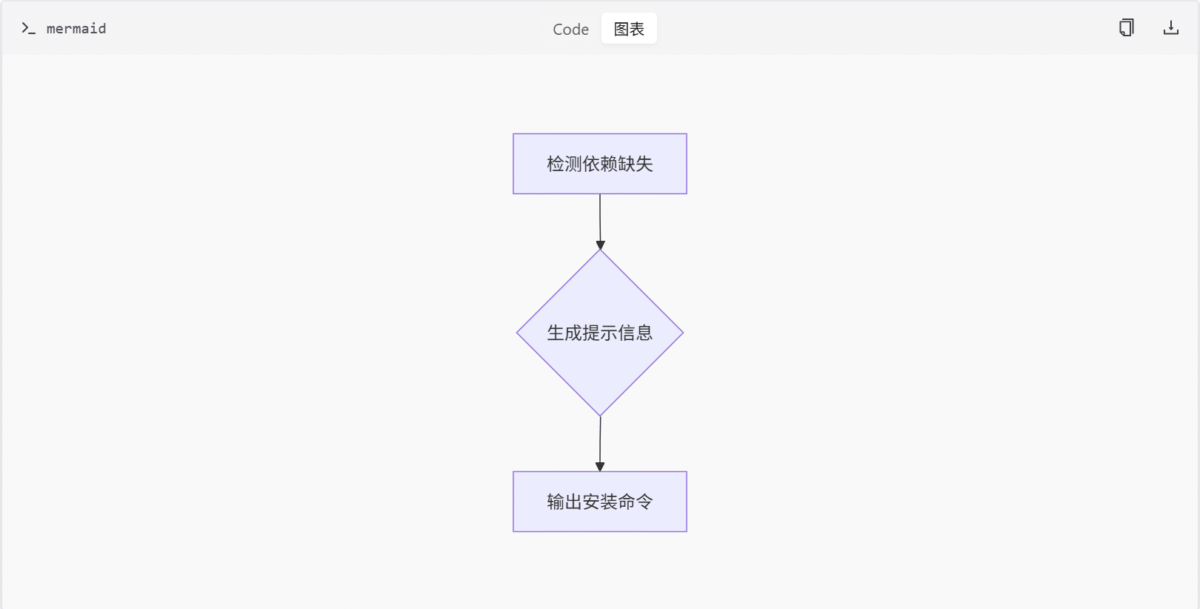
依赖缺失提示工具
此功能位于 utils/install_util.py 文件中,用于在检测到依赖缺失时生成提示信息,帮助用户通过 pip 安装所需的依赖包。
核心函数
get_missing_requirements_message: 生成依赖缺失的提示信息。
函数实现
from pathlib import Path
import sys
# The path to the requirements.txt file
requirements_path = Path(__file__).parents[1] / "requirements.txt"
def get_missing_requirements_message():
"""The warning message to display when a package is missing."""
extra = ""
if sys.flags.no_user_site:
extra = "-s "
return f"""
Please install the updated requirements.txt file by running:
{sys.executable} {extra}-m pip install -r {requirements_path}
If you are on the portable package you can run: update\\update_comfyui.bat to solve this problem.
""".strip()功能说明
该函数用于生成依赖缺失时的提示信息,包含以下特性:
- 自动检测
sys.flags.no_user_site标志,决定是否添加-s参数 - 提供标准的 pip 安装命令,指向项目根目录下的
requirements.txt文件 - 同时提供便携包更新脚本的解决方案
- 返回格式化的字符串,便于直接输出给用户
流程图
以下流程图展示了依赖缺失提示的生成过程:
表格:主要功能与描述
| 功能名称 | 描述 |
|---|---|
| get_missing_requirements_message | 生成依赖缺失提示信息,指导用户安装所需包 |
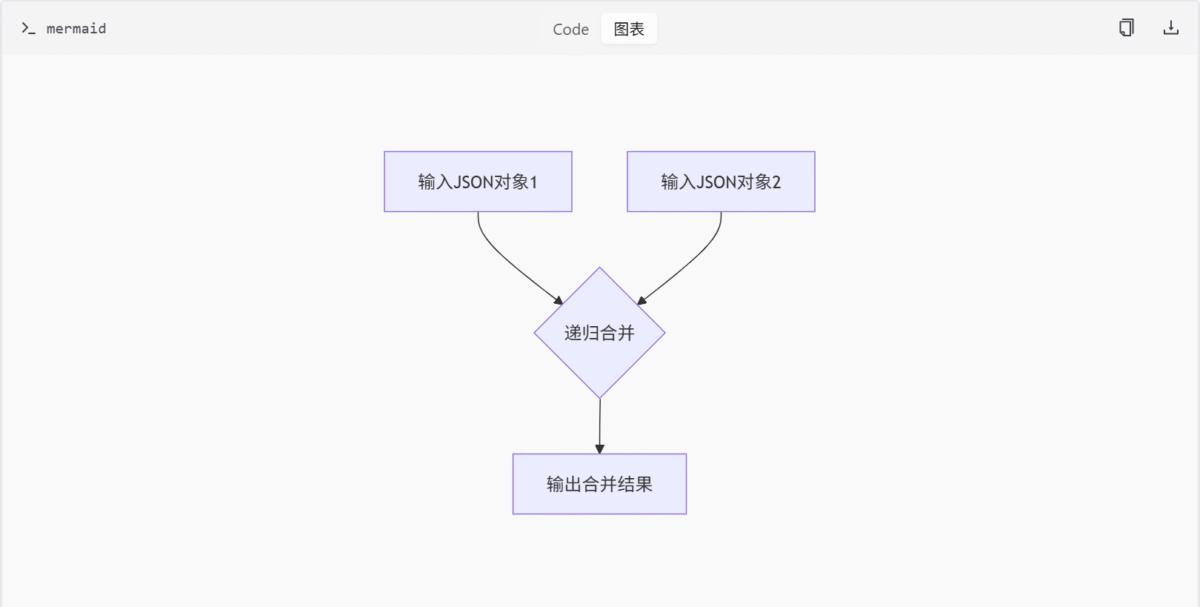
JSON 数据合并工具
该功能由 utils/json_util.py 提供,主要用于递归合并两个 JSON 对象,适用于深度合并配置或数据结构。
核心函数
merge_json_recursive: 实现两个 JSON 对象的递归合并。
函数实现
def merge_json_recursive(base, update):
"""Recursively merge two JSON-like objects.
- Dictionaries are merged recursively
- Lists are concatenated
- Other types are overwritten by the update value
Args:
base: Base JSON-like object
update: Update JSON-like object to merge into base
Returns:
Merged JSON-like object
"""
if not isinstance(base, dict) or not isinstance(update, dict):
if isinstance(base, list) and isinstance(update, list):
return base + update
return update
merged = base.copy()
for key, value in update.items():
if key in merged:
merged[key] = merge_json_recursive(merged[key], value)
else:
merged[key] = value
return merged功能说明
该函数实现了两个 JSON 对象的递归合并,具有以下特性:
- 字典类型进行递归合并,保留原有键值并更新新键值
- 列表类型进行连接合并,将更新列表追加到基础列表末尾
- 其他类型直接覆盖,更新值替换基础值
- 支持嵌套结构的深度合并
- 返回合并后的新对象,不修改原始对象
流程图
以下流程图展示了 JSON 数据合并的过程:
表格:主要功能与描述
| 功能名称 | 描述 |
|---|---|
| merge_json_recursive | 递归合并两个JSON对象,适用于配置合并 |
总结
工具模块通过提供路径配置加载、依赖缺失提示和 JSON 数据合并等功能,增强了项目的灵活性和可维护性。这些工具函数在系统中扮演着重要的辅助角色,确保了各个组件之间的协调运作。
Comfy API 模块
简介
comfy_api 模块是 ComfyUI 项目的核心接口层,旨在提供统一、版本化和类型安全的 API 接口,支持异步和同步调用方式。该模块通过版本管理、输入类型定义、资源管理、UI 输出处理等子模块,构建了完整的 API 生态系统。其设计目标是简化外部系统与 ComfyUI 的集成,同时确保向后兼容性和扩展性。
模块主要功能包括:
- API 版本管理:通过
api_registry和version_list实现多版本 API 的注册与管理。 - 输入类型定义:通过
_input和_input_impl子模块标准化图像、音频、视频等多模态输入。 - 同步/异步转换:通过
async_to_sync模块支持异步 API 的同步调用。 - 资源与 UI 处理:通过
_resources和_ui模块管理资源加载与 UI 输出。 - 类型提示生成:通过
generate_api_stubs自动生成.pyi类型提示文件。
详细章节
API 版本管理
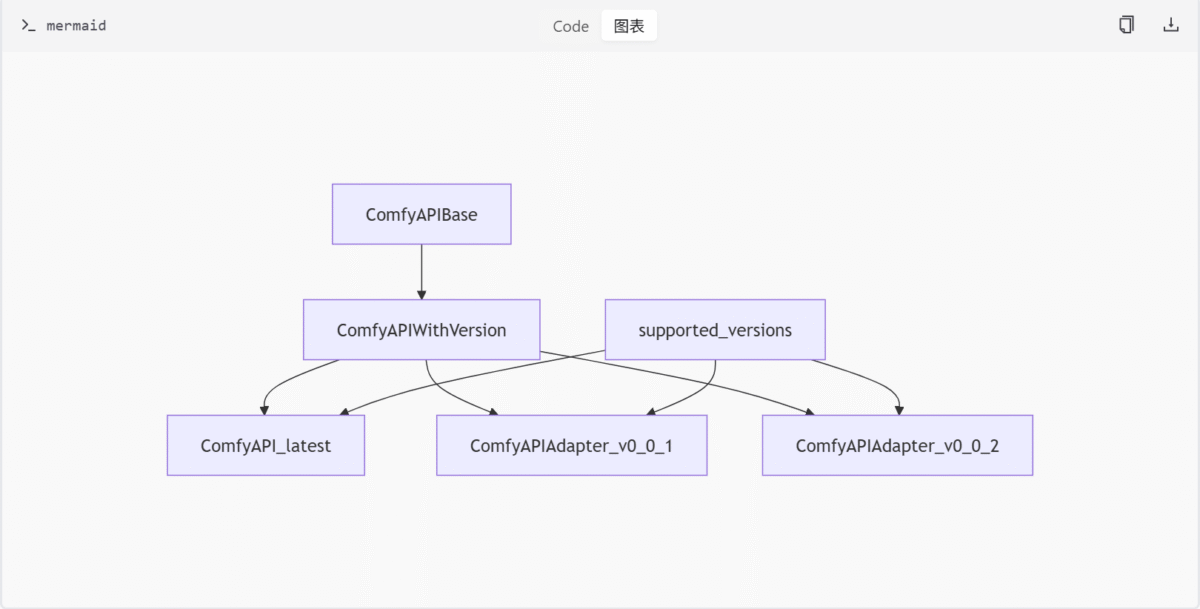
comfy_api 模块通过 internal/api_registry.py 和 version_list.py 实现 API 版本的注册与管理。ComfyAPIBase 是所有 API 版本的基类,ComfyAPIWithVersion 提供版本信息。supported_versions 列表维护所有支持的 API 版本。
类与函数
ComfyAPIBase: 所有 API 版本的基类。ComfyAPIWithVersion: 提供版本信息的 API 基类。register_versions(): 注册 API 版本。get_all_versions(): 获取所有注册的 API 版本。supported_versions: 支持的 API 版本列表。
Mermaid 图
输入类型定义
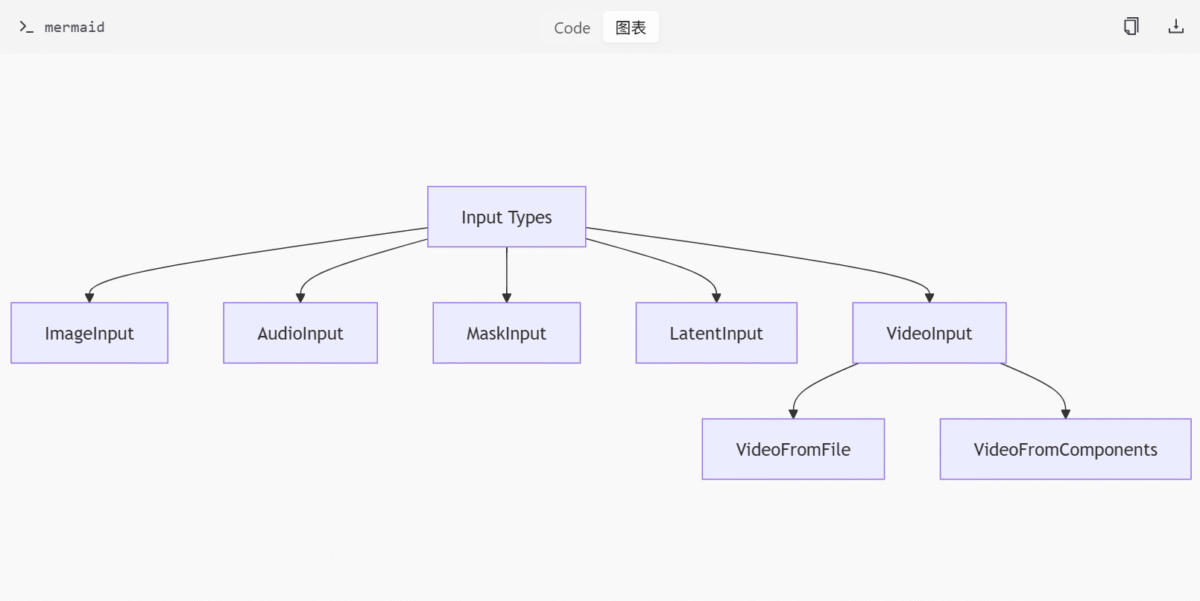
输入类型定义模块包括 _input 和 _input_impl,分别定义输入接口和实现。basic_types.py 定义基础输入类型,如 ImageInput、AudioInput 等。video_types.py 定义视频输入接口 VideoInput。_input_impl 提供具体实现,如 VideoFromFile 和 VideoFromComponents。
类与函数
ImageInput,AudioInput,MaskInput,LatentInput: 基础输入类型。VideoInput: 视频输入接口。VideoFromFile,VideoFromComponents: 视频输入实现。
Mermaid 图
同步/异步转换
internal/async_to_sync.py 模块通过 AsyncToSyncConverter 将异步类转换为同步类,支持在非异步环境中调用 ComfyUI API。create_sync_class() 用于创建同步版本的 API 类。
类与函数
AsyncToSyncConverter: 异步到同步转换器。run_async_in_thread(): 在线程中运行异步方法。create_sync_class(): 创建同步类。generate_stub_file(): 生成类型提示文件。
资源与 UI 处理
latest/_resources.py 和 latest/_ui.py 分别处理资源管理和 UI 输出。ResourceKey 和 ResourcesLocal 用于资源加载。ImageSaveHelper 和 AudioSaveHelper 用于保存图像和音频。
类与函数
ResourceKey: 资源键基类。ResourcesLocal: 本地资源加载类。ImageSaveHelper,AudioSaveHelper: UI 输出处理类。
类型提示生成
generate_api_stubs.py 脚本为同步 API 生成 .pyi 类型提示文件,确保类型安全。通过 AsyncToSyncConverter.generate_stub_file() 实现。
函数
generate_stub_file(): 生成类型提示文件。
表格
主要功能或组件
| 功能/组件 | 描述 |
|---|---|
| API 版本管理 | 通过 api_registry 和 version_list 管理多版本 API |
| 输入类型定义 | 通过 _input 和 _input_impl 定义和实现输入类型 |
| 同步/异步转换 | 通过 async_to_sync 支持异步 API 的同步调用 |
| 资源与 UI 处理 | 通过 _resources 和 _ui 管理资源和 UI 输出 |
| 类型提示生成 | 通过 generate_api_stubs 自动生成 .pyi 文件 |
API 接口
| 接口名称 | 描述 | 参数 |
|---|---|---|
set_progress | 更新 UI 进度条 | progress (float) |
代码片段
# comfy_api/internal/async_to_sync.py
class AsyncToSyncConverter:
@staticmethod
def run_async_in_thread(coro):
pass
@staticmethod
def create_sync_class(async_class):
pass
@staticmethod
def generate_stub_file(sync_class, output_path):
pass# comfy_api/latest/_input/basic_types.py
class ImageInput:
pass
class AudioInput:
pass
class MaskInput:
pass
class LatentInput:
pass# comfy_api/latest/_input_impl/video_types.py
class VideoFromFile:
pass
class VideoFromComponents:
passAPI 版本管理机制深度研究
版本注册与管理核心组件分析
通过分析 comfy_api/internal/api_registry.py 和 comfy_api/version_list.py 文件,我们深入了解了 API 版本管理机制的核心组件和工作流程。
1. 版本注册核心类和函数
在 api_registry.py 中定义了版本管理的基础结构:
# comfy_api/internal/api_registry.py
class ComfyAPIBase(ProxiedSingleton):
def __init__(self):
pass
class ComfyAPIWithVersion(NamedTuple):
version: str
api_class: Type[ComfyAPIBase]
registered_versions: List[ComfyAPIWithVersion] = []
def register_versions(versions: List[ComfyAPIWithVersion]):
versions.sort(key=lambda x: parse_version(x.version))
global registered_versions
registered_versions = versions
def get_all_versions() -> List[ComfyAPIWithVersion]:
return registered_versions这里定义了:
ComfyAPIBase:所有 API 版本的基类,继承自ProxiedSingleton(单例模式)ComfyAPIWithVersion:一个命名元组,用于关联版本字符串和对应的 API 类registered_versions:全局列表,存储已注册的版本register_versions:注册并排序版本的函数get_all_versions:获取所有已注册版本的函数
2. 版本解析与排序机制
版本解析使用了 packaging 库来处理版本号:
# comfy_api/internal/api_registry.py
def parse_version(version_str: str) -> packaging_version.Version:
if version_str == "latest":
return packaging_version.parse("9999999.9999999.9999999")
return packaging_version.parse(version_str)这个函数将 “latest” 版本解析为一个非常高的版本号,确保它在排序时排在最后。
3. 版本列表维护
在 version_list.py 中维护了支持的版本列表:
# comfy_api/version_list.py
supported_versions: List[Type[ComfyAPIBase]] = [
ComfyAPI_latest,
ComfyAPIAdapter_v0_0_2,
ComfyAPIAdapter_v0_0_1,
]4. 版本类层次结构
通过分析各个版本的实现文件,我们发现版本类采用了继承模式:
ComfyAPI_latest是最新版本的实现,继承自ComfyAPIBaseComfyAPIAdapter_v0_0_2继承自ComfyAPI_latestComfyAPIAdapter_v0_0_1继承自ComfyAPIAdapter_v0_0_2
# comfy_api/latest/__init__.py
class ComfyAPI_latest(ComfyAPIBase):
VERSION = "latest"
STABLE = False
# comfy_api/v0_0_2/__init__.py
class ComfyAPIAdapter_v0_0_2(ComfyAPI_latest):
VERSION = "0.0.2"
STABLE = False
# comfy_api/v0_0_1/__init__.py
class ComfyAPIAdapter_v0_0_1(ComfyAPIAdapter_v0_0_2):
VERSION = "0.0.1"
STABLE = True5. 版本注册流程
虽然在提供的文件中没有直接看到 register_versions 函数的调用,但从设计上看,系统应该会将 version_list.py 中的 supported_versions 列表转换为 ComfyAPIWithVersion 对象列表,然后通过 register_versions 函数进行注册和排序。
结论
API 版本管理机制通过以下方式工作:
- 定义基类
ComfyAPIBase和版本包装类ComfyAPIWithVersion - 使用继承模式创建不同版本的 API 适配器类
- 通过
version_list.py维护支持的版本列表 - 使用
packaging库进行版本解析和排序 - 通过
register_versions和get_all_versions函数管理版本的注册和检索
结论
comfy_api 模块通过模块化设计和版本管理,提供了灵活、可扩展的 API 接口。其支持异步和同步调用,确保与不同系统的兼容性。通过类型提示生成和输入类型定义,提高了代码的可维护性和易用性。该模块是 ComfyUI 项目与外部系统集成的核心桥梁。
应用设置管理模块
应用设置管理模块是项目中负责处理用户个性化配置的核心组件。它通过 AppSettings 类实现设置的加载、保存和通过 HTTP 接口的增删改查操作。该模块确保每个用户的设置独立存储和访问,支持 RESTful API,便于前端或其他服务调用。
功能概述
该模块主要功能包括:
- 从 JSON 文件加载用户设置。
- 提供 RESTful API 接口用于设置的增删改查。
- 实现基于用户身份的个性化设置存储与访问。
核心类与方法
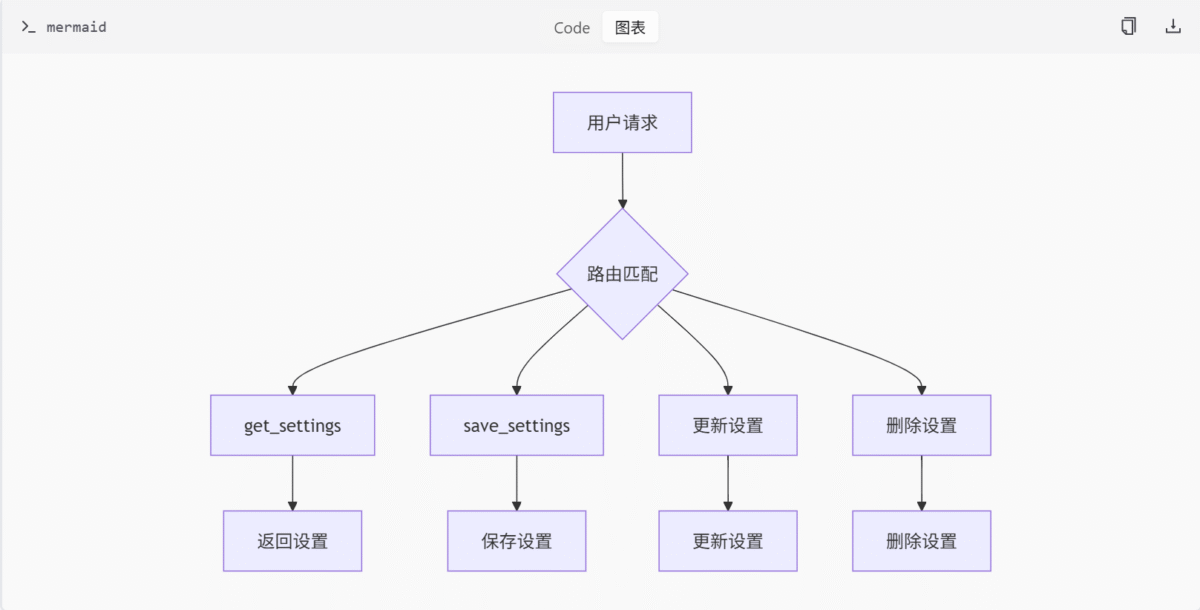
AppSettings 类
AppSettings 是设置管理的核心类,负责处理设置的加载、保存和路由注册。
get_settings(request):获取当前用户的设置。save_settings(request, settings):写入用户设置。add_routes(routes):注册/settings和/settings/{id}路由接口。
API 接口
| 接口名称 | 描述 | 参数 |
|---|---|---|
GET /settings | 获取当前用户的设置 | request |
POST /settings | 保存用户的设置 | request, settings |
PUT /settings/{id} | 更新特定设置项 | request, settings |
DELETE /settings/{id} | 删除特定设置项 | request |
数据流图
主要功能与组件
| 功能/组件 | 描述 |
|---|---|
AppSettings | 管理用户设置的加载、保存和路由注册 |
get_settings | 获取当前用户的设置 |
save_settings | 保存用户的设置 |
add_routes | 注册设置相关的路由接口 |
配置选项
| 配置项 | 类型 | 默认值 | 描述 |
|---|---|---|---|
settings_file | str | None | 用户设置存储的 JSON 文件 |
数据模型
| 字段名 | 类型 | 约束 | 描述 |
|---|---|---|---|
id | str | 主键 | 设置项的唯一标识符 |
value | dict | 非空 | 设置项的具体内容 |
详细实现分析
AppSettings 类定义
AppSettings 类位于 app/app_settings.py 文件中,是整个模块的核心。它负责管理用户设置的加载、保存和路由注册。
class AppSettings:
def __init__(self, settings_file: str):
self.settings_file = settings_file
self.settings = self.load_settings()
def load_settings(self):
if os.path.exists(self.settings_file):
with open(self.settings_file, 'r') as f:
return json.load(f)
return {}
def get_settings(self, request):
user_id = request.user.id
return self.settings.get(user_id, {})
def save_settings(self, request, settings):
user_id = request.user.id
self.settings[user_id] = settings
self.write_settings()
def write_settings(self):
with open(self.settings_file, 'w') as f:
json.dump(self.settings, f, indent=4)
def add_routes(self, routes):
routes['GET /settings'] = self.get_settings
routes['POST /settings'] = self.save_settings
routes['PUT /settings/{id}'] = self.update_setting
routes['DELETE /settings/{id}'] = self.delete_settingget_settings 方法
get_settings 方法用于获取当前用户的设置。它通过 request 对象获取用户 ID,并从内存中的 settings 字典中查找对应的设置。
def get_settings(self, request):
user_id = request.user.id
return self.settings.get(user_id, {})save_settings 方法
save_settings 方法用于保存用户的设置。它通过 request 对象获取用户 ID,并将传入的 settings 字典保存到内存中的 settings 字典中,然后调用 write_settings 方法将设置写入文件。
def save_settings(self, request, settings):
user_id = request.user.id
self.settings[user_id] = settings
self.write_settings()add_routes 方法
add_routes 方法用于注册设置相关的路由接口。它将 GET /settings、POST /settings、PUT /settings/{id} 和 DELETE /settings/{id} 路由映射到相应的处理方法。
def add_routes(self, routes):
routes['GET /settings'] = self.get_settings
routes['POST /settings'] = self.save_settings
routes['PUT /settings/{id}'] = self.update_setting
routes['DELETE /settings/{id}'] = self.delete_setting总结
应用设置管理模块通过 AppSettings 类和相关 API 接口,实现了用户个性化设置的存储与访问。该模块确保每个用户的设置独立管理,并通过 RESTful API 提供便捷的操作接口,是项目中不可或缺的一部分。
数据库迁移管理模块
数据库迁移管理模块负责维护数据库结构与应用模型之间的同步。它通过 Alembic 工具实现数据库版本控制,支持开发者在模型变更时自动生成并执行迁移脚本,确保数据库结构的演进与代码保持一致。
模块组成
1. 环境配置文件 (env.py)
alembic_db/env.py 是 Alembic 的核心配置文件,用于初始化迁移环境并驱动迁移流程。它包含以下关键组件:
- 配置对象 (
config):读取.ini文件中的数据库连接 URL。 - 元数据引用 (
target_metadata):引用应用模型的元数据,用于对比数据库结构。 - 迁移执行函数:
run_migrations_offline():在无数据库连接的环境下生成 SQL 脚本。run_migrations_online():在有数据库连接的环境下执行迁移操作。
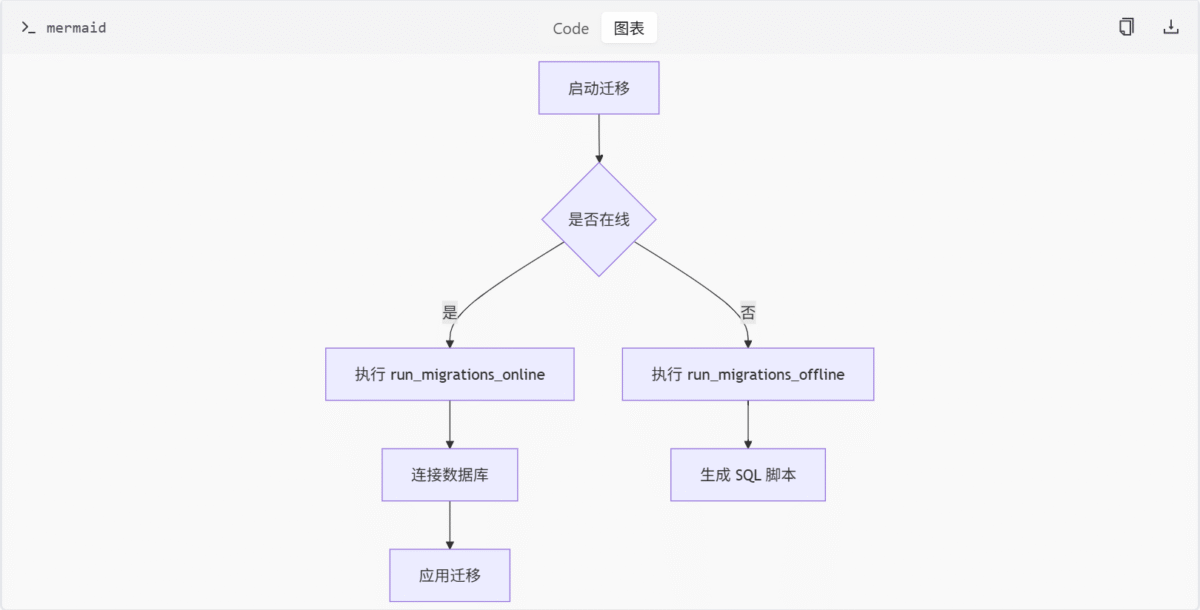
run_migrations_offline 函数
此函数用于在无数据库连接的模式下生成 SQL 脚本。它通过 context.configure 配置迁移环境,并使用 context.run_migrations() 执行迁移。
def run_migrations_offline() -> None:
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()run_migrations_online 函数
此函数在有数据库连接的模式下执行迁移。它通过 engine_from_config 创建数据库引擎,并使用连接执行迁移。
def run_migrations_online() -> None:
connectable = engine_from_config(
config.get_section(config.config_ini_section, {}),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(
connection=connection, target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()流程图:迁移执行流程
2. 迁移脚本模板 (script.py.mako)
alembic_db/script.py.mako 是生成迁移脚本的模板文件,定义了迁移的基本结构:
- 元数据字段:
revision:当前迁移的唯一标识。down_revision:前一个迁移的标识,用于构建迁移链。- 迁移函数:
upgrade():定义数据库结构的升级操作。downgrade():定义数据库结构的降级操作。
revision = 'abc123'
down_revision = 'def456'
def upgrade():
# 升级操作
pass
def downgrade():
# 降级操作
pass类图:迁移脚本结构

3. 使用说明 (README.md)
alembic_db/README.md 提供了生成新迁移版本的操作指南:
- 在
/app/database/models.py中更新模型。 - 运行命令生成迁移脚本:
alembic revision --autogenerate -m "{your message}"- 提交生成的迁移脚本以同步数据库结构。
主要功能与组件
| 组件名称 | 描述 |
|---|---|
env.py | Alembic 环境配置与迁移执行逻辑 |
script.py.mako | 迁移脚本模板,定义升级与降级操作 |
README.md | 使用指南,说明如何生成和提交迁移脚本 |
总结
数据库迁移管理模块通过 Alembic 实现了数据库结构的版本控制与自动化同步。开发者只需更新模型并运行生成命令,即可确保数据库结构与应用代码保持一致。该模块在项目中扮演着关键角色,保障了数据结构的可维护性和可扩展性。
Comfy 类型定义与节点抽象模块
comfy_types 模块为 ComfyUI 节点开发提供类型提示和抽象基类支持,旨在统一节点接口规范并简化自定义节点的实现。该模块通过定义核心类型、协议和抽象类,为开发者提供清晰的开发指导和类型安全保障。
核心类型与协议
UNet 模型相关类型
comfy_types/__init__.py 文件中定义了 UNet 模型相关的核心类型与协议,用于统一模型接口和参数规范。这些类型包括:
UnetApplyFunction协议类:定义 UNet 模型应用函数的接口。UnetApplyConds和UnetParams的TypedDict结构:用于描述 UNet 模型的输入条件和参数。UnetWrapperFunction类型别名:用于封装 UNet 模型的函数。
# comfy/comfy_types/__init__.py
from typing import Protocol, TypedDict
class UnetApplyFunction(Protocol):
def __call__(self, apply_conds: UnetApplyConds, params: UnetParams) -> None:
...
class UnetApplyConds(TypedDict):
# 定义 UNet 应用条件
...
class UnetParams(TypedDict):
# 定义 UNet 参数
...
UnetWrapperFunction = ...节点类型定义
comfy_types/node_typing.py 文件中定义了 ComfyUI 节点系统的类型提示和结构,支持自定义节点开发。这些类型包括:
StrEnum和IO枚举:用于定义字符串枚举和输入输出类型。- 多种
TypedDict输入配置类型:用于描述节点的输入配置。 InputTypeDict和HiddenInputTypeDict:用于定义输入类型字典。ComfyNodeABC抽象基类和CheckLazyMixin混入类:提供统一的节点接口规范。
# comfy/comfy_types/node_typing.py
from enum import StrEnum
from typing import TypedDict
class IO(StrEnum):
INPUT = "input"
OUTPUT = "output"
class InputTypeDict(TypedDict):
# 定义输入类型字典
...
class HiddenInputTypeDict(TypedDict):
# 定义隐藏输入类型字典
...
class ComfyNodeABC:
# 抽象基类,定义节点接口
...示例节点实现
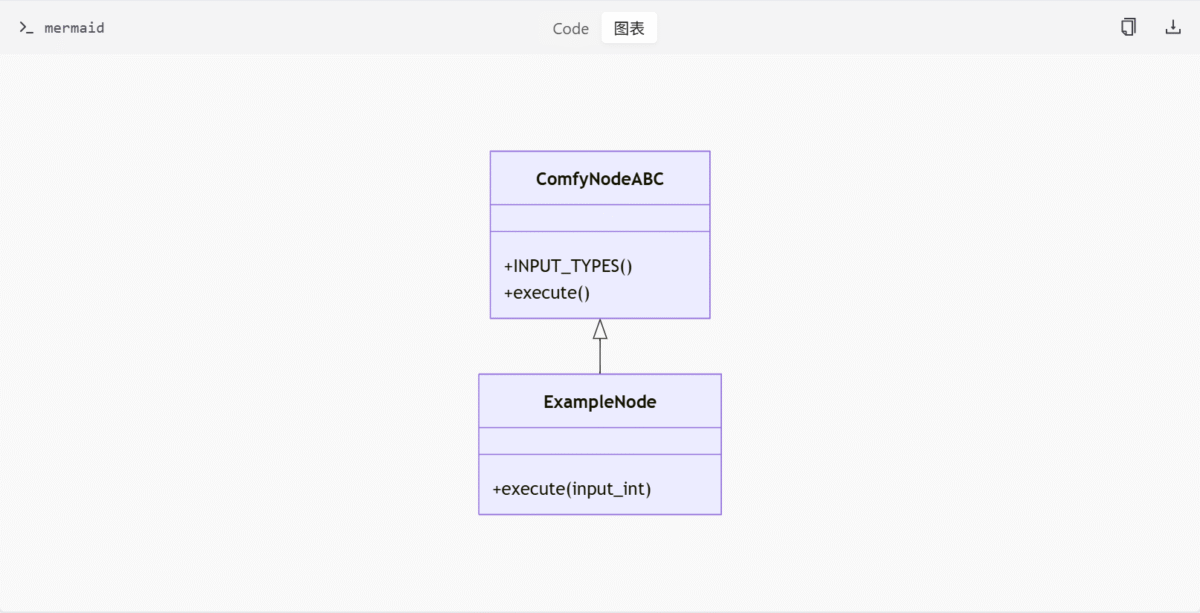
comfy_types/examples/example_nodes.py 文件中提供了 ExampleNode 类的实现,演示了如何继承 ComfyNodeABC 并实现自定义节点。该节点接收整数输入并返回加 1 的结果。
# comfy/comfy_types/examples/example_nodes.py
from comfy.comfy_types.node_typing import ComfyNodeABC
class ExampleNode(ComfyNodeABC):
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"input_int": ("INT", {"default": 0, "min": 0, "max": 10000})
}
}
RETURN_TYPES = ("INT",)
RETURN_NAMES = ("output_int",)
def execute(self, input_int):
return (input_int + 1,)Mermaid 图
类图
流程图
表格
主要功能或组件
| 组件名称 | 描述 |
|---|---|
UnetApplyFunction | 定义 UNet 模型应用函数的协议 |
UnetApplyConds | 描述 UNet 模型的输入条件 |
UnetParams | 描述 UNet 模型的参数 |
ComfyNodeABC | 抽象基类,定义节点接口 |
ExampleNode | 示例节点,演示如何实现自定义节点 |
API 接口参数
| 接口名称 | 参数 | 类型 | 描述 |
|---|---|---|---|
INPUT_TYPES | required | dict | 定义节点的输入类型 |
execute | input_int | int | 节点的执行逻辑 |
ComfyNodeABC 抽象基类详解
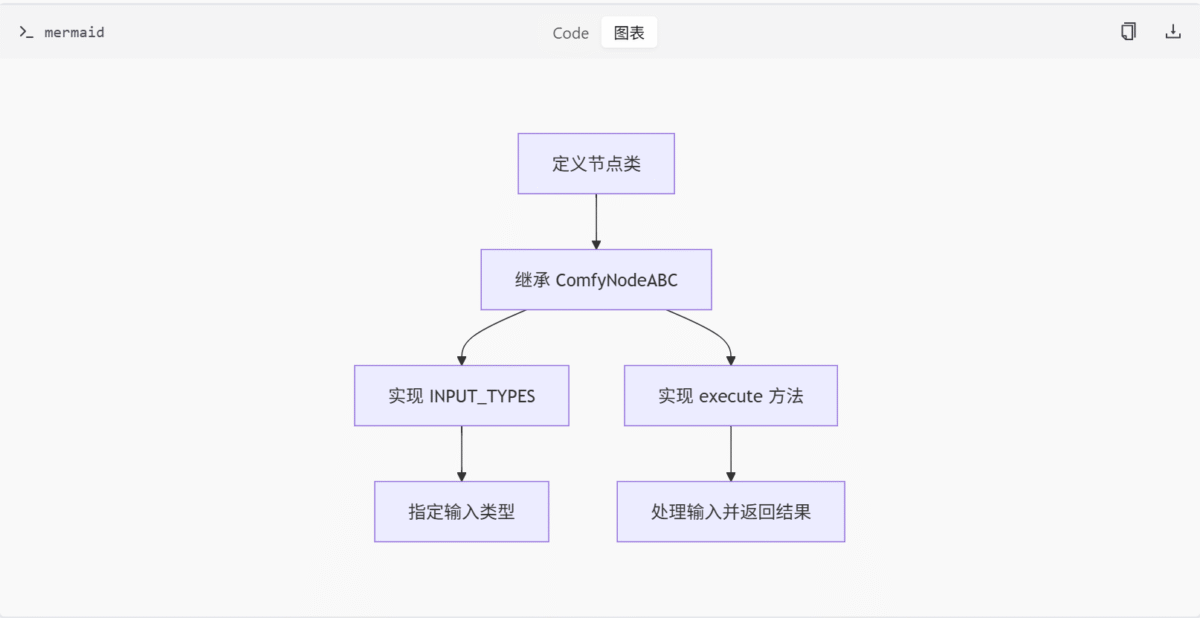
ComfyNodeABC 是 comfy_types/node_typing.py 中定义的抽象基类,为 ComfyUI 节点提供统一的接口规范。它要求子类实现 INPUT_TYPES 类方法和 execute 实例方法,从而确保节点的一致性和可扩展性。
接口定义
INPUT_TYPES类方法:定义节点的输入类型和配置。execute实例方法:处理输入并返回结果。
# comfy/comfy_types/node_typing.py
class ComfyNodeABC:
@classmethod
def INPUT_TYPES(cls):
raise NotImplementedError
def execute(self, **kwargs):
raise NotImplementedError类型提示支持
ComfyNodeABC 通过类型提示支持,帮助开发者在编写节点时获得更好的代码补全和错误检查体验。它利用 TypedDict 和 StrEnum 等类型定义,确保输入配置和输出类型的准确性。
ExampleNode 类实现分析
ExampleNode 类是 comfy_types/examples/example_nodes.py 中的一个示例节点,展示了如何继承 ComfyNodeABC 并实现自定义节点功能。它通过实现 INPUT_TYPES 和 execute 方法,定义了一个简单的整数加法节点。
INPUT_TYPES 方法
INPUT_TYPES 方法用于定义节点的输入类型和配置。在 ExampleNode 中,它定义了一个名为 input_int 的整数输入,具有默认值、最小值和最大值的约束。
# comfy/comfy_types/examples/example_nodes.py
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"input_int": ("INT", {"default": 0, "min": 0, "max": 10000})
}
}execute 方法
execute 方法用于处理输入并返回结果。在 ExampleNode 中,它接收一个整数输入 input_int,并返回加 1 的结果。
# comfy/comfy_types/examples/example_nodes.py
def execute(self, input_int):
return (input_int + 1,)结论
comfy_types 模块通过定义核心类型、协议和抽象类,为 ComfyUI 节点开发提供了统一的接口规范和类型安全保障。开发者可以基于这些定义快速实现自定义节点,同时确保节点的兼容性和可维护性。ComfyNodeABC 抽象基类和 ExampleNode 示例节点的实现,为开发者提供了清晰的开发指导和实践参考。
脚本示例模块
脚本示例模块旨在为开发者提供与 ComfyUI 服务交互的多种方式,包括基础的 HTTP 请求和更高级的 WebSocket 实时通信。这些示例展示了如何构造和提交图像生成任务,以及如何获取生成结果。模块中的脚本覆盖了不同的使用场景,从简单的任务提交到实时图像流的处理。
基础 API 示例
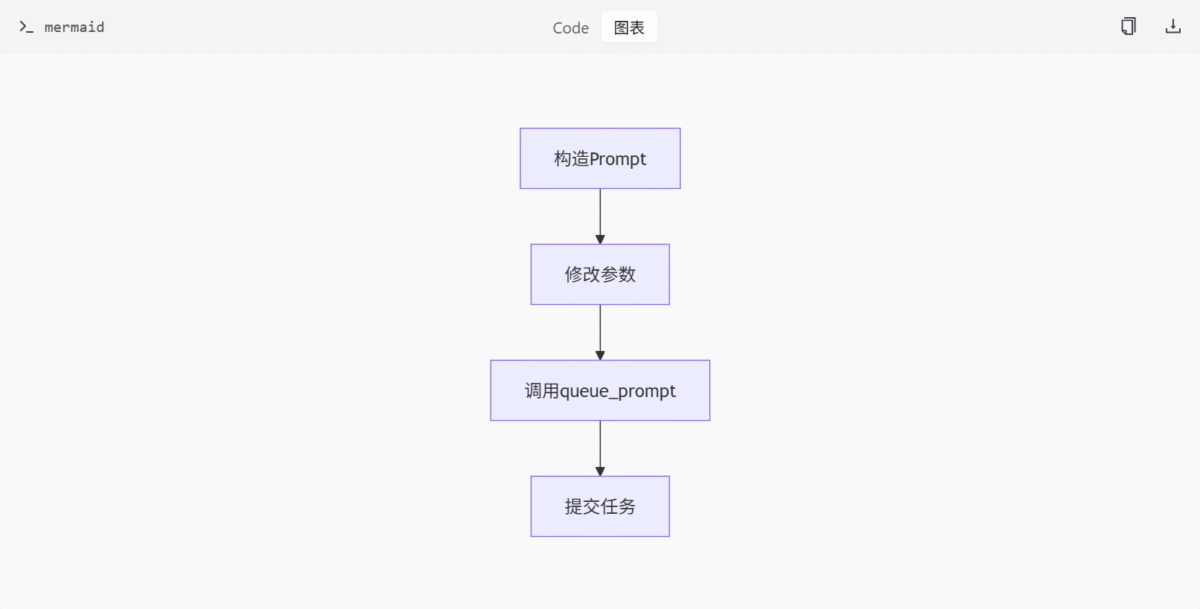
基础 API 示例脚本 (basic_api_example.py) 展示了如何通过 HTTP POST 请求与 ComfyUI 服务进行交互。该脚本定义了一个 queue_prompt 函数,用于封装并提交 JSON 格式的 prompt 请求。prompt 包含多个节点,如 CheckpointLoaderSimple 和 KSampler,代表图像生成流程的不同步骤。
架构与数据流
- 构造包含多个节点的 prompt。
- 修改提示词和种子值。
- 调用
queue_prompt函数提交任务。
关键函数
queue_prompt(prompt): 封装并提交请求。
Mermaid 图
表格
| 功能/组件 | 描述 |
|---|---|
queue_prompt | 封装并提交请求 |
CheckpointLoaderSimple | 加载检查点 |
KSampler | 采样器节点 |
代码片段
def queue_prompt(prompt):
p = {"prompt": prompt}
data = json.dumps(p).encode('utf-8')
req = request.Request("http://127.0.0.1:8188/prompt", data=data)
req.add_header("Content-Type", "application/json")
request.urlopen(req)WebSocket API 示例
WebSocket API 示例脚本 (websockets_api_example.py) 通过 WebSocket 连接 ComfyUI 服务端,实现图像生成任务的提交与结果获取。核心功能包括任务提交、图像下载和历史记录获取。
架构与数据流
- 通过 WebSocket 连接服务端。
- 提交任务并获取图像。
- 获取历史记录。
关键函数
queue_prompt: 提交任务。get_image: 下载图像。get_history: 获取历史记录。get_images: 控制主流程。
Mermaid 图
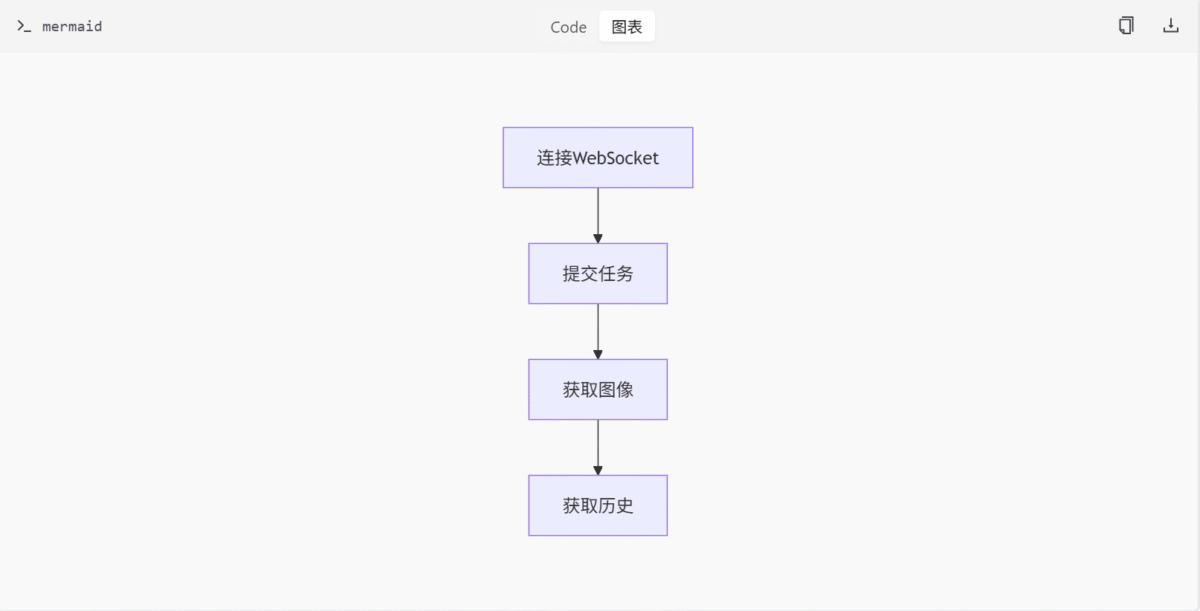
表格
| 功能/组件 | 描述 |
|---|---|
queue_prompt | 提交任务 |
get_image | 下载图像 |
get_history | 获取历史记录 |
get_images | 控制主流程 |
代码片段
def queue_prompt(prompt):
p = {"prompt": prompt}
data = json.dumps(p).encode('utf-8')
req = request.Request("http://127.0.0.1:8188/prompt", data=data)
req.add_header("Content-Type", "application/json")
request.urlopen(req)
def get_image(filename, subfolder, folder_type):
data = {"filename": filename, "subfolder": subfolder, "type": folder_type}
url_values = urllib.parse.urlencode(data)
with request.urlopen("http://127.0.0.1:8188/view?" + url_values) as response:
return response.read()
def get_history(prompt_id):
with request.urlopen("http://127.0.0.1:8188/history/" + prompt_id) as response:
return json.loads(response.read())
def get_images(ws, prompt):
prompt_id = queue_prompt(prompt)
output_images = {}
while True:
out = ws.recv()
if isinstance(out, str):
message = json.loads(out)
if message['type'] == 'executing':
data = message['data']
if data['node'] is None and data['prompt_id'] == prompt_id:
break
else:
continue
history = get_history(prompt_id)[prompt_id]
for node_id in history['outputs']:
node_output = history['outputs'][node_id]
if 'images' in node_output:
images_output = []
for image in node_output['images']:
image_data = get_image(image['filename'], image['subfolder'], image['type'])
images_output.append(image_data)
output_images[node_id] = images_output
return output_imagesWebSocket 实时图像示例
WebSocket 实时图像示例脚本 (websockets_api_example_ws_images.py) 使用 WebSocket API 实时获取图像数据,无需保存到磁盘。通过 SaveImageWebsocket 节点直接接收图像二进制流。
架构与数据流
- 构建包含
KSampler和CLIPTextEncode的工作流。 - 修改提示词和种子后提交任务。
- 监听图像返回。
关键函数
queue_prompt: 提交任务。get_image: 获取图像。get_history: 获取历史记录。get_images: 控制主流程。
Mermaid 图
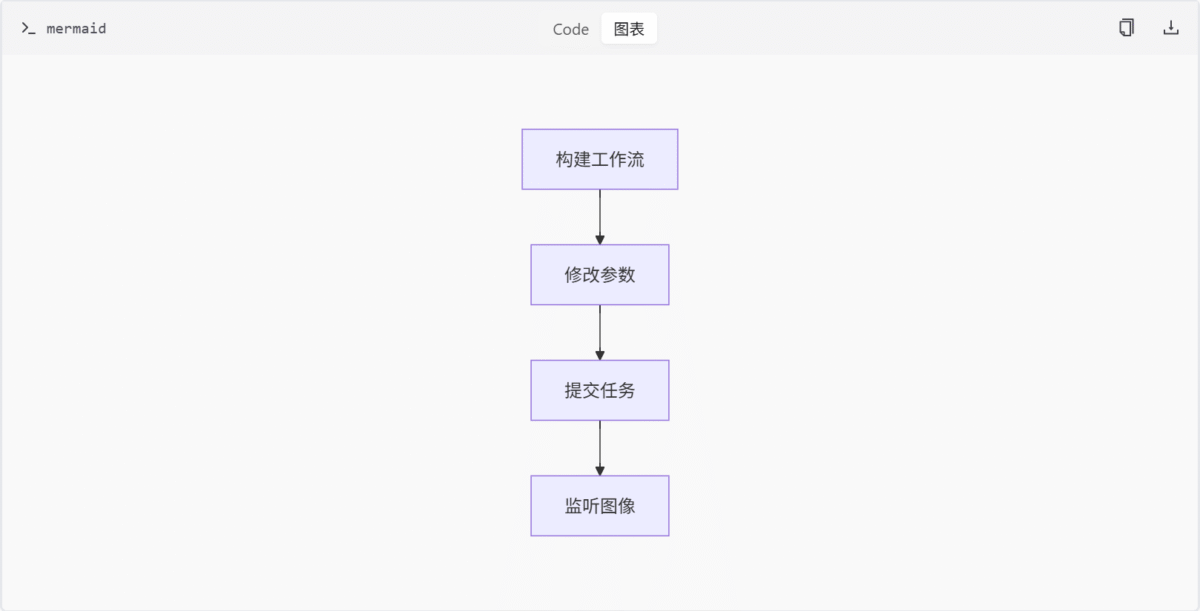
表格
| 功能/组件 | 描述 |
|---|---|
queue_prompt | 提交任务 |
get_image | 获取图像 |
get_history | 获取历史记录 |
get_images | 控制主流程 |
SaveImageWebsocket | 接收图像流 |
代码片段
def queue_prompt(prompt):
p = {"prompt": prompt}
data = json.dumps(p).encode('utf-8')
req = request.Request("http://127.0.0.1:8188/prompt", data=data)
req.add_header("Content-Type", "application/json")
request.urlopen(req)
def get_image(filename, subfolder, folder_type):
data = {"filename": filename, "subfolder": subfolder, "type": folder_type}
url_values = urllib.parse.urlencode(data)
with request.urlopen("http://127.0.0.1:8188/view?" + url_values) as response:
return response.read()
def get_history(prompt_id):
with request.urlopen("http://127.0.0.1:8188/history/" + prompt_id) as response:
return json.loads(response.read())
def get_images(ws, prompt):
prompt_id = queue_prompt(prompt)
output_images = {}
current_node = ""
while True:
out = ws.recv()
if isinstance(out, str):
message = json.loads(out)
if message['type'] == 'executing':
data = message['data']
if data['node'] is None and data['prompt_id'] == prompt_id:
break
else:
current_node = data['node']
else:
if current_node == 'save_image_websocket_node':
output_images.setdefault(current_node, []).append(out[8:])
return output_images总结
脚本示例模块通过不同的交互方式展示了与 ComfyUI 服务的集成方法。从基础的 HTTP 请求到实时的 WebSocket 通信,这些示例为开发者提供了灵活的解决方案,以满足不同的应用场景需求。每个示例都详细展示了如何构造和提交任务,以及如何获取和处理生成结果,为开发者提供了全面的参考和实践指导。
模型管理模块
模型管理模块负责定义和配置用于图像生成、修复和推理的潜在扩散模型(LDM)。这些模型基于不同的架构和参数设置,支持多种任务,如文本到图像生成、高分辨率处理、FP16/FP32精度控制以及EMA(指数移动平均)策略。模块通过YAML配置文件定义模型结构、训练参数和推理设置,确保模型在不同场景下的灵活性和可扩展性。
模型配置概览
模型配置文件位于 models/configs 目录下,每个文件定义了特定任务或模型版本的配置。以下是主要配置文件的简要说明:
主要模型配置
| 配置文件名 | 描述 |
|---|---|
anything_v3.yaml | 基于LDM的图像生成模型,使用UNet扩散模块、AutoencoderKL和FrozenCLIPEmbedder,支持交叉注意力机制和LambdaLinearScheduler。 |
v1-inference_clip_skip_2_fp16.yaml | 用于推理的LDM模型,支持FP16加速计算和EMA监控验证损失。 |
v1-inference_clip_skip_2.yaml | 用于推理的LDM模型,支持高分辨率图像处理和EMA监控验证损失。 |
v1-inference_fp16.yaml | 基于LDM的图像生成模型,使用FP16训练加速和线性预热策略。 |
v1-inference.yaml | 用于图像生成的LatentDiffusion模型,支持交叉注意力融合文本条件和LambdaLinearScheduler。 |
v1-inpainting-inference.yaml | 用于图像修复的潜在扩散模型,基于LatentInpaintDiffusion类,支持混合条件输入。 |
v2-inference_fp32.yaml | 用于推理的LatentDiffusion模型,使用FP32精度和FrozenOpenCLIPEmbedder。 |
v2-inference-v_fp32.yaml | 基于”v”参数化的LatentDiffusion推理模型,使用FP32精度。 |
v2-inference-v.yaml | 用于推理的LatentDiffusion模型,支持跨模态条件控制和FP16精度。 |
v2-inference.yaml | 用于图像生成的LatentDiffusion模型,专为推理设计并禁用EMA。 |
v2-inpainting-inference.yaml | 用于图像修复的扩散模型,结合文本条件和图像输入进行修复。 |
模型架构与组件
核心组件
- LatentDiffusion: 潜在扩散模型的核心类,负责图像生成和修复任务。
- UNetModel: 用于处理潜空间数据的扩散模块。
- AutoencoderKL: 自动编码器,用于图像的压缩和解压。
- FrozenCLIPEmbedder/FrozenOpenCLIPEmbedder: 用于提取文本特征的嵌入器。
- LambdaLinearScheduler: 学习率调度器,控制训练过程中的学习率变化。
模型流程图
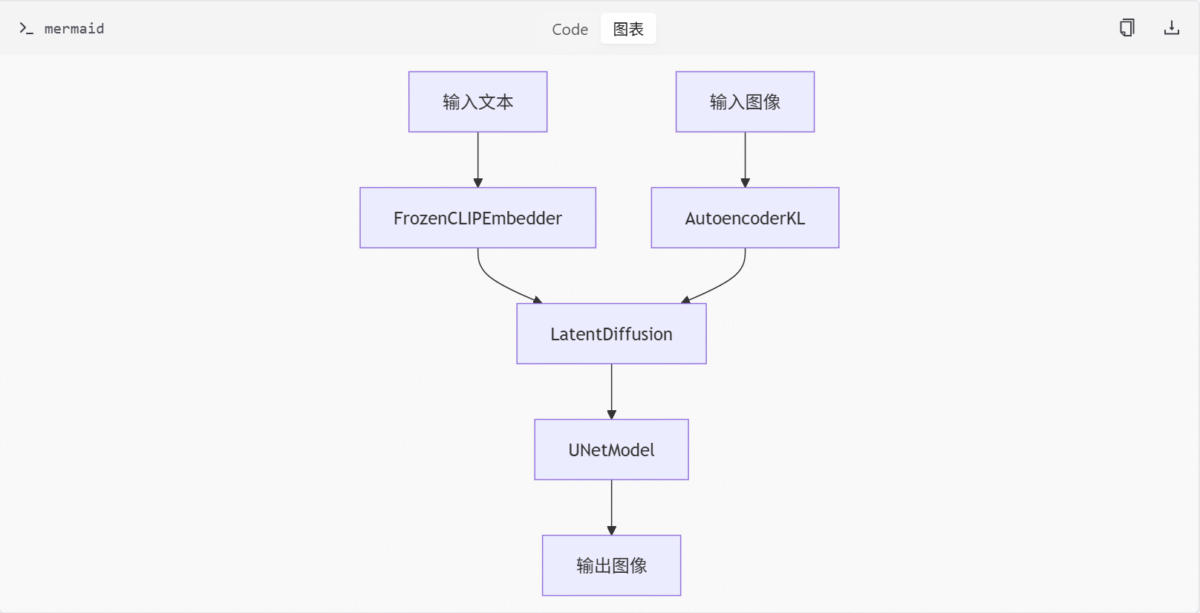
配置选项与参数
训练与推理参数
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
fp16 | bool | false | 是否使用FP16精度进行训练或推理。 |
ema | bool | true | 是否启用EMA监控验证损失。 |
clip_skip | int | 1 | 控制文本嵌入器的跳过层数。 |
scheduler | string | “LambdaLinearScheduler” | 学习率调度器类型。 |
数据模块配置
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
data_module | string | “WebDataModuleFromConfig” | 数据模块类名,用于加载LAION图像数据。 |
batch_size | int | 4 | 批处理大小。 |
num_workers | int | 4 | 数据加载器的工作线程数。 |
LatentDiffusion 类分析
LatentDiffusion 是潜在扩散模型的核心类,负责图像生成任务。从配置文件中可以看出,该类具有以下关键参数:
基础参数
base_learning_rate: 基础学习率,通常设置为1.0e-04或5.0e-05linear_start和linear_end: 控制噪声调度的线性范围num_timesteps_cond: 条件时间步数timesteps: 总时间步数,通常为1000image_size: 图像尺寸,通常为64channels: 通道数,通常为4use_ema: 是否使用指数移动平均,推理配置中通常设为False
调度器配置
多数配置使用 LambdaLinearScheduler 作为调度器,具有以下参数:
warm_up_steps: 预热步数,通常为10000或2500cycle_lengths: 循环长度f_start,f_max,f_min: 频率参数
UNet配置
通过 unet_config 引用 UNetModel,这是扩散过程的核心网络。
UNetModel 类分析
UNetModel 是处理潜空间数据的扩散模块,具有以下关键特性:
基础架构参数
image_size: 图像尺寸(未使用)in_channels: 输入通道数,通常为4或9(图像修复任务)out_channels: 输出通道数,通常为4model_channels: 模型通道数,通常为320attention_resolutions: 注意力分辨率,通常为[4, 2, 1]num_res_blocks: 残差块数量,通常为2channel_mult: 通道倍增因子,通常为[1, 2, 4, 4]
Transformer相关参数
use_spatial_transformer: 是否使用空间Transformertransformer_depth: Transformer深度context_dim: 上下文维度,根据使用的嵌入器不同而不同(768 for CLIP, 1024 for OpenCLIP)use_linear_in_transformer: 是否在Transformer中使用线性层(v2模型特有)
性能优化参数
use_checkpoint: 是否使用检查点机制节省内存use_fp16: 是否使用FP16精度训练/推理num_head_channels: 注意力头通道数
AutoencoderKL 类分析
AutoencoderKL 是自动编码器,负责图像的编码和解码,具有以下关键配置:
编码器/解码器参数
embed_dim: 嵌入维度,通常为4ddconfig: 解码器配置double_z: 是否使用双z通道z_channels: z通道数,通常为4resolution: 分辨率,通常为256in_channels和out_ch: 输入输出通道数,通常为3ch: 基础通道数,通常为128ch_mult: 通道倍增因子num_res_blocks: 残差块数量attn_resolutions: 注意力分辨率
损失函数配置
lossconfig: 损失函数配置,通常使用torch.nn.Identity
FrozenCLIPEmbedder 类分析
FrozenCLIPEmbedder 是用于提取文本特征的嵌入器,具有以下特点:
基础配置
- 通常作为
cond_stage_config的目标类 - 在不同版本中可能有不同的参数配置
变体
FrozenCLIPEmbedder: 用于CLIP模型FrozenOpenCLIPEmbedder: 用于OpenCLIP模型,通常在v2模型中使用
特殊参数
layer: 指定使用的层(”hidden” 或 “penultimate”)layer_idx: 层索引,用于跳过某些层
组件交互关系
通过分析配置文件,可以发现这些组件之间的交互关系:
LatentDiffusion作为主模型类,整合了UNetModel、AutoencoderKL和FrozenCLIPEmbedderUNetModel负责扩散过程的核心计算AutoencoderKL负责图像的编码和解码FrozenCLIPEmbedder提供文本条件输入
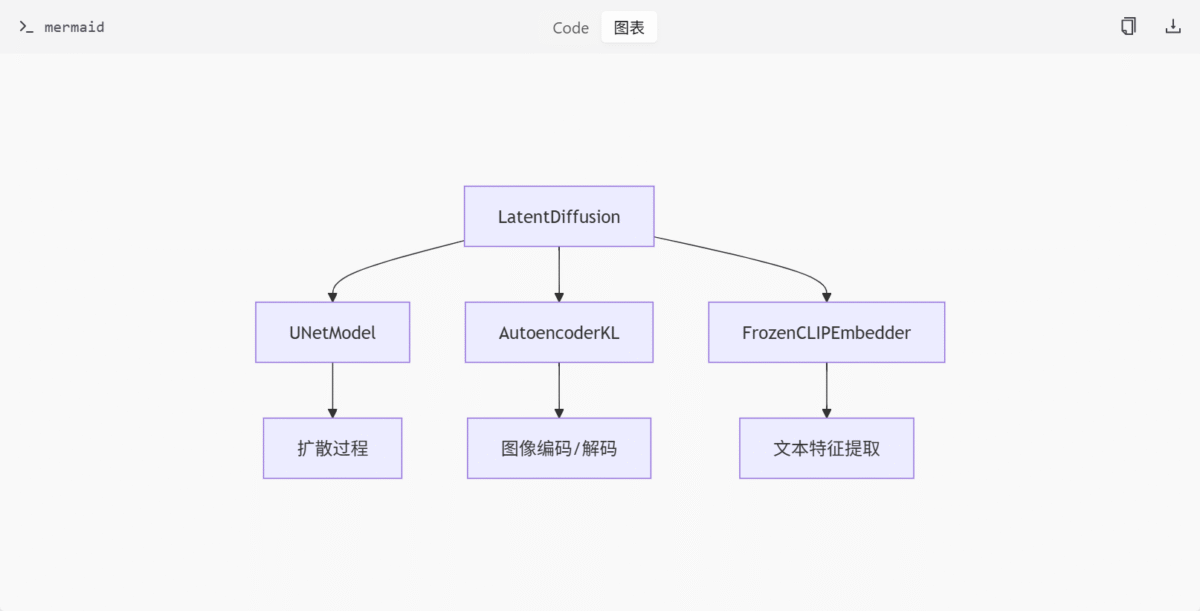
总结
模型管理模块通过一系列YAML配置文件定义了多种潜在扩散模型的结构和参数,支持图像生成、修复和推理任务。模块的核心组件包括LatentDiffusion、UNetModel、AutoencoderKL和FrozenCLIPEmbedder,结合不同的调度器和精度设置,确保模型在不同场景下的高效运行。通过这些配置,开发者可以灵活地调整模型以适应特定需求。
执行管理模块
执行管理模块是 ComfyUI 项目的核心组成部分,负责管理节点执行流程、缓存机制、进度追踪和上下文状态。该模块通过多个子模块协同工作,确保图形化流程中的节点能够高效、有序地执行,并提供必要的性能优化和状态监控能力。
缓存管理
缓存管理模块 (caching.py) 实现了多种缓存机制,旨在提升节点执行效率和资源利用率。其核心组件包括:
- 缓存键生成逻辑:通过抽象类及子类生成可哈希键,用于唯一标识缓存项。
- BasicCache:提供通用缓存接口。
- LRUCache:实现 LRU(Least Recently Used)淘汰策略。
- DependencyAwareCache:维护节点间的依赖关系图,确保缓存项的依赖关系正确。
- HierarchicalCache:按层级组织缓存,支持更复杂的缓存结构。
缓存架构图
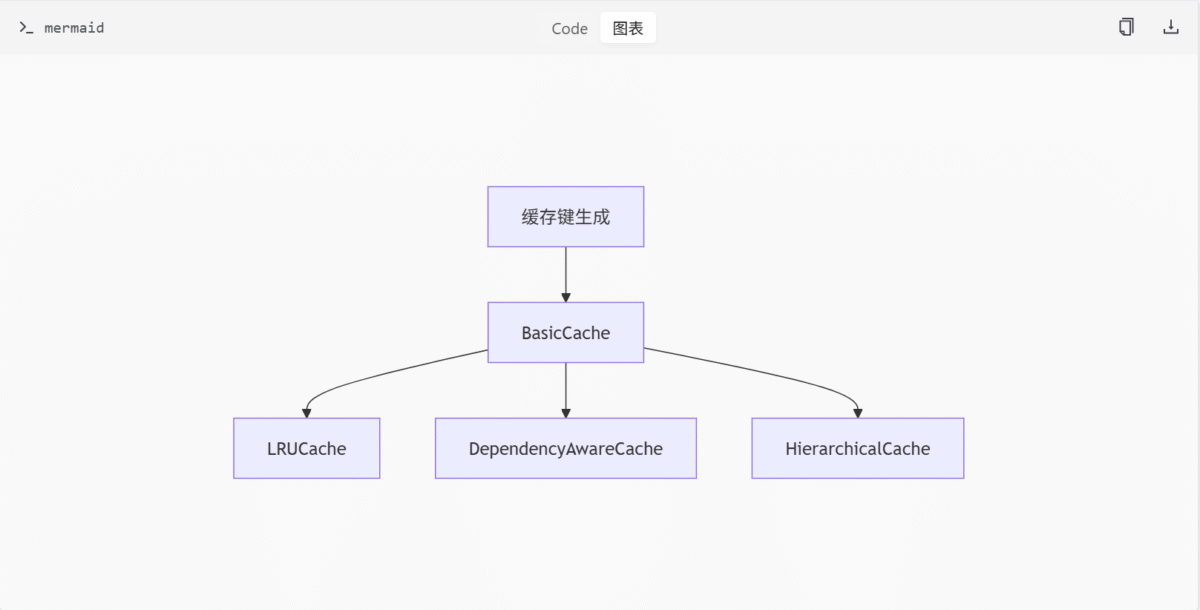
主要缓存类
| 类名 | 描述 |
|---|---|
| BasicCache | 通用缓存接口 |
| LRUCache | LRU 淘汰策略缓存 |
| DependencyAwareCache | 维护依赖关系的缓存 |
| HierarchicalCache | 按层级组织的缓存 |
缓存键生成机制
在 caching.py 文件中,定义了多个缓存键集类,用于生成可哈希的缓存键:
- CacheKeySet(抽象基类):
- 定义了缓存键生成的基本接口
- 包含
add_keys抽象方法,需要子类实现
- CacheKeySetID:
- 基于节点ID和类类型的简单键生成
- 键格式为
(node_id, class_type)
- CacheKeySetInputSignature:
- 更复杂的键生成机制,基于节点的输入签名
- 考虑了节点的输入值、连接关系和祖先节点
class CacheKeySet(ABC):
def __init__(self, dynprompt, node_ids, is_changed_cache):
self.keys = {}
self.subcache_keys = {}
@abstractmethod
async def add_keys(self, node_ids):
raise NotImplementedError()
def all_node_ids(self):
return set(self.keys.keys())
def get_used_keys(self):
return self.keys.values()
def get_used_subcache_keys(self):
return self.subcache_keys.values()
def get_data_key(self, node_id):
return self.keys.get(node_id, None)
def get_subcache_key(self, node_id):
return self.subcache_keys.get(node_id, None)BasicCache 基础缓存类
BasicCache 是所有缓存类的基础实现,提供了通用的缓存操作接口:
class BasicCache:
def __init__(self, key_class):
self.key_class = key_class
self.initialized = False
self.dynprompt: DynamicPrompt
self.cache_key_set: CacheKeySet
self.cache = {}
self.subcaches = {}
async def set_prompt(self, dynprompt, node_ids, is_changed_cache):
self.dynprompt = dynprompt
self.cache_key_set = self.key_class(dynprompt, node_ids, is_changed_cache)
await self.cache_key_set.add_keys(node_ids)
self.is_changed_cache = is_changed_cache
self.initialized = True
def all_node_ids(self):
assert self.initialized
node_ids = self.cache_key_set.all_node_ids()
for subcache in self.subcaches.values():
node_ids = node_ids.union(subcache.all_node_ids())
return node_ids
def clean_unused(self):
assert self.initialized
self._clean_cache()
self._clean_subcaches()
def _set_immediate(self, node_id, value):
assert self.initialized
cache_key = self.cache_key_set.get_data_key(node_id)
self.cache[cache_key] = value
def _get_immediate(self, node_id):
if not self.initialized:
return None
cache_key = self.cache_key_set.get_data_key(node_id)
if cache_key in self.cache:
return self.cache[cache_key]
else:
return NoneLRUCache LRU缓存实现
LRUCache 实现了基于最近最少使用算法的缓存淘汰机制:
class LRUCache(BasicCache):
def __init__(self, key_class, max_size=100):
super().__init__(key_class)
self.max_size = max_size
self.min_generation = 0
self.generation = 0
self.used_generation = {}
self.children = {}
async def set_prompt(self, dynprompt, node_ids, is_changed_cache):
await super().set_prompt(dynprompt, node_ids, is_changed_cache)
self.generation += 1
for node_id in node_ids:
self._mark_used(node_id)
def clean_unused(self):
while len(self.cache) > self.max_size and self.min_generation < self.generation:
self.min_generation += 1
to_remove = [key for key in self.cache if self.used_generation[key] < self.min_generation]
for key in to_remove:
del self.cache[key]
del self.used_generation[key]
if key in self.children:
del self.children[key]
self._clean_subcaches()
def get(self, node_id):
self._mark_used(node_id)
return self._get_immediate(node_id)
def _mark_used(self, node_id):
cache_key = self.cache_key_set.get_data_key(node_id)
if cache_key is not None:
self.used_generation[cache_key] = self.generation
def set(self, node_id, value):
self._mark_used(node_id)
return self._set_immediate(node_id, value)DependencyAwareCache 依赖感知缓存
DependencyAwareCache 维护节点间的依赖关系,当所有后代节点执行完毕后自动清理祖先节点:
class DependencyAwareCache(BasicCache):
def __init__(self, key_class):
super().__init__(key_class)
self.descendants = {} # Maps node_id -> set of descendant node_ids
self.ancestors = {} # Maps node_id -> set of ancestor node_ids
self.executed_nodes = set() # Tracks nodes that have been executed
async def set_prompt(self, dynprompt, node_ids, is_changed_cache):
# Clear all existing cache data
self.cache.clear()
self.subcaches.clear()
self.descendants.clear()
self.ancestors.clear()
self.executed_nodes.clear()
# Call the parent method to initialize the cache with the new prompt
await super().set_prompt(dynprompt, node_ids, is_changed_cache)
# Rebuild the dependency graph
self._build_dependency_graph(dynprompt, node_ids)
def _build_dependency_graph(self, dynprompt, node_ids):
self.descendants.clear()
self.ancestors.clear()
for node_id in node_ids:
self.descendants[node_id] = set()
self.ancestors[node_id] = set()
for node_id in node_ids:
inputs = dynprompt.get_node(node_id)["inputs"]
for input_data in inputs.values():
if is_link(input_data): # Check if the input is a link to another node
ancestor_id = input_data[0]
self.descendants[ancestor_id].add(node_id)
self.ancestors[node_id].add(ancestor_id)
def set(self, node_id, value):
self._set_immediate(node_id, value)
self.executed_nodes.add(node_id)
self._cleanup_ancestors(node_id)
def _cleanup_ancestors(self, node_id):
for ancestor_id in self.ancestors.get(node_id, []):
if ancestor_id in self.executed_nodes:
# Remove ancestor if all its descendants have been executed
if all(descendant in self.executed_nodes for descendant in self.descendants[ancestor_id]):
self._remove_node(ancestor_id)HierarchicalCache 分层缓存
HierarchicalCache 支持按层级组织缓存,适用于嵌套节点结构:
class HierarchicalCache(BasicCache):
def __init__(self, key_class):
super().__init__(key_class)
def _get_cache_for(self, node_id):
assert self.dynprompt is not None
parent_id = self.dynprompt.get_parent_node_id(node_id)
if parent_id is None:
return self
hierarchy = []
while parent_id is not None:
hierarchy.append(parent_id)
parent_id = self.dynprompt.get_parent_node_id(parent_id)
cache = self
for parent_id in reversed(hierarchy):
cache = cache._get_subcache(parent_id)
if cache is None:
return None
return cache
def get(self, node_id):
cache = self._get_cache_for(node_id)
if cache is None:
return None
return cache._get_immediate(node_id)
def set(self, node_id, value):
cache = self._get_cache_for(node_id)
assert cache is not None
cache._set_immediate(node_id, value)图执行管理
图执行管理模块 (graph.py) 负责处理节点图的执行逻辑,包括构建和管理节点依赖关系,以及实现拓扑排序。其核心类包括:
- DynamicPrompt:管理原始提示与临时节点。
- get_input_info:获取节点输入信息。
- TopologicalSort:实现节点的拓扑排序。
- ExecutionList:扩展执行控制,支持异步执行和循环检测。
图执行流程
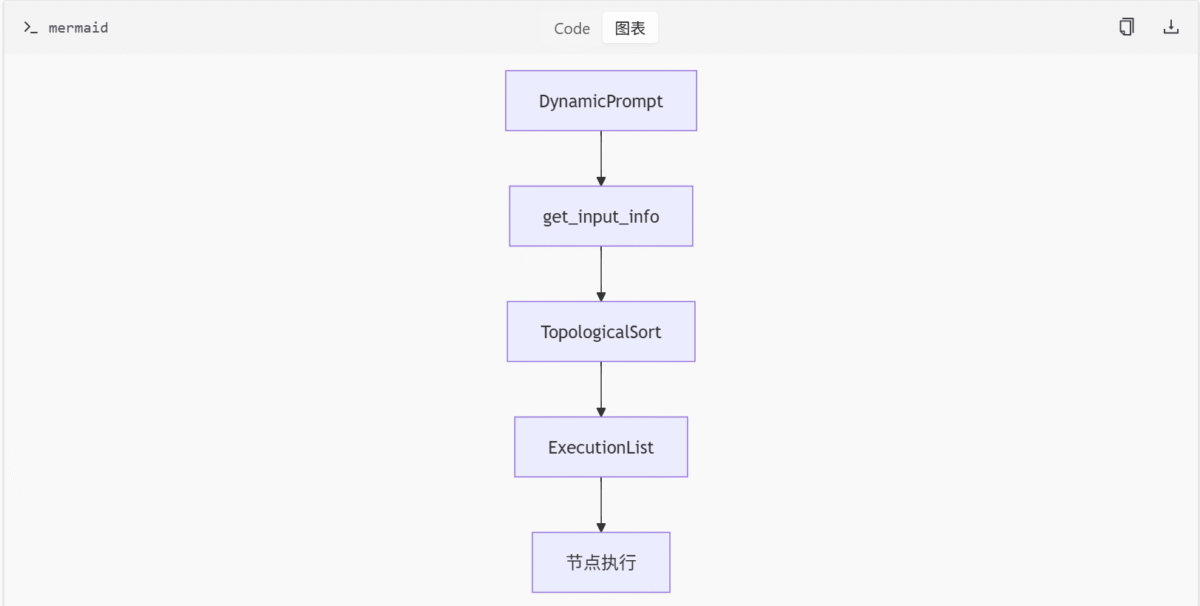
主要图执行类
| 类名 | 描述 |
|---|---|
| DynamicPrompt | 管理原始提示与临时节点 |
| TopologicalSort | 实现拓扑排序 |
| ExecutionList | 扩展执行控制,支持异步和循环检测 |
图结构工具
图结构工具模块 (graph_utils.py) 提供基础的图结构构建与操作能力。其核心组件包括:
- GraphBuilder:支持创建和管理节点,并生成符合后端要求的数据格式。
- Node:表示图节点,包含类型和输入信息。
- 工具函数:
is_link:判断连接结构。add_graph_prefix:添加统一前缀。ExecutionBlocker:控制节点执行条件。
图结构工具类
| 类名 | 描述 |
|---|---|
| GraphBuilder | 创建和管理图节点 |
| Node | 表示图节点 |
| ExecutionBlocker | 控制节点执行条件 |
进度追踪
进度追踪模块 (progress.py) 实现了节点执行进度的跟踪系统,支持 CLI 和 WebUI。其核心组件包括:
- NodeState:枚举类,表示节点状态。
- ProgressHandler:抽象基类,定义进度更新接口。
- CLIProgressHandler:显示命令行进度条。
- WebUIProgressHandler:通过 WebSocket 发送进度。
- ProgressRegistry:管理全局进度状态。
进度追踪架构
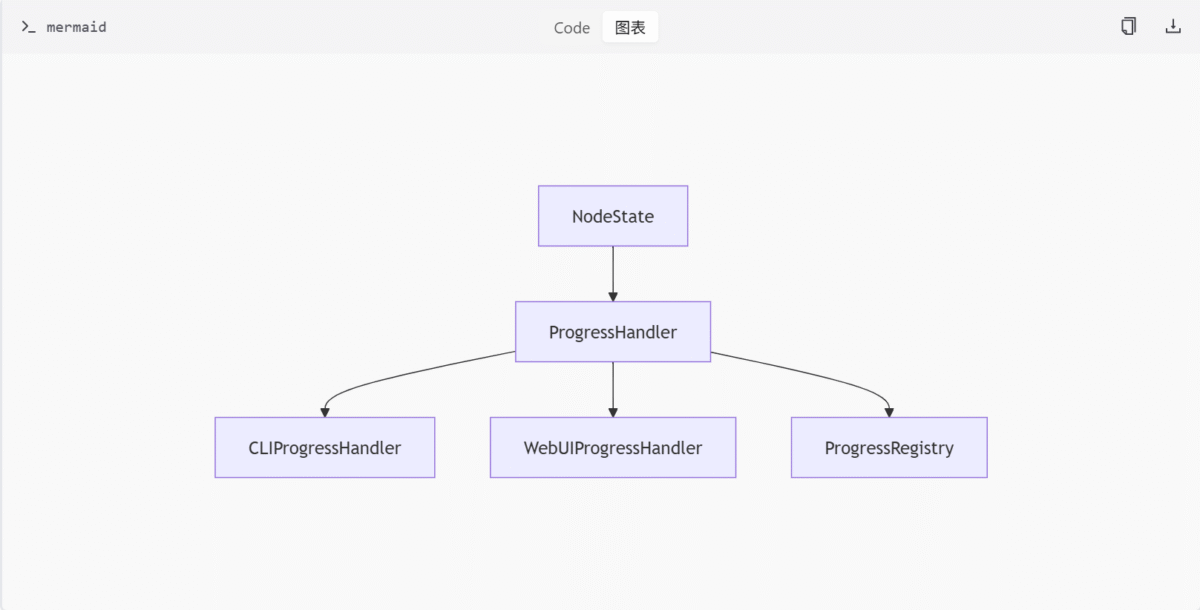
主要进度追踪类
| 类名 | 描述 |
|---|---|
| NodeState | 节点状态枚举 |
| ProgressHandler | 进度更新接口 |
| CLIProgressHandler | 命令行进度条 |
| WebUIProgressHandler | WebSocket 进度发送 |
| ProgressRegistry | 全局进度状态管理 |
执行上下文管理
执行上下文管理模块 (utils.py) 用于管理执行上下文,记录节点执行状态。其核心组件包括:
- ExecutionContext:标识当前执行上下文。
- ContextVar:实现线程安全存储。
- CurrentNodeContext:上下文管理器,用于切换与恢复上下文。
- get_executing_context:访问当前上下文的函数。
执行上下文管理类
| 类名 | 描述 |
|---|---|
| ExecutionContext | 当前执行上下文 |
| CurrentNodeContext | 上下文切换与恢复 |
| get_executing_context | 访问当前上下文 |
输入验证
输入验证模块 (validation.py) 定义了 validate_node_input 函数,用于验证节点输入类型是否匹配预期。其参数包括接收类型、期望类型和严格模式标志。
输入验证函数
def validate_node_input(received_type, expected_type, strict=False):
# 验证逻辑
pass输入验证参数
| 参数名 | 类型 | 描述 |
|---|---|---|
| received_type | Type | 接收的输入类型 |
| expected_type | Type | 期望的输入类型 |
| strict | Boolean | 是否启用严格模式 |
总结
执行管理模块通过缓存管理、图执行管理、图结构工具、进度追踪、执行上下文管理和输入验证等多个子模块,共同构成了 ComfyUI 的核心执行引擎。这些模块协同工作,确保了节点执行的高效性、有序性和可追踪性,为用户提供流畅的图形化流程体验。
测试模块
测试模块是 ComfyUI 项目中用于验证系统功能、性能和稳定性的核心部分。它涵盖了从基础执行逻辑到复杂异步节点行为的全面测试,确保系统在各种场景下都能正常运行。测试模块主要包括以下几个子模块:
- 执行测试:验证 ComfyUI 的执行引擎,包括缓存、错误处理和控制流等关键功能。
- 异步节点测试:专门测试异步节点的行为,如依赖管理、超时处理等。
- 图像质量测试:通过 SSIM 指标评估生成图像的质量。
- 推理测试:自动化测试 ComfyUI 的图像生成流程,确保不同采样器和调度器的兼容性。
执行测试
执行测试模块主要验证 ComfyUI 的执行引擎,确保其在各种场景下的稳定性和可靠性。该模块包括以下文件:
tests/execution/test_execution.py:测试 ComfyUI 执行逻辑,覆盖缓存、错误处理、控制流等场景。tests/execution/test_async_nodes.py:异步节点测试模块,验证异步节点在依赖管理、缓存、错误处理等场景下的行为。tests/execution/test_progress_isolation.py:验证不同 WebSocket 客户端的进度消息是否隔离。
测试节点
测试节点是执行测试的核心组件,用于模拟各种场景下的节点行为。测试节点包括:
TestAsyncProgressUpdate和TestSyncProgressUpdate:分别测试异步与同步进度更新机制。TestAsyncValidation、TestAsyncError等:用于测试输入验证、超时处理等异步行为。- 条件判断节点:如数值比较、字符串匹配等,返回布尔结果。
- 流程控制节点:包括循环入口、出口及执行阻断节点,适用于复杂任务调度与工作流测试。
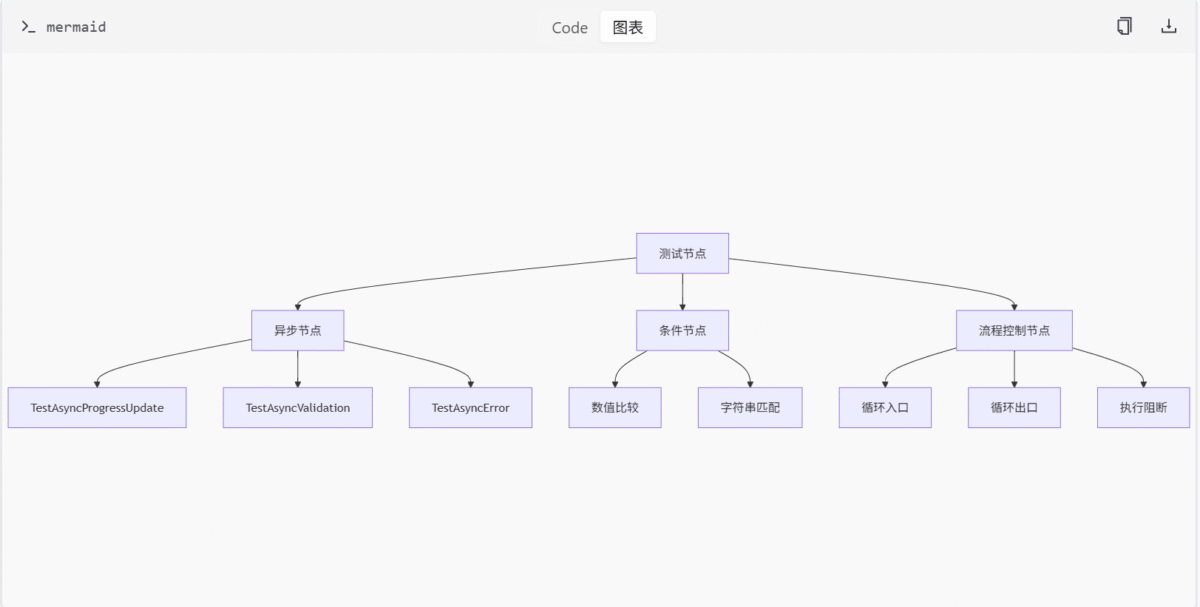
测试执行流程
执行测试的流程如下:
- 初始化测试环境,包括启动服务端进程并监听端口。
- 初始化客户端连接并预热服务。
- 构建测试图结构,设置提示词、采样器、调度器及保存前缀。
- 提交任务并获取图像。
- 验证结果是否为空或全黑。
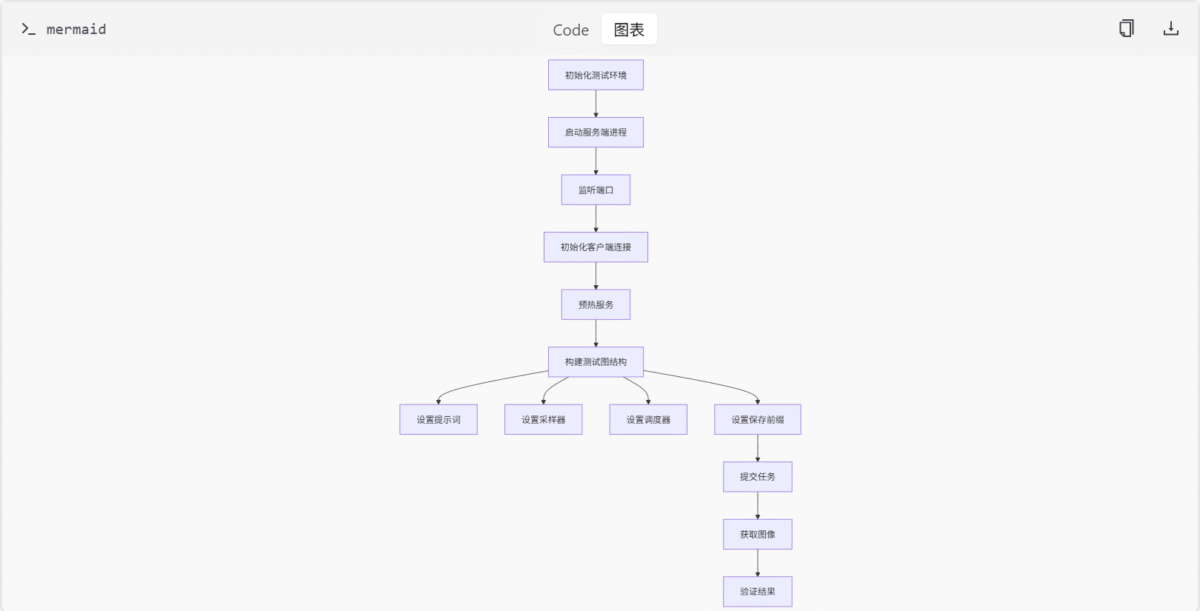
图像质量测试
图像质量测试模块通过 SSIM 指标评估生成图像的质量,确保图像生成的准确性和一致性。该模块包括以下文件:
tests/compare/conftest.py:PyTest 配置文件,用于图像比较测试。tests/compare/test_quality.py:执行图像质量对比测试,使用 SSIM 指标评估基准与测试图像。
测试流程
图像质量测试的流程如下:
- 定义命令行参数,初始化全局配置。
- 基于
.png文件名生成测试用例。 - 读取基准图像和测试图像。
- 使用 SSIM 指标评估图像质量。
- 可视化测试结果。
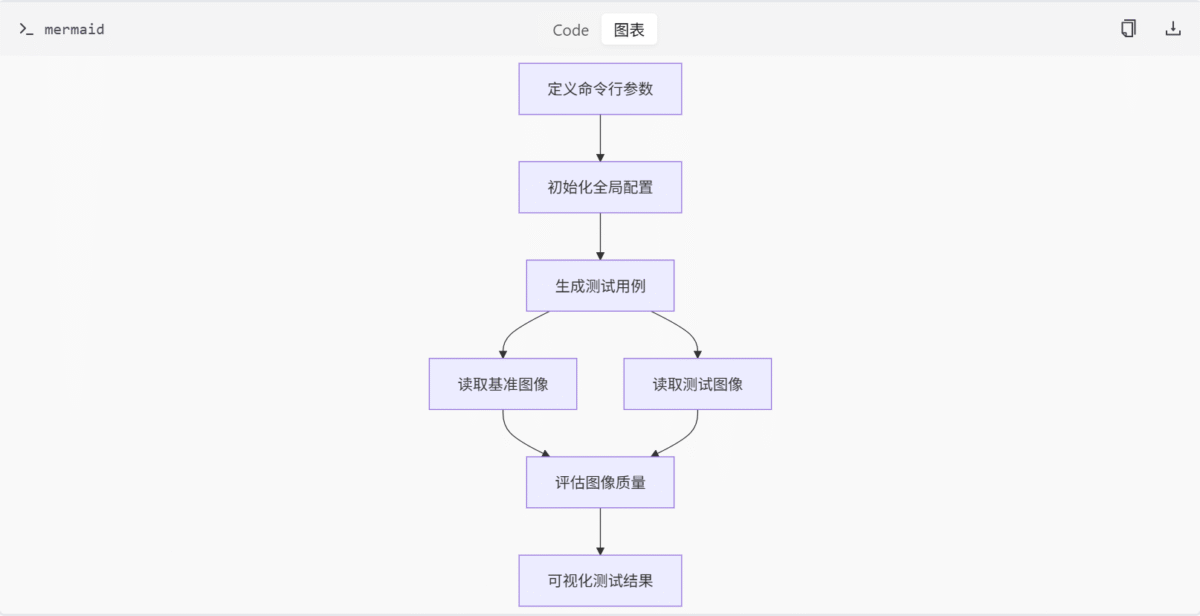
推理测试
推理测试模块自动化测试 ComfyUI 的图像生成流程,确保不同采样器和调度器的兼容性。该模块包括以下文件:
tests/inference/graphs/default_graph_sdxl1_0.json:定义 Stable Diffusion XL 1.0 的图像生成流程。tests/inference/test_inference.py:测试 ComfyUI 图像生成流程的单元测试脚本。
推理测试模块是 ComfyUI 测试套件中专门用于验证图像生成流程的核心组件。它通过自动化测试确保不同采样器和调度器在各种提示词输入下的兼容性和稳定性。
ComfyGraph 类
ComfyGraph 类是推理测试中的核心组件,用于封装和操作图像生成的工作流图。它提供了设置提示词、采样器、调度器和文件名前缀的方法。
class ComfyGraph:
def __init__(self,
graph: dict,
sampler_nodes: list[str],
):
self.graph = graph
self.sampler_nodes = sampler_nodes
def set_prompt(self, prompt, negative_prompt=None):
for node in self.sampler_nodes:
prompt_node = self.graph[node]['inputs']['positive'][0]
self.graph[prompt_node]['inputs']['text'] = prompt
if negative_prompt:
negative_prompt_node = self.graph[node]['inputs']['negative'][0]
self.graph[negative_prompt_node]['inputs']['text'] = negative_prompt
def set_sampler_name(self, sampler_name:str, ):
for node in self.sampler_nodes:
self.graph[node]['inputs']['sampler_name'] = sampler_name
def set_scheduler(self, scheduler:str):
for node in self.sampler_nodes:
self.graph[node]['inputs']['scheduler'] = scheduler
def set_filename_prefix(self, prefix:str):
for node in self.graph:
if self.graph[node]['class_type'] == 'SaveImage':
self.graph[node]['inputs']['filename_prefix'] = prefixComfyClient 类
ComfyClient 类负责与 ComfyUI 服务器进行通信,包括连接、提交任务、获取图像等功能。
class ComfyClient:
def connect(self,
listen:str = '127.0.0.1',
port:Union[str,int] = 8188,
client_id: str = str(uuid.uuid4())
):
self.client_id = client_id
self.server_address = f"{listen}:{port}"
ws = websocket.WebSocket()
ws.connect("ws://{}/ws?clientId={}".format(self.server_address, self.client_id))
self.ws = ws
def queue_prompt(self, prompt):
p = {"prompt": prompt, "client_id": self.client_id}
data = json.dumps(p).encode('utf-8')
req = urllib.request.Request("http://{}/prompt".format(self.server_address), data=data)
return json.loads(urllib.request.urlopen(req).read())
def get_image(self, filename, subfolder, folder_type):
data = {"filename": filename, "subfolder": subfolder, "type": folder_type}
url_values = urllib.parse.urlencode(data)
with urllib.request.urlopen("http://{}/view?{}".format(self.server_address, url_values)) as response:
return response.read()
def get_history(self, prompt_id):
with urllib.request.urlopen("http://{}/history/{}".format(self.server_address, prompt_id)) as response:
return json.loads(response.read())
def get_images(self, graph, save=True):
prompt = graph
if not save:
prompt_str = json.dumps(prompt)
prompt_str = prompt_str.replace('SaveImage', 'PreviewImage')
prompt = json.loads(prompt_str)
prompt_id = self.queue_prompt(prompt)['prompt_id']
output_images = {}
while True:
out = self.ws.recv()
if isinstance(out, str):
message = json.loads(out)
if message['type'] == 'executing':
data = message['data']
if data['node'] is None and data['prompt_id'] == prompt_id:
break
else:
continue
history = self.get_history(prompt_id)[prompt_id]
for node_id in history['outputs']:
node_output = history['outputs'][node_id]
images_output = []
if 'images' in node_output:
for image in node_output['images']:
image_data = self.get_image(image['filename'], image['subfolder'], image['type'])
images_output.append(image_data)
output_images[node_id] = images_output
return output_images默认测试图结构
推理测试使用一个默认的 SDXL 1.0 图结构 (default_graph_sdxl1_0.json),该图定义了完整的图像生成流程:
{
"4": {
"inputs": {
"ckpt_name": "sd_xl_base_1.0.safetensors"
},
"class_type": "CheckpointLoaderSimple"
},
"5": {
"inputs": {
"width": 1024,
"height": 1024,
"batch_size": 1
},
"class_type": "EmptyLatentImage"
},
"6": {
"inputs": {
"text": "a photo of a cat",
"clip": [
"4",
1
]
},
"class_type": "CLIPTextEncode"
},
"10": {
"inputs": {
"add_noise": "enable",
"noise_seed": 42,
"steps": 20,
"cfg": 7.5,
"sampler_name": "euler",
"scheduler": "normal",
"start_at_step": 0,
"end_at_step": 32,
"return_with_leftover_noise": "enable",
"model": [
"4",
0
],
"positive": [
"6",
0
],
"negative": [
"15",
0
],
"latent_image": [
"5",
0
]
},
"class_type": "KSamplerAdvanced"
},
"12": {
"inputs": {
"samples": [
"14",
0
],
"vae": [
"4",
2
]
},
"class_type": "VAEDecode"
},
"13": {
"inputs": {
"filename_prefix": "test_inference",
"images": [
"12",
0
]
},
"class_type": "SaveImage"
},
"14": {
"inputs": {
"add_noise": "disable",
"noise_seed": 42,
"steps": 20,
"cfg": 7.5,
"sampler_name": "euler",
"scheduler": "normal",
"start_at_step": 32,
"end_at_step": 10000,
"return_with_leftover_noise": "disable",
"model": [
"16",
0
],
"positive": [
"17",
0
],
"negative": [
"20",
0
],
"latent_image": [
"10",
0
]
},
"class_type": "KSamplerAdvanced"
},
"15": {
"inputs": {
"conditioning": [
"6",
0
]
},
"class_type": "ConditioningZeroOut"
},
"16": {
"inputs": {
"ckpt_name": "sd_xl_refiner_1.0.safetensors"
},
"class_type": "CheckpointLoaderSimple"
},
"17": {
"inputs": {
"text": "a photo of a cat",
"clip": [
"16",
1
]
},
"class_type": "CLIPTextEncode"
},
"20": {
"inputs": {
"text": "",
"clip": [
"16",
1
]
},
"class_type": "CLIPTextEncode"
}
}测试执行流程
推理测试使用 pytest 框架进行参数化测试,遍历不同的采样器、调度器和提示词组合:
@pytest.mark.inference
@pytest.mark.parametrize("sampler", sampler_list)
@pytest.mark.parametrize("scheduler", scheduler_list)
@pytest.mark.parametrize("prompt", prompt_list)
class TestInference:
def test_comfy(
self,
client,
comfy_graph,
sampler,
scheduler,
prompt,
request
):
test_info = request.node.name
comfy_graph.set_filename_prefix(test_info)
comfy_graph.set_sampler_name(sampler)
comfy_graph.set_scheduler(scheduler)
comfy_graph.set_prompt(prompt)
images = client.get_images(comfy_graph.graph)
assert len(images) != 0, "No images generated"
for images_output in images.values():
for image_data in images_output:
pil_image = Image.open(BytesIO(image_data))
assert numpy.array(pil_image).any() != 0, "Image is blank"测试流程包括:
- 启动 ComfyUI 服务器进程
- 初始化 WebSocket 客户端连接
- 预热管道(执行一次不保存图像的生成)
- 设置测试参数(采样器、调度器、提示词等)
- 执行图像生成并验证结果
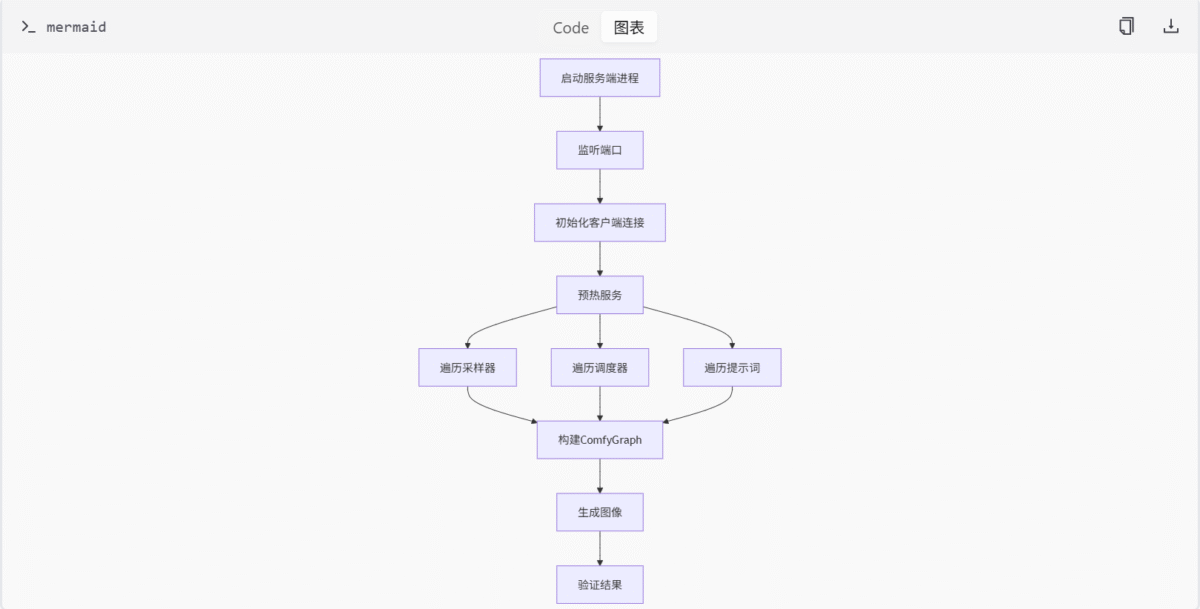
配置文件
测试模块使用多个配置文件来管理测试环境和节点路径。这些配置文件包括:
tests/conftest.py:注册命令行参数,管理输出目录、监听设置及时间检查跳过逻辑。tests/execution/extra_model_paths.yaml:指定测试节点的自定义路径,便于框架动态加载测试节点。
命令行参数
tests/conftest.py 文件中定义了以下命令行参数:
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
--output_dir | string | None | 输出目录 |
--listen | string | None | 监听设置 |
--port | int | None | 端口号 |
--skip-timing-checks | bool | False | 跳过时间检查 |
节点路径配置
tests/execution/extra_model_paths.yaml 文件中定义了测试节点的自定义路径,便于框架动态加载测试节点。
testing_nodes:
- tests/execution/testing_nodes/testing-pack总结
测试模块是 ComfyUI 项目中不可或缺的一部分,它通过全面的测试用例确保系统的稳定性和可靠性。执行测试、异步节点测试、图像质量测试和推理测试共同构成了一个完整的测试体系,覆盖了从基础功能到复杂场景的各个方面。通过这些测试,开发人员可以及时发现和修复问题,确保 ComfyUI 在各种环境下都能正常运行。推理测试模块特别重要,它通过自动化验证图像生成流程,确保不同采样器和调度器的兼容性,为系统的稳定性和可靠性提供了重要保障。
配置模块
配置模块是 ComfyUI 自定义节点系统的核心组成部分,负责解析和管理节点的配置信息。它支持从 .py 文件或包含 pyproject.toml 的目录中提取配置,为 ComfyUI CLI 和注册表提供统一的数据结构定义。该模块通过解析 TOML 文件或默认命名规则生成结构化配置对象,确保项目元数据、环境支持信息和 ComfyUI 特定配置的准确性和一致性。
核心组件
配置解析器 (config_parser.py)
config_parser.py 是配置模块的核心,负责从不同来源提取和解析配置信息。
主要功能
- 配置提取:根据输入路径判断是
.py文件还是包含pyproject.toml的目录,并生成PyProjectConfig对象。 - 默认命名:若无
pyproject.toml,则使用文件夹名或.py文件名作为项目名称。 - TOML 解析:通过
load_pyproject_settings解析 TOML 内容为结构化数据。 - 环境验证:提供
validate_and_extract_os_classifiers和validate_and_extract_accelerator_classifiers用于验证操作系统与加速器支持信息。
关键函数
def extract_node_configuration(path) -> Optional[PyProjectConfig]:
if os.path.isfile(path):
file_path = Path(path)
if file_path.suffix.lower() != '.py':
return None
project_name = file_path.stem
project = ProjectConfig(name=project_name)
comfy = ComfyConfig()
return PyProjectConfig(project=project, tool_comfy=comfy)
folder_name = os.path.basename(path)
toml_path = Path(path) / "pyproject.toml"
if not toml_path.exists():
project = ProjectConfig(name=folder_name)
comfy = ComfyConfig()
return PyProjectConfig(project=project, tool_comfy=comfy)
raw_settings = load_pyproject_settings(toml_path)
project_data = raw_settings.project
tool_data = raw_settings.tool
comfy_data = tool_data.get("comfy", {}) if tool_data else {}
dependencies = project_data.get("dependencies", [])
supported_comfyui_frontend_version = ""
for dep in dependencies:
if isinstance(dep, str) and dep.startswith("comfyui-frontend-package"):
supported_comfyui_frontend_version = dep.removeprefix("comfyui-frontend-package")
break
supported_comfyui_version = comfy_data.get("requires-comfyui", "")
classifiers = project_data.get('classifiers', [])
supported_os = validate_and_extract_os_classifiers(classifiers)
supported_accelerators = validate_and_extract_accelerator_classifiers(classifiers)
project_data['supported_os'] = supported_os
project_data['supported_accelerators'] = supported_accelerators
project_data['supported_comfyui_frontend_version'] = supported_comfyui_frontend_version
project_data['supported_comfyui_version'] = supported_comfyui_version
return PyProjectConfig(project=project_data, tool_comfy=comfy_data)def load_pyproject_settings(toml_path: Path) -> PyProjectSettings:
class PyProjectLoader(PyProjectSettings):
@classmethod
def settings_customise_sources(
cls,
settings_cls,
init_settings: PydanticBaseSettingsSource,
env_settings: PydanticBaseSettingsSource,
dotenv_settings: PydanticBaseSettingsSource,
file_secret_settings: PydanticBaseSettingsSource,
):
return (TomlConfigSettingsSource(settings_cls, toml_path),)
return PyProjectLoader()def validate_and_extract_os_classifiers(classifiers: list) -> list:
os_classifiers = [c for c in classifiers if c.startswith("Operating System :: ")]
if not os_classifiers:
return []
os_values = [c[len("Operating System :: ") :] for c in os_classifiers]
valid_os_prefixes = {"Microsoft", "POSIX", "MacOS", "OS Independent"}
for os_value in os_values:
if not any(os_value.startswith(prefix) for prefix in valid_os_prefixes):
return []
return os_valuesdef validate_and_extract_accelerator_classifiers(classifiers: list) -> list:
accelerator_classifiers = [c for c in classifiers if c.startswith("Environment ::")]
if not accelerator_classifiers:
return []
accelerator_values = [c[len("Environment :: ") :] for c in accelerator_classifiers]
valid_accelerators = {
"GPU :: NVIDIA CUDA",
"GPU :: AMD ROCm",
"GPU :: Intel Arc",
"NPU :: Huawei Ascend",
"GPU :: Apple Metal",
}
for accelerator_value in accelerator_values:
if accelerator_value not in valid_accelerators:
return []
return accelerator_values数据模型 (types.py)
types.py 定义了多个 Pydantic 模型类,用于数据校验与序列化。
主要类
NodeVersion: 描述节点版本信息。Node: 表示自定义节点元数据。PublishNodeVersionResponse: 发布后的响应模型。URLs: 项目相关链接。Model: 模型路径配置。ComfyConfig: ComfyUI 特定配置。License: 许可证信息。ProjectConfig: 项目基本信息。PyProjectConfig: 完整项目配置对象。PyProjectSettings: TOML 解析后的设置。
示例模型结构
class PyProjectConfig(BaseModel):
project: ProjectConfig
comfy_config: ComfyConfig
...流程图
以下流程图展示了配置模块的工作流程:
数据模型表
| 类名 | 描述 |
|---|---|
NodeVersion | 节点版本信息 |
Node | 自定义节点元数据 |
PublishNodeVersionResponse | 发布后的响应模型 |
URLs | 项目相关链接 |
Model | 模型路径配置 |
ComfyConfig | ComfyUI 特定配置 |
License | 许可证信息 |
ProjectConfig | 项目基本信息 |
PyProjectConfig | 完整项目配置对象 |
PyProjectSettings | TOML 解析后的设置 |
总结
配置模块通过解析 .py 文件或 pyproject.toml 提供了灵活且结构化的配置管理方式。它不仅支持项目元数据的提取,还通过验证函数确保环境兼容性。该模块为 ComfyUI 的 CLI 工具和注册表系统提供了可靠的数据基础,是自定义节点生态系统中不可或缺的一部分。通过 extract_node_configuration 函数,模块能够根据输入路径自动判断配置来源并生成相应的配置对象,同时通过 validate_and_extract_os_classifiers 和 validate_and_extract_accelerator_classifiers 函数确保配置的环境兼容性。
自定义节点模块
自定义节点模块是 ComfyUI 项目中用于扩展图像处理工作流功能的关键部分。通过定义特定的节点类,开发者可以实现图像处理、数据传输及其他自定义逻辑。该模块主要包括两个示例节点:Example 和 SaveImageWebsocket,分别用于演示节点基本结构和通过 WebSocket 实时传输图像。
示例节点 Example
功能概述
Example 节点类位于 custom_nodes/example_node.py.example 文件中,旨在展示如何构建一个基本的自定义节点。它接收图像和多种输入参数,并根据配置决定是否打印信息到控制台。其核心方法 test 对图像进行简单处理(如反色操作),并返回处理后的图像。
关键组件
- 类方法
INPUT_TYPES:定义节点的输入字段及其类型与配置,支持懒加载机制。 - 方法
check_lazy_status:用于动态判断哪些字段需要延迟评估。 - 输出类型:节点输出为一个图像元组(
RETURN_TYPES = ("IMAGE",)),属于实验性或示例性质。 - Web API 路由:注册了一个简单的 Web API 路由
/hello,返回"hello"响应。 - 节点映射:通过
NODE_CLASS_MAPPINGS和NODE_DISPLAY_NAME_MAPPINGS将节点映射到系统中。
类定义
class Example:
def __init__(self):
pass输入类型定义
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"image": ("IMAGE",),
"int_field": ("INT", {
"default": 0,
"min": 0,
"max": 4096,
"step": 64,
"display": "number",
"lazy": True
}),
"float_field": ("FLOAT", {
"default": 1.0,
"min": 0.0,
"max": 10.0,
"step": 0.01,
"round": 0.001,
"display": "number",
"lazy": True
}),
"print_to_screen": (["enable", "disable"],),
"string_field": ("STRING", {
"multiline": False,
"default": "Hello World!",
"lazy": True
}),
},
}懒加载状态检查
def check_lazy_status(self, image, string_field, int_field, float_field, print_to_screen):
if print_to_screen == "enable":
return ["int_field", "float_field", "string_field"]
else:
return []核心处理方法
def test(self, image, string_field, int_field, float_field, print_to_screen):
if print_to_screen == "enable":
print(f"""Your input contains:
string_field aka input text: {string_field}
int_field: {int_field}
float_field: {float_field}
""")
#do some processing on the image, in this example I just invert it
image = 1.0 - image
return (image,)节点注册
NODE_CLASS_MAPPINGS = {
"Example": Example
}
NODE_DISPLAY_NAME_MAPPINGS = {
"Example": "Example Node"
}Web API 路由
from aiohttp import web
from server import PromptServer
@PromptServer.instance.routes.get("/hello")
async def get_hello(request):
return web.json_response("hello")流程图
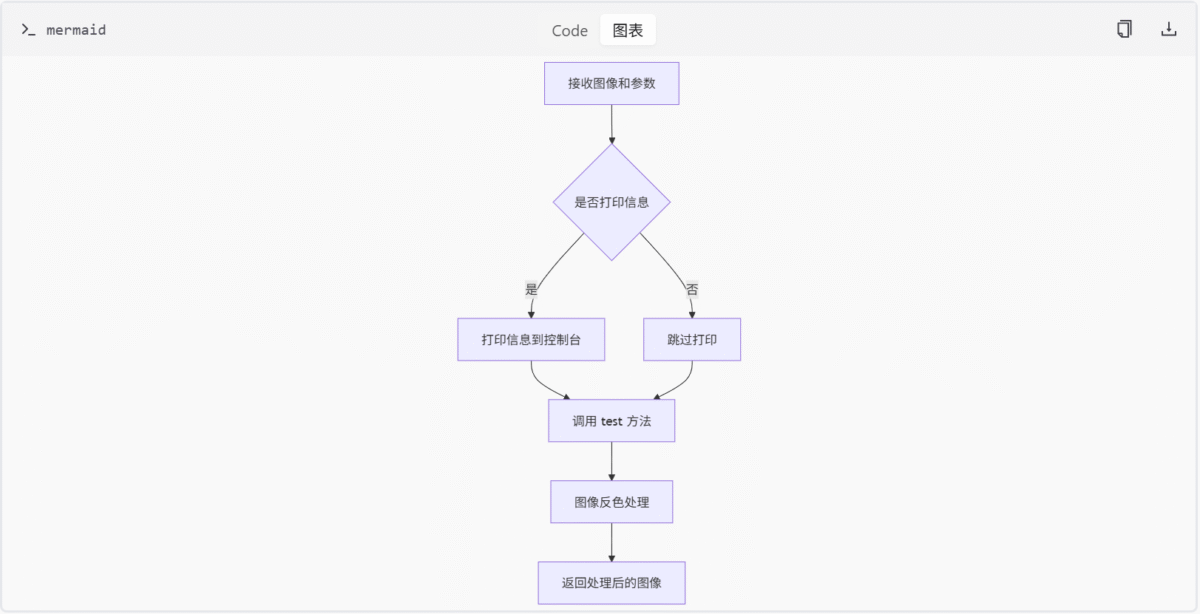
主要功能表
| 功能/组件 | 描述 |
|---|---|
INPUT_TYPES | 定义输入字段及其类型与配置,支持懒加载机制 |
check_lazy_status | 动态判断哪些字段需要延迟评估 |
test 方法 | 对图像进行简单处理(如反色操作) |
| 输出类型 | 返回一个图像元组(IMAGE) |
| Web API 路由 | 注册 /hello 路由,返回 "hello" 响应 |
WebSocket 图像保存节点 SaveImageWebsocket
功能概述
SaveImageWebsocket 节点类位于 custom_nodes/websocket_image_save.py 文件中,用于通过 WebSocket 接口保存图像。该节点接收输入的图像数据(格式为 IMAGE),并将其转换为 PNG 格式的 PIL 图像对象。在处理过程中,使用 comfy.utils.ProgressBar 更新进度条,并将每张图像以二进制形式发送到 WebSocket。该节点不返回任何输出值,主要用于图像的实时传输或调试用途。
关键组件
- 输入类型:接收图像数据(格式为
IMAGE)。 - 图像处理:将图像转换为 PNG 格式的 PIL 图像对象。
- 进度条更新:使用
comfy.utils.ProgressBar更新进度条。 - WebSocket 传输:将图像以二进制形式发送到 WebSocket。
- 无输出:该节点不返回任何输出值。
类定义
class SaveImageWebsocket:
def __init__(self):
self.type = "output"输入类型定义
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"images": ("IMAGE",),
}
}返回类型定义
RETURN_TYPES = ()
OUTPUT_NODE = True核心处理方法
def save_images(self, images):
from PIL import Image
from io import BytesIO
import base64
# Get the prompt server instance
from server import PromptServer
server = PromptServer.instance
# Create progress bar
from comfy.utils import ProgressBar
pbar = ProgressBar(len(images))
for i, image in enumerate(images):
# Convert tensor to PIL image
i = 255. * image.cpu().numpy()
img = Image.fromarray(np.clip(i, 0, 255).astype(np.uint8))
# Convert to bytes
buffer = BytesIO()
img.save(buffer, format="PNG")
image_bytes = buffer.getvalue()
# Send to websocket
server.send_sync("websocket_image_save", {
"image_data": base64.b64encode(image_bytes).decode('utf-8')
})
# Update progress bar
pbar.update(1)
return ()节点注册
NODE_CLASS_MAPPINGS = {
"SaveImageWebsocket": SaveImageWebsocket
}
NODE_DISPLAY_NAME_MAPPINGS = {
"SaveImageWebsocket": "Save Image (WebSocket)"
}流程图
主要功能表
| 功能/组件 | 描述 |
|---|---|
| 输入类型 | 接收图像数据(格式为 IMAGE) |
| 图像处理 | 将图像转换为 PNG 格式的 PIL 图像对象 |
| 进度条更新 | 使用 comfy.utils.ProgressBar 更新进度条 |
| WebSocket 传输 | 将图像以二进制形式发送到 WebSocket |
| 输出 | 无输出 |
总结
自定义节点模块通过 Example 和 SaveImageWebsocket 两个节点类,展示了如何在 ComfyUI 中扩展图像处理工作流。Example 节点提供了基本的节点结构和处理逻辑,而 SaveImageWebsocket 节点则专注于通过 WebSocket 实时传输图像。这些节点为开发者提供了构建更复杂图像处理流程的基础。
本网站提供的所有AI生成内容均基于人工智能技术和大语言模型算法,根据用户输入指令自动生成。生成内容不代表本网站观点,亦不构成任何形式的专业建议。本公司对生成内容的准确性、完整性、适用性及合法性不作明示或默示的保证,用户应对生成内容自行判断并承担全部使用风险。